Deep Learning
Hugging Face Benchmarks - Natural Language Processing for PyTorch
January 26, 2022
13 min read


The following performance benchmarks were performed using the Hugging Face AI community Benchmark Suite. The benchmark uses Transformer Models for NLP using libraries from the Hugging Face ecosystem. For more information visit the Hugging Face website.
NLP is a field of linguistics and machine learning focused on understanding everything related to human language. The aim of NLP tasks is not only to understand single words individually, but to be able to understand the context of those words through speech and/or text.
Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provide general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability using PyTorch.
Transformers provide thousands of pretrained models to perform tasks on texts such as classification, information extraction, question answering, summarization, translation, text generation and more in over 100 languages. The aim is to make cutting-edge NLP easier to use for everyone.
Transformers provide APIs to quickly download and use those pretrained models on a given text, fine-tune them on your own datasets and then share them with the community on their model hub. At the same time, each python module defining an architecture is fully standalone and can be modified to enable quick research experiments.
Transformers are backed by the three most popular deep learning libraries: Jax, PyTorch and TensorFlow, with a seamless integration between them. It's straightforward to train models with one before loading them for inference with the other.
In the following benchmarks we ran, PyTorch was used.
While Hugging Face does offer tiered pricing options for access to premium AutoNLP capabilities and an accelerated inference application programming interface (API), basic access to the inference API is included in the free tier and their core NLP libraries (transformers, tokenizers, datasets, and accelerate) are developed in the open and freely available under an Apache 2.0 License.
Exxact Workstation System Specs:
| Nodes | 1 |
| Processor / Count | 1x AMD Ryzen Threadripper 3960X 24-Core Processor |
| Total Logical Cores | 48 |
| Memory | DDR4 128 GB |
| Storage | NVMe 3.7T /data |
| OS | Ubuntu 20.04 |
| CUDA Version | 11.3 |
| PyTorch Version | 3.8.10 |
Interested in a deep learning workstation that can handle NLP training?
Learn more about Exxact AI workstations starting around $5,500
Hereby, inference is defined by a single forward pass, and training is defined by a single forward pass and backward pass. Three arguments are given to the benchmark argument data classes, namely models, batch_sizes, and sequence_lengths. Bydefault, the time and the required memory for inference are benchmarked.
In the following examples output above the first two sections show the result corresponding to inference time and inference memory. In addition, all relevant information about the computing environment, e.g. the GPU type, the system, the library versions, etc.
For more information visit: https://github.com/huggingface
| 3060Ti | 3070 | 3080 | 3090 |
|---|---|---|---|
| transformers_version,4.11.3 framework,PyTorch use_torchscript,False framework_version,1.9.0+cu111 python_version,3.8.10 system,Linux cpu,x86_64 architecture,64bit date,2021-11-17 time,14:36:02.274199 fp16,False use_multiprocessing,True only_pretrain_model,False cpu_ram_mb,128747 use_gpu,True num_gpus,1 gpu,NVIDIA GeForce RTX 3060 Ti gpu_ram_mb,7979 gpu_power_watts,200.0 gpu_performance_state,0 use_tpu,False | transformers_version,4.11.3 framework,PyTorch use_torchscript,False framework_version,1.9.0+cu111 python_version,3.8.10 system,Linux cpu,x86_64 architecture,64bit date,2021-10-28 time,11:46:55.409272 fp16,False use_multiprocessing,True only_pretrain_model,False cpu_ram_mb,128747 use_gpu,True num_gpus,1 gpu,NVIDIA RTX 3070 gpu_ram_mb,7979 gpu_power_watts,220.0 gpu_performance_state,0 use_tpu,False | transformers_version,4.11.3 framework,PyTorch use_torchscript,False framework_version,1.9.0+cu111 python_version,3.8.10 system,Linux cpu,x86_64 architecture,64bit date,2021-10-28 time,10:53:02.353928 fp16,False use_multiprocessing,True only_pretrain_model,False cpu_ram_mb,128747 use_gpu,True num_gpus,1 gpu,NVIDIA RTX 3080 gpu_ram_mb,10010 gpu_power_watts,320.0 gpu_performance_state,0 use_tpu,False | transformers_version,4.11.3 framework,PyTorch use_torchscript,False framework_version,1.9.0+cu111 python_version,3.8.10 system,Linux cpu,x86_64 architecture,64bit date,2021-10-14 time,14:15:11.014509 fp16,False use_multiprocessing,True only_pretrain_model,False cpu_ram_mb,128747 use_gpu,True num_gpus,1 gpu,NVIDIA RTX 3090 gpu_ram_mb,24260 gpu_power_watts,350.0 gpu_performance_state,0 use_tpu,False |
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this paper and first released in this repository. This model is uncased: it does not make a difference between english and English.
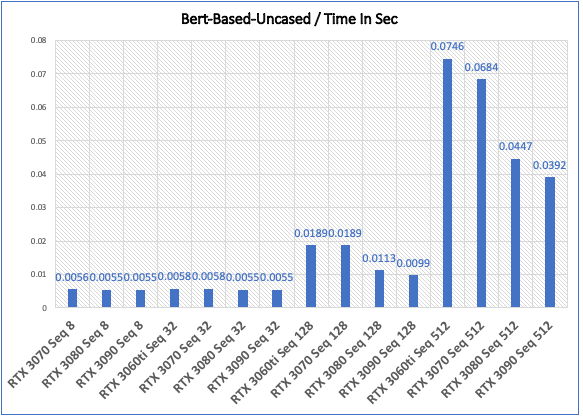
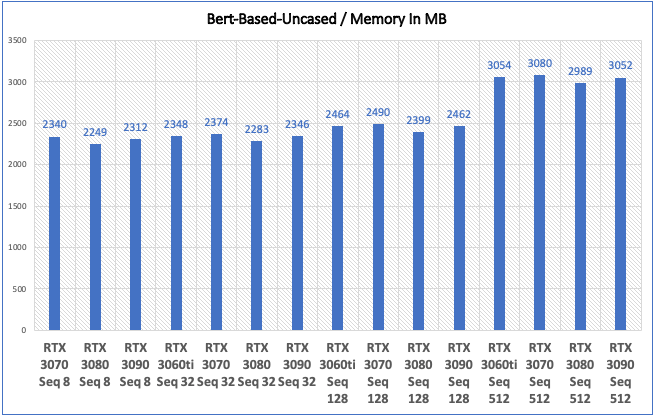
Inference - Speed and Memory Results
| GPU Type | Time In Sec | Memory In MB |
|---|---|---|
| NVIDIA RTX 3070 Seq 8 | 0.0056 | 2340 |
| NVIDIA RTX 3080 Seq 8 | 0.0055 | 2249 |
| NVIDIA RTX 3090 Seq 8 | 0.0055 | 2312 |
| NVIDIA RTX 3070 Seq 32 | 0.0058 | 2374 |
| NVIDIA RTX 3080 Seq 32 | 0.0055 | 2283 |
| NVIDIA RTX 3090 Seq 32 | 0.0055 | 2346 |
| NVIDIA RTX 3070 Seq 128 | 0.0189 | 2490 |
| NVIDIA RTX 3080 Seq 128 | 0.0113 | 2399 |
| NVIDIA RTX 3090 Seq 128 | 0.0099 | 2462 |
| NVIDIA RTX 3070 Seq 512 | 0.0684 | 3080 |
| NVIDIA RTX 3080 Seq 512 | 0.0447 | 2989 |
| NVIDIA RTX 3090 Seq 512 | 0.0392 | 3052 |
Benchmark Notes
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this paper and first released in this repository. This model is case-sensitive: it makes a difference between english and English.
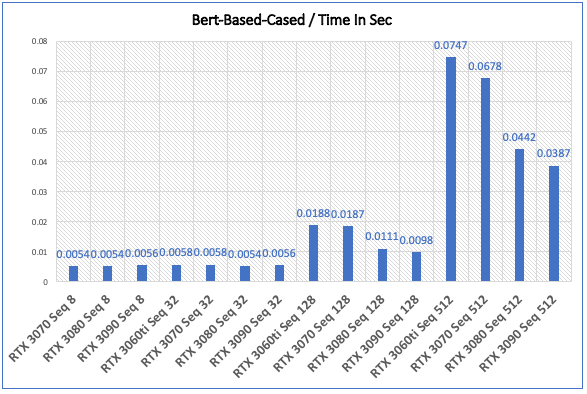
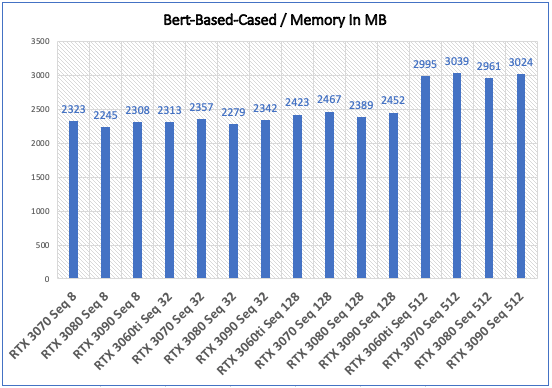
Inference - Speed and Memory Results
| GPU Type | Time In Sec | Memory In MB |
|---|---|---|
| NVIDIA RTX 3070 Seq 8 | 0.0054 | 2323 |
| NVIDIA RTX 3070 Seq 32 | 0.0058 | 2357 |
| NVIDIA RTX 3070 Seq 128 | 0.0187 | 2467 |
| NVIDIA RTX 3070 Seq 512 | 0.0678 | 3039 |
| NVIDIA RTX 3080 Seq 8 | 0.0054 | 2245 |
| NVIDIA RTX 3080 Seq 32 | 0.0054 | 2279 |
| NVIDIA RTX 3080 Seq 128 | 0.0111 | 2389 |
| NVIDIA RTX 3080 Seq 512 | 0.0442 | 2961 |
| NVIDIA RTX 3090 Seq 8 | 0.0056 | 2308 |
| NVIDIA RTX 3090 Seq 32 | 0.0056 | 2342 |
| NVIDIA RTX 3090 Seq 128 | 0.0098 | 2452 |
| NVIDIA RTX 3090 Seq 512 | 0.0387 | 3024 |
Benchmark Notes
Pretrained model on English language using a causal language modeling (CLM) objective.
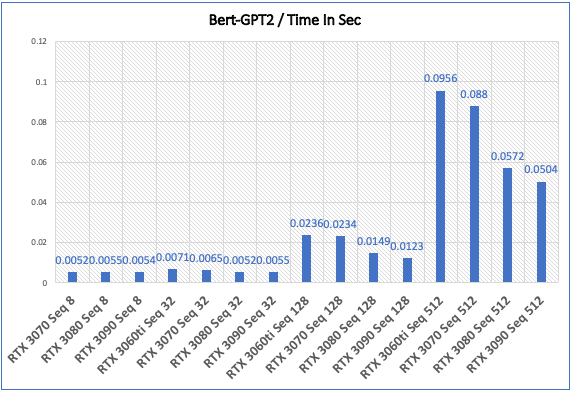
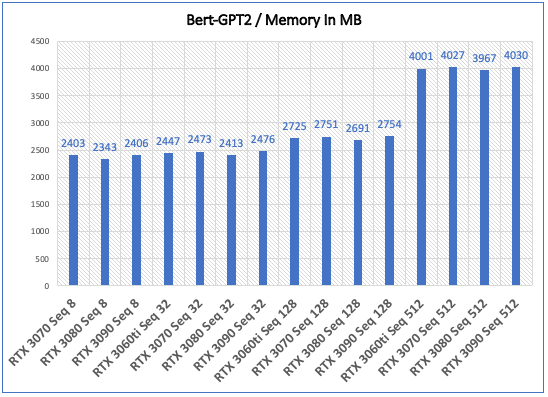
Inference - Speed and Memory Results
| GPU Type | Time In Sec | Memory In MB |
|---|---|---|
| NVIDIA RTX 3070 Seq 8 | 0.0052 | 2403 |
| NVIDIA RTX 3080 Seq 8 | 0.0055 | 2343 |
| NVIDIA RTX 3090 Seq 8 | 0.0054 | 2406 |
| NVIDIA RTX 3070 Seq 32 | 0.0065 | 2473 |
| NVIDIA RTX 3080 Seq 32 | 0.0052 | 2413 |
| NVIDIA RTX 3090 Seq 32 | 0.0055 | 2476 |
| NVIDIA RTX 3070 Seq 128 | 0.0234 | 2751 |
| NVIDIA RTX 3080 Seq 128 | 0.0149 | 2691 |
| NVIDIA RTX 3090 Seq 128 | 0.0123 | 2754 |
| NVIDIA RTX 3070 Seq 512 | 0.088 | 4027 |
| NVIDIA RTX 3080 Seq 512 | 0.0572 | 3967 |
| NVIDIA RTX 3090 Seq 512 | 0.0504 | 4030 |
Benchmark Notes
| NVIDIA RTX 3060 Ti | NVIDIA RTX 3070 | NVIDIA RTX 3080 | NVIDIA RTX 3090 | |
| NVIDIA CUDA Cores | 4864 | 5,888 | 8,704 | 10,496 |
| Boost Clock (GHz) | 1.67 | 1.73 | 1.71 | 1.70 |
| Memory Size | 8GB | 8 GB | 10 GB | 24 GB |
| Memory Type | GDDR6 | GDDR6 | GDDR6X | GDDR6X |
| Dimensions | 9.5 x 4.4 inches | 9.5 x 4.4 inches | 11.2 x 4.4 inches | 12.3 x 5.4 inches |
| Power Draw | 200W | 220W | 320W | 350W |
Have any questions?
The following performance benchmarks were performed using the Hugging Face AI community Benchmark Suite. The benchmark uses Transformer Models for NLP using libraries from the Hugging Face ecosystem. For more information visit the Hugging Face website.
NLP is a field of linguistics and machine learning focused on understanding everything related to human language. The aim of NLP tasks is not only to understand single words individually, but to be able to understand the context of those words through speech and/or text.
Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provide general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability using PyTorch.
Transformers provide thousands of pretrained models to perform tasks on texts such as classification, information extraction, question answering, summarization, translation, text generation and more in over 100 languages. The aim is to make cutting-edge NLP easier to use for everyone.
Transformers provide APIs to quickly download and use those pretrained models on a given text, fine-tune them on your own datasets and then share them with the community on their model hub. At the same time, each python module defining an architecture is fully standalone and can be modified to enable quick research experiments.
Transformers are backed by the three most popular deep learning libraries: Jax, PyTorch and TensorFlow, with a seamless integration between them. It's straightforward to train models with one before loading them for inference with the other.
In the following benchmarks we ran, PyTorch was used.
While Hugging Face does offer tiered pricing options for access to premium AutoNLP capabilities and an accelerated inference application programming interface (API), basic access to the inference API is included in the free tier and their core NLP libraries (transformers, tokenizers, datasets, and accelerate) are developed in the open and freely available under an Apache 2.0 License.
Exxact Workstation System Specs:
| Nodes | 1 |
| Processor / Count | 1x AMD Ryzen Threadripper 3960X 24-Core Processor |
| Total Logical Cores | 48 |
| Memory | DDR4 128 GB |
| Storage | NVMe 3.7T /data |
| OS | Ubuntu 20.04 |
| CUDA Version | 11.3 |
| PyTorch Version | 3.8.10 |
Interested in a deep learning workstation that can handle NLP training?
Learn more about Exxact AI workstations starting around $5,500
Hereby, inference is defined by a single forward pass, and training is defined by a single forward pass and backward pass. Three arguments are given to the benchmark argument data classes, namely models, batch_sizes, and sequence_lengths. Bydefault, the time and the required memory for inference are benchmarked.
In the following examples output above the first two sections show the result corresponding to inference time and inference memory. In addition, all relevant information about the computing environment, e.g. the GPU type, the system, the library versions, etc.
For more information visit: https://github.com/huggingface
| 3060Ti | 3070 | 3080 | 3090 |
|---|---|---|---|
| transformers_version,4.11.3 framework,PyTorch use_torchscript,False framework_version,1.9.0+cu111 python_version,3.8.10 system,Linux cpu,x86_64 architecture,64bit date,2021-11-17 time,14:36:02.274199 fp16,False use_multiprocessing,True only_pretrain_model,False cpu_ram_mb,128747 use_gpu,True num_gpus,1 gpu,NVIDIA GeForce RTX 3060 Ti gpu_ram_mb,7979 gpu_power_watts,200.0 gpu_performance_state,0 use_tpu,False | transformers_version,4.11.3 framework,PyTorch use_torchscript,False framework_version,1.9.0+cu111 python_version,3.8.10 system,Linux cpu,x86_64 architecture,64bit date,2021-10-28 time,11:46:55.409272 fp16,False use_multiprocessing,True only_pretrain_model,False cpu_ram_mb,128747 use_gpu,True num_gpus,1 gpu,NVIDIA RTX 3070 gpu_ram_mb,7979 gpu_power_watts,220.0 gpu_performance_state,0 use_tpu,False | transformers_version,4.11.3 framework,PyTorch use_torchscript,False framework_version,1.9.0+cu111 python_version,3.8.10 system,Linux cpu,x86_64 architecture,64bit date,2021-10-28 time,10:53:02.353928 fp16,False use_multiprocessing,True only_pretrain_model,False cpu_ram_mb,128747 use_gpu,True num_gpus,1 gpu,NVIDIA RTX 3080 gpu_ram_mb,10010 gpu_power_watts,320.0 gpu_performance_state,0 use_tpu,False | transformers_version,4.11.3 framework,PyTorch use_torchscript,False framework_version,1.9.0+cu111 python_version,3.8.10 system,Linux cpu,x86_64 architecture,64bit date,2021-10-14 time,14:15:11.014509 fp16,False use_multiprocessing,True only_pretrain_model,False cpu_ram_mb,128747 use_gpu,True num_gpus,1 gpu,NVIDIA RTX 3090 gpu_ram_mb,24260 gpu_power_watts,350.0 gpu_performance_state,0 use_tpu,False |
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this paper and first released in this repository. This model is uncased: it does not make a difference between english and English.
Inference - Speed and Memory Results
| GPU Type | Time In Sec | Memory In MB |
|---|---|---|
| NVIDIA RTX 3070 Seq 8 | 0.0056 | 2340 |
| NVIDIA RTX 3080 Seq 8 | 0.0055 | 2249 |
| NVIDIA RTX 3090 Seq 8 | 0.0055 | 2312 |
| NVIDIA RTX 3070 Seq 32 | 0.0058 | 2374 |
| NVIDIA RTX 3080 Seq 32 | 0.0055 | 2283 |
| NVIDIA RTX 3090 Seq 32 | 0.0055 | 2346 |
| NVIDIA RTX 3070 Seq 128 | 0.0189 | 2490 |
| NVIDIA RTX 3080 Seq 128 | 0.0113 | 2399 |
| NVIDIA RTX 3090 Seq 128 | 0.0099 | 2462 |
| NVIDIA RTX 3070 Seq 512 | 0.0684 | 3080 |
| NVIDIA RTX 3080 Seq 512 | 0.0447 | 2989 |
| NVIDIA RTX 3090 Seq 512 | 0.0392 | 3052 |
Benchmark Notes
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this paper and first released in this repository. This model is case-sensitive: it makes a difference between english and English.
Inference - Speed and Memory Results
| GPU Type | Time In Sec | Memory In MB |
|---|---|---|
| NVIDIA RTX 3070 Seq 8 | 0.0054 | 2323 |
| NVIDIA RTX 3070 Seq 32 | 0.0058 | 2357 |
| NVIDIA RTX 3070 Seq 128 | 0.0187 | 2467 |
| NVIDIA RTX 3070 Seq 512 | 0.0678 | 3039 |
| NVIDIA RTX 3080 Seq 8 | 0.0054 | 2245 |
| NVIDIA RTX 3080 Seq 32 | 0.0054 | 2279 |
| NVIDIA RTX 3080 Seq 128 | 0.0111 | 2389 |
| NVIDIA RTX 3080 Seq 512 | 0.0442 | 2961 |
| NVIDIA RTX 3090 Seq 8 | 0.0056 | 2308 |
| NVIDIA RTX 3090 Seq 32 | 0.0056 | 2342 |
| NVIDIA RTX 3090 Seq 128 | 0.0098 | 2452 |
| NVIDIA RTX 3090 Seq 512 | 0.0387 | 3024 |
Benchmark Notes
Pretrained model on English language using a causal language modeling (CLM) objective.
Inference - Speed and Memory Results
| GPU Type | Time In Sec | Memory In MB |
|---|---|---|
| NVIDIA RTX 3070 Seq 8 | 0.0052 | 2403 |
| NVIDIA RTX 3080 Seq 8 | 0.0055 | 2343 |
| NVIDIA RTX 3090 Seq 8 | 0.0054 | 2406 |
| NVIDIA RTX 3070 Seq 32 | 0.0065 | 2473 |
| NVIDIA RTX 3080 Seq 32 | 0.0052 | 2413 |
| NVIDIA RTX 3090 Seq 32 | 0.0055 | 2476 |
| NVIDIA RTX 3070 Seq 128 | 0.0234 | 2751 |
| NVIDIA RTX 3080 Seq 128 | 0.0149 | 2691 |
| NVIDIA RTX 3090 Seq 128 | 0.0123 | 2754 |
| NVIDIA RTX 3070 Seq 512 | 0.088 | 4027 |
| NVIDIA RTX 3080 Seq 512 | 0.0572 | 3967 |
| NVIDIA RTX 3090 Seq 512 | 0.0504 | 4030 |
Benchmark Notes
| NVIDIA RTX 3060 Ti | NVIDIA RTX 3070 | NVIDIA RTX 3080 | NVIDIA RTX 3090 | |
| NVIDIA CUDA Cores | 4864 | 5,888 | 8,704 | 10,496 |
| Boost Clock (GHz) | 1.67 | 1.73 | 1.71 | 1.70 |
| Memory Size | 8GB | 8 GB | 10 GB | 24 GB |
| Memory Type | GDDR6 | GDDR6 | GDDR6X | GDDR6X |
| Dimensions | 9.5 x 4.4 inches | 9.5 x 4.4 inches | 11.2 x 4.4 inches | 12.3 x 5.4 inches |
| Power Draw | 200W | 220W | 320W | 350W |
Have any questions?
