Benchmarks
HGX-2 Benchmarks for Deep Learning in TensorFlow: A 16x V100 SXM3 NVSwitch GPU Server
August 16, 2019
5 min read


For this post, we show deep learning benchmarks for TensorFlow on an Exxact TensorEX HGX-2 Server. This behemoth of a Deep Learning Server has 16 NVIDIA Tesla V100 GPUs.
We ran the standard "tf_cnn_benchmarks.py" benchmark script from TensorFlow's github. To compare, tests were run on the following networks: ResNet-50, ResNet-152, Inception V3, VGG-16. In addition we compared the FP16 to FP32 performance, and used batch size of 256 (except for ResNet152 FP32, the batch size was 64). As you'll see, the same tests were run using 1,2,4,8 and 16 GPU configurations. All benchmarks were done using 'vanilla' TensorFlow settings for FP16 and FP32.

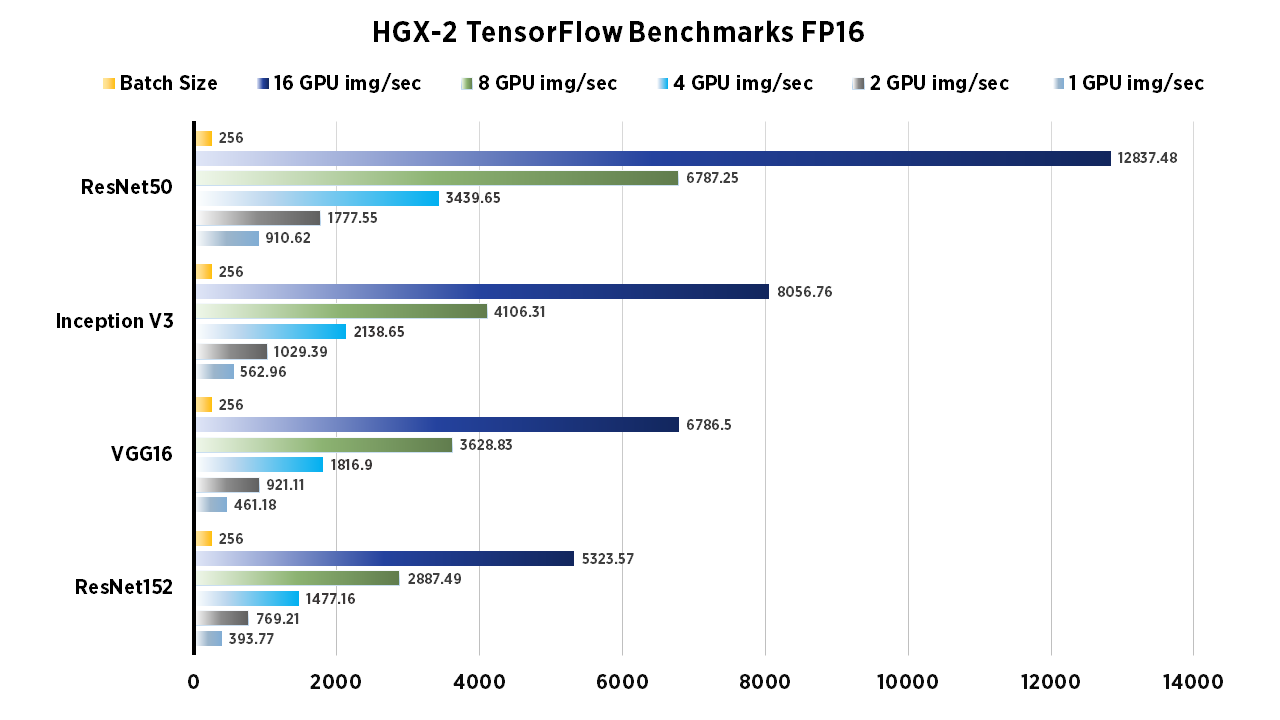
| 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 1735.56 | 3218 | 128 |
| ResNet152 | 760.57 | 1415.56 | 128 |
| Inception V3 | 1134.88 | 2161.02 | 128 |
| Inception V4 | 602.36 | 1205.97 | 128 |
| googlenet | 2820.47 | 5265.14 | 128 |
Configure the num_gpus to the number of GPUs desired to test. Change model to desired model architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=256 --model=resnet50 --variable_update=parameter_server --use_fp16=True
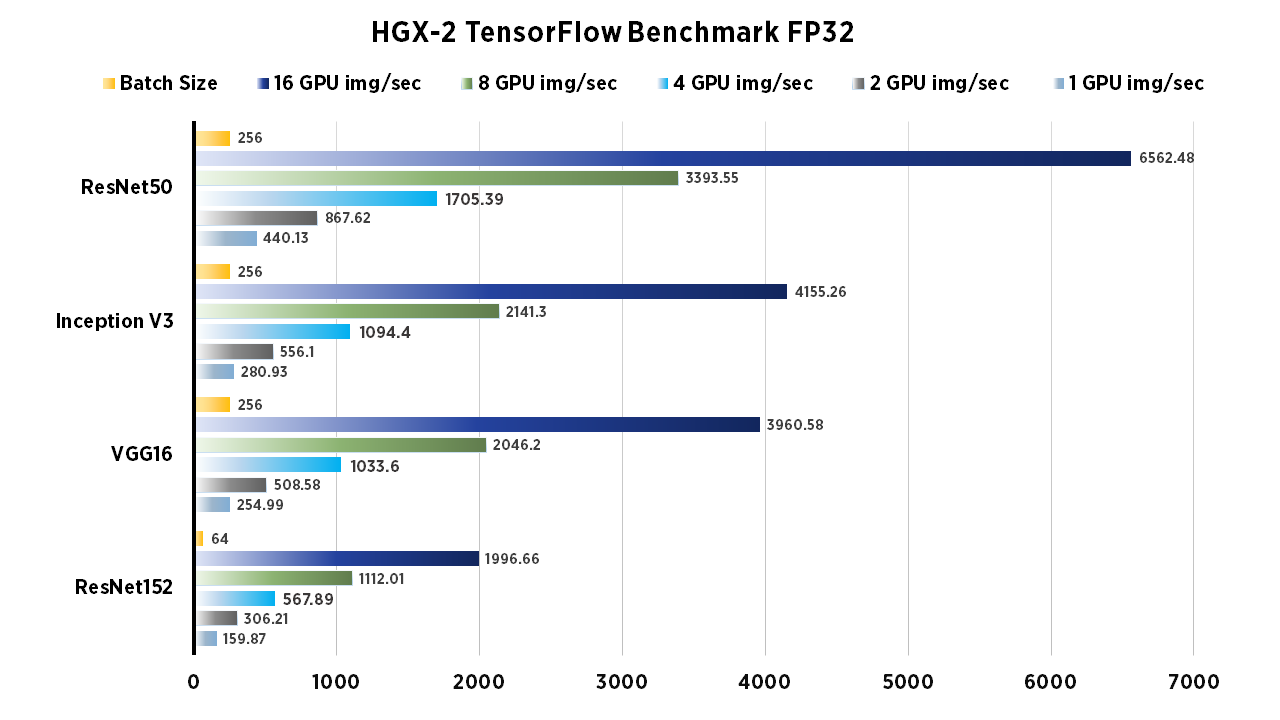
| 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 762.21 | 1432.69 | 128 |
| ResNet152 | 278.17 | 577.26 | 128 |
| Inception V3 | 495.51 | 926.93 | 128 |
| Inception V4 | 227.05 | 455.65 | 128 |
| googlenet | 1692.94 | 3393.91 | 128 |
To run FP32, remove fp16 flag, configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=256 --model=resnet50 --variable_update=parameter_server
The HGX2 GPU server is an absolute monster for deep learning or any GPU powered HPC tasks. In the future, we would like to conduct further benchmarks on more models as well as other acceleration methods such as XLA for TensorFlow, where we would expect significant performance gains. Also training models on even larger batch sizes is another area we will consider exploring.
| System | Exxact TensorEX HGX-2 |
| GPU | 16x NVIDIA Tesla V100 32 GB SXM3 |
| CPU | 2x Intel Xeon Platinum 8168 |
| RAM | 1.5 TB DDR4 |
| SSD (OS) | 1TB x2 NVMe (RAID 1) |
| SSD (Data) | 32 TB NVMe Storage |
| OS | Ubuntu 16.04 |
| NVIDIA DRIVER | 418.67 |
| CUDA Version | 10.1 |
| Python | 2.7 |
| TensorFlow | 1.14 |
| Docker Image | tensorflow/tensorflow:nightly-gpu |

| Dataset: | Imagenet (synthetic) |
| Mode: | training |
| SingleSess: | False |
| Batch Size: | 256 per device* |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | sgd |
| Variables: | parameter_server |
For this post, we show deep learning benchmarks for TensorFlow on an Exxact TensorEX HGX-2 Server. This behemoth of a Deep Learning Server has 16 NVIDIA Tesla V100 GPUs.
We ran the standard "tf_cnn_benchmarks.py" benchmark script from TensorFlow's github. To compare, tests were run on the following networks: ResNet-50, ResNet-152, Inception V3, VGG-16. In addition we compared the FP16 to FP32 performance, and used batch size of 256 (except for ResNet152 FP32, the batch size was 64). As you'll see, the same tests were run using 1,2,4,8 and 16 GPU configurations. All benchmarks were done using 'vanilla' TensorFlow settings for FP16 and FP32.
| 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 1735.56 | 3218 | 128 |
| ResNet152 | 760.57 | 1415.56 | 128 |
| Inception V3 | 1134.88 | 2161.02 | 128 |
| Inception V4 | 602.36 | 1205.97 | 128 |
| googlenet | 2820.47 | 5265.14 | 128 |
Configure the num_gpus to the number of GPUs desired to test. Change model to desired model architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=256 --model=resnet50 --variable_update=parameter_server --use_fp16=True
| 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 762.21 | 1432.69 | 128 |
| ResNet152 | 278.17 | 577.26 | 128 |
| Inception V3 | 495.51 | 926.93 | 128 |
| Inception V4 | 227.05 | 455.65 | 128 |
| googlenet | 1692.94 | 3393.91 | 128 |
To run FP32, remove fp16 flag, configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=256 --model=resnet50 --variable_update=parameter_server
The HGX2 GPU server is an absolute monster for deep learning or any GPU powered HPC tasks. In the future, we would like to conduct further benchmarks on more models as well as other acceleration methods such as XLA for TensorFlow, where we would expect significant performance gains. Also training models on even larger batch sizes is another area we will consider exploring.
| System | Exxact TensorEX HGX-2 |
| GPU | 16x NVIDIA Tesla V100 32 GB SXM3 |
| CPU | 2x Intel Xeon Platinum 8168 |
| RAM | 1.5 TB DDR4 |
| SSD (OS) | 1TB x2 NVMe (RAID 1) |
| SSD (Data) | 32 TB NVMe Storage |
| OS | Ubuntu 16.04 |
| NVIDIA DRIVER | 418.67 |
| CUDA Version | 10.1 |
| Python | 2.7 |
| TensorFlow | 1.14 |
| Docker Image | tensorflow/tensorflow:nightly-gpu |
| Dataset: | Imagenet (synthetic) |
| Mode: | training |
| SingleSess: | False |
| Batch Size: | 256 per device* |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | sgd |
| Variables: | parameter_server |

{kind=link}