Deep Learning
Large Action Model - Large Language Models for Performing Tasks
June 13, 2025
7 min read


Large Language Models (LLMs) have revolutionized our day-to-day productivity with its ability to understand and generate text across a wide range of topics. But while LLMs excel at conversation, summarization, and content generation, they have a key limitation: they stop at language. They can tell you what to do, but they can’t do it for you.
This is where Language Action Models (LAMs) come in. LAMs build on the foundation of LLMs but add a crucial new capability — action. Instead of just producing responses, LAMs can understand intent, plan steps, and interact with tools or systems to carry out tasks. Whether it’s automating database updates, language-powered robotics, LAMs are designed to turn natural language into meaningful, real-world outcomes.
A Language Action Model (LAM) is an AI system that not only understands language but uses it to perform actions. Unlike traditional LLMs that focus on generating text, LAMs are built to interpret commands, plan next steps, and take action. Large Action Models (LAMs) are designed to understand human intentions and translate them into actions within a given environment or system.
LAMs combine language understanding with tool use, decision-making, and memory. They can call APIs, interact with apps, and reference past context to follow through on complex tasks — all while communicating naturally with users.
LAMs are useful anywhere natural language can drive real action. Common applications include:
These use cases show how LAMs bridge the gap between communication and execution, making AI more practical and hands-on.
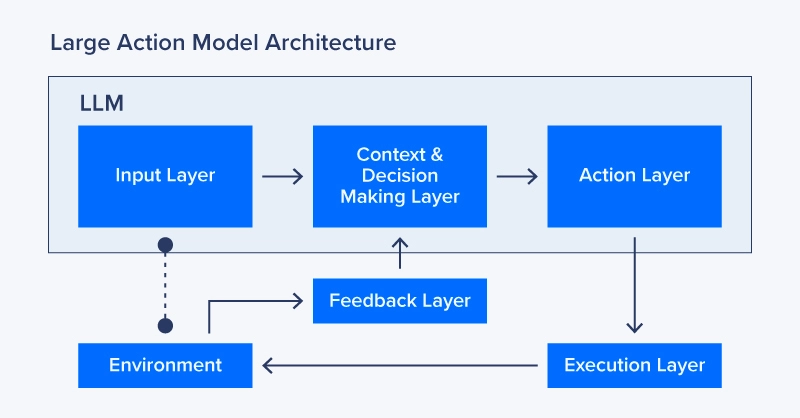
LAMs operate through a series of interconnected components that enable them to understand language, make decisions, and perform tasks:
Here's an example of a Language Action Model in a personal robot. In this case, computer vision is necessary. NVIDIA has teased this capability and developed the capability to talk to and interact with humanoid robots. If you ask your robot to place an apple in the basket, we can employ a Large Action Model.
While Language Action Models (LAMs) unlock advanced capabilities, their deployment requires deliberate engineering to ensure reliability, safety, and performance. Below are critical factors to consider:
To build a robust and scalable LAM-powered system, consider the following best practices:
Language Action Models (LAMs) build on traditional language models by transforming natural language into executable actions. With capabilities like intent recognition, planning, and tool use, LAMs enable systems to move toward autonomous task completion.
This shift addresses a core limitation of LLMs — their inability to act — and opens the door to smarter, more efficient automation. As AI adoption grows, LAMs are poised to become foundational in developing agents that can operate independently and productively.
LAMs represent the infrastructure needed to build systems that not only understand instructions but also respond with meaningful, goal-directed action.
.png)
Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research.
Configure NowLarge Language Models (LLMs) have revolutionized our day-to-day productivity with its ability to understand and generate text across a wide range of topics. But while LLMs excel at conversation, summarization, and content generation, they have a key limitation: they stop at language. They can tell you what to do, but they can’t do it for you.
This is where Language Action Models (LAMs) come in. LAMs build on the foundation of LLMs but add a crucial new capability — action. Instead of just producing responses, LAMs can understand intent, plan steps, and interact with tools or systems to carry out tasks. Whether it’s automating database updates, language-powered robotics, LAMs are designed to turn natural language into meaningful, real-world outcomes.
A Language Action Model (LAM) is an AI system that not only understands language but uses it to perform actions. Unlike traditional LLMs that focus on generating text, LAMs are built to interpret commands, plan next steps, and take action. Large Action Models (LAMs) are designed to understand human intentions and translate them into actions within a given environment or system.
LAMs combine language understanding with tool use, decision-making, and memory. They can call APIs, interact with apps, and reference past context to follow through on complex tasks — all while communicating naturally with users.
LAMs are useful anywhere natural language can drive real action. Common applications include:
These use cases show how LAMs bridge the gap between communication and execution, making AI more practical and hands-on.
LAMs operate through a series of interconnected components that enable them to understand language, make decisions, and perform tasks:
Here's an example of a Language Action Model in a personal robot. In this case, computer vision is necessary. NVIDIA has teased this capability and developed the capability to talk to and interact with humanoid robots. If you ask your robot to place an apple in the basket, we can employ a Large Action Model.
While Language Action Models (LAMs) unlock advanced capabilities, their deployment requires deliberate engineering to ensure reliability, safety, and performance. Below are critical factors to consider:
To build a robust and scalable LAM-powered system, consider the following best practices:
Language Action Models (LAMs) build on traditional language models by transforming natural language into executable actions. With capabilities like intent recognition, planning, and tool use, LAMs enable systems to move toward autonomous task completion.
This shift addresses a core limitation of LLMs — their inability to act — and opens the door to smarter, more efficient automation. As AI adoption grows, LAMs are poised to become foundational in developing agents that can operate independently and productively.
LAMs represent the infrastructure needed to build systems that not only understand instructions but also respond with meaningful, goal-directed action.
Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research.
Configure Now

