Deep Learning
LM Studio - Run Generative AI on Your Own Machine
July 18, 2024
6 min read


The emergence of Large Language Models (LLMs) has brought a significant advancement in natural language processing, enabling machines to better understand and interact with humans. Among these, open-source models like Mistral 7B stand out, offering a foundation for various applications. Platforms like Hugging Face further enrich the ecosystem by fostering collaboration and sharing of models and resources among the machine learning community. Additionally, software like LM Studio has emerged to bridge the gap between these complex models and everyday users, allowing the power of LLMs to be harnessed right from one’s own computer. Together, LM Studio, Hugging Face, and open-source models like Mistral 7B are making strides towards democratizing access to advanced language processing capabilities.
Large language models (LLMs) are like big virtual brains that learn from tons of written material. They are built using special computer programs that can understand and work with sequences, which is important for dealing with language. Training these models is a heavy-duty task, needing powerful computers often spread across different locations to handle the large amount of information and the intricate web of connections within the model. They learn from a wide variety of texts like books, articles, websites, and social media posts, which helps them understand and mimic the way humans use language.
As they go through all this data, they learn to recognize patterns and the ways words relate to each other, allowing them to create sensible and relevant text. They even try to catch on to the finer shades of language like tone and sentiment, but despite their cleverness, they don't truly understand language or have awareness like humans do.
LM Studio emerges as a software between users and the vast potential of LLMs. This downloadable software handles the complexities of running large language models on your local machine, with a focus on open-source models free for public use. With LM Studio, switching between different language models is a breeze, thanks to its user-friendly interface that simplifies the downloading process, inviting users into a seamless dialogue with these digital entities.
Download it here: https://lmstudio.ai/
Hugging Face is a platform where the machine learning community collaborates on models, datasets, and applications. It's a hub for creating, discovering, and collaborating on machine learning projects, with a focus on text, among other modalities like images and videos
Start with picking a base model Mistral 7B, which is already trained to handle general tasks in your area of interest. It's one of many models you can try out.
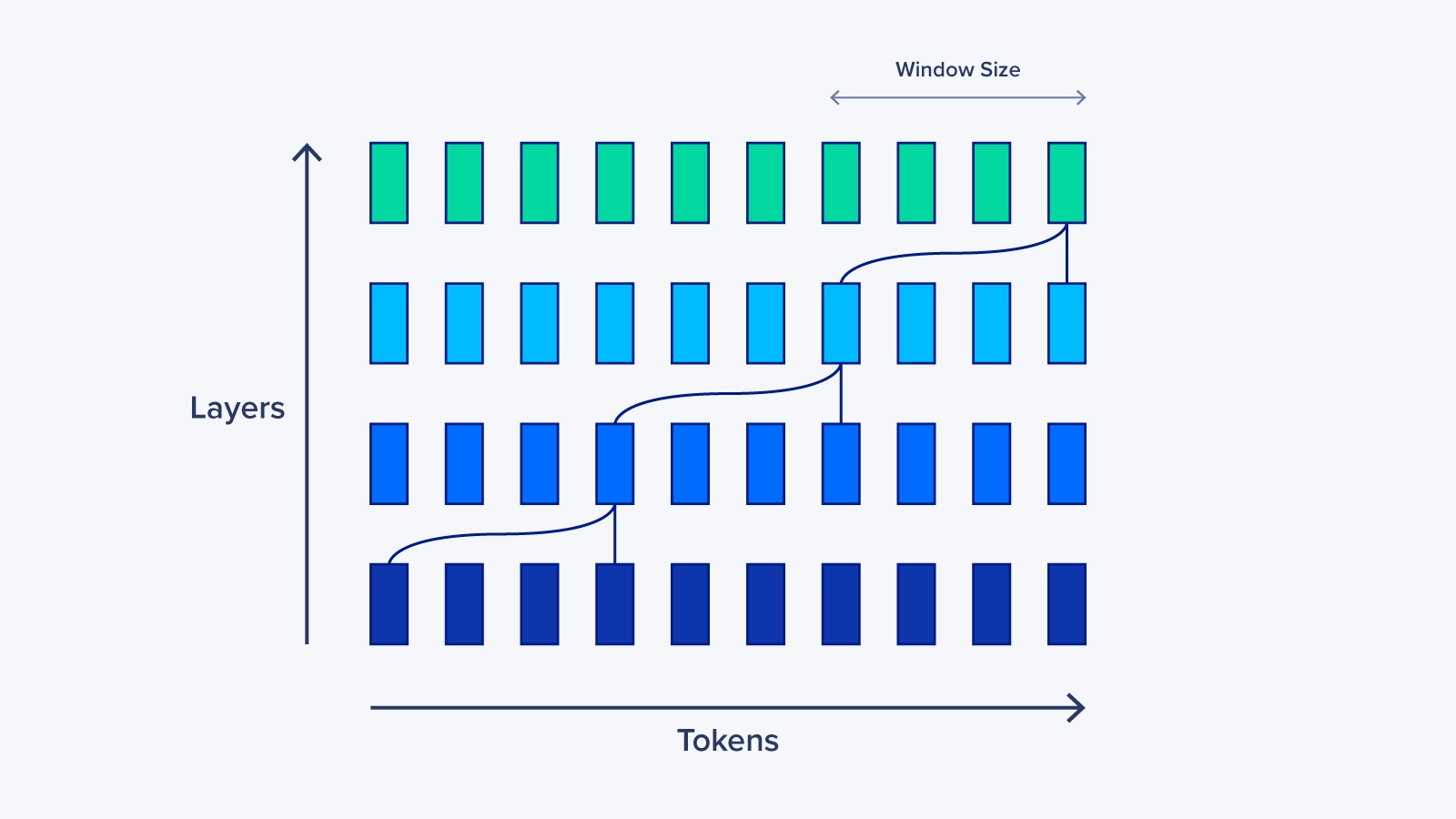
In handling a long list of data, like a very long sentence, the computer employs a technique called Sliding Window Attention (SWA), which acts like a small spotlight moving along the sentence, allowing the computer to focus on a few words at a time instead of the whole sentence. This spotlight technique, along with some other adjustments, makes the process twice as fast when dealing with very long sentences. Even with this small spotlight, the computer can understand connections between words that are far apart in the sentence by passing information from one stage to the next, similar to passing notes in a classroom. Additionally, the SWA helps in using less memory, akin to needing a smaller notebook for jotting down notes, which is beneficial when dealing with long sentences.
Gather your data and start fine-tuning the model. Make sure your data is clean and ready for training. Then, fine-tune Mistral 7B using your data by running more training rounds, starting with the pre-set settings of the model. You might need to tweak or add some parts of the model to make it work better for your task. There are other versions of Mistral 7B that have been fine-tuned by others which might be helpful or interesting for your project. This way, you get a structured way to adapt a ready-made model for your specific needs while also checking out what others have done.
Link to: OpenHermes 2 - Mistral 7B and Mistral-7B-OpenOrca
You can also augment your prompts utilizing a hot new method for prompt engineering called RAG or retrieval augmented generation. Fetch important and relevant data from PDFs, text files, etc. based on the prompt to augment our prompt with context.
By granting the prompt and the AI context, we can get even more accurate responses from our local model which is especially important when running smaller models like Mistral 7B. Learn more about RAG here.
It is important to keep in mind that RAG does not solve the common LLM pitfalls like hallucination and serves as a means to guide your LLM to a more niche response. The endpoints that ultimately matter, are specific to your use case, the information you feed your model, and how the model is fine-tuned.
Mistral 7B being licensed under Apache 2.0 means that it is open-source, and you can freely use, modify, and distribute it. The Apache 2.0 License also provides a grant of patent rights from contributors to users, which is beneficial in reducing legal risks. This licensing allows developers and organizations to collaboratively work on and share the model, promoting open collaboration and innovation.
The practical applications of engaging with LLMs through LM Studio are limited only by imagination. For instance, users can develop a conversational knowledge base assistant and utilize their model as a companion for learning and mastering new programming languages. They can identify intricate coding queries, offer detailed explanations of algorithms, or debug in real-time—transforming code exploration into a dynamic, responsive, and interactive learning experience.
If you have any questions about Large Language Models and how to train and run them, contact Exxact Today.
The emergence of Large Language Models (LLMs) has brought a significant advancement in natural language processing, enabling machines to better understand and interact with humans. Among these, open-source models like Mistral 7B stand out, offering a foundation for various applications. Platforms like Hugging Face further enrich the ecosystem by fostering collaboration and sharing of models and resources among the machine learning community. Additionally, software like LM Studio has emerged to bridge the gap between these complex models and everyday users, allowing the power of LLMs to be harnessed right from one’s own computer. Together, LM Studio, Hugging Face, and open-source models like Mistral 7B are making strides towards democratizing access to advanced language processing capabilities.
Large language models (LLMs) are like big virtual brains that learn from tons of written material. They are built using special computer programs that can understand and work with sequences, which is important for dealing with language. Training these models is a heavy-duty task, needing powerful computers often spread across different locations to handle the large amount of information and the intricate web of connections within the model. They learn from a wide variety of texts like books, articles, websites, and social media posts, which helps them understand and mimic the way humans use language.
As they go through all this data, they learn to recognize patterns and the ways words relate to each other, allowing them to create sensible and relevant text. They even try to catch on to the finer shades of language like tone and sentiment, but despite their cleverness, they don't truly understand language or have awareness like humans do.
LM Studio emerges as a software between users and the vast potential of LLMs. This downloadable software handles the complexities of running large language models on your local machine, with a focus on open-source models free for public use. With LM Studio, switching between different language models is a breeze, thanks to its user-friendly interface that simplifies the downloading process, inviting users into a seamless dialogue with these digital entities.
Download it here: https://lmstudio.ai/
Hugging Face is a platform where the machine learning community collaborates on models, datasets, and applications. It's a hub for creating, discovering, and collaborating on machine learning projects, with a focus on text, among other modalities like images and videos
Start with picking a base model Mistral 7B, which is already trained to handle general tasks in your area of interest. It's one of many models you can try out.
In handling a long list of data, like a very long sentence, the computer employs a technique called Sliding Window Attention (SWA), which acts like a small spotlight moving along the sentence, allowing the computer to focus on a few words at a time instead of the whole sentence. This spotlight technique, along with some other adjustments, makes the process twice as fast when dealing with very long sentences. Even with this small spotlight, the computer can understand connections between words that are far apart in the sentence by passing information from one stage to the next, similar to passing notes in a classroom. Additionally, the SWA helps in using less memory, akin to needing a smaller notebook for jotting down notes, which is beneficial when dealing with long sentences.
Gather your data and start fine-tuning the model. Make sure your data is clean and ready for training. Then, fine-tune Mistral 7B using your data by running more training rounds, starting with the pre-set settings of the model. You might need to tweak or add some parts of the model to make it work better for your task. There are other versions of Mistral 7B that have been fine-tuned by others which might be helpful or interesting for your project. This way, you get a structured way to adapt a ready-made model for your specific needs while also checking out what others have done.
Link to: OpenHermes 2 - Mistral 7B and Mistral-7B-OpenOrca
You can also augment your prompts utilizing a hot new method for prompt engineering called RAG or retrieval augmented generation. Fetch important and relevant data from PDFs, text files, etc. based on the prompt to augment our prompt with context.
By granting the prompt and the AI context, we can get even more accurate responses from our local model which is especially important when running smaller models like Mistral 7B. Learn more about RAG here.
It is important to keep in mind that RAG does not solve the common LLM pitfalls like hallucination and serves as a means to guide your LLM to a more niche response. The endpoints that ultimately matter, are specific to your use case, the information you feed your model, and how the model is fine-tuned.
Mistral 7B being licensed under Apache 2.0 means that it is open-source, and you can freely use, modify, and distribute it. The Apache 2.0 License also provides a grant of patent rights from contributors to users, which is beneficial in reducing legal risks. This licensing allows developers and organizations to collaboratively work on and share the model, promoting open collaboration and innovation.
The practical applications of engaging with LLMs through LM Studio are limited only by imagination. For instance, users can develop a conversational knowledge base assistant and utilize their model as a companion for learning and mastering new programming languages. They can identify intricate coding queries, offer detailed explanations of algorithms, or debug in real-time—transforming code exploration into a dynamic, responsive, and interactive learning experience.
If you have any questions about Large Language Models and how to train and run them, contact Exxact Today.



