Benchmarks
NVIDIA Quadro RTX 6000 GPU Performance Benchmarks for TensorFlow
April 26, 2019
36 min read


For this post, we conducted deep learning performance benchmarks for TensorFlow using the new NVIDIA Quadro RTX 6000 GPUs. Our Exxact Valence Workstation was fitted with 4x Quadro RTX 6000's giving us 96 GB of GPU memory for our system.
We ran the standard "tf_cnn_benchmarks.py" benchmark script (found here in the official TensorFlow github) on the following networks: ResNet-50, ResNet-152, Inception v3, Inception v4, VGG-16, AlexNet, and Nasnet.
We also compared FP16 to FP32 performance, and used 'typical' batch sizes (64 in most cases), then incrementally doubled the batch size until we threw a memory error. We ran the same tests using 1,2 and 4 GPU configurations. In addition we've also ran benchmarks using XLA and noticed substantial improvements.
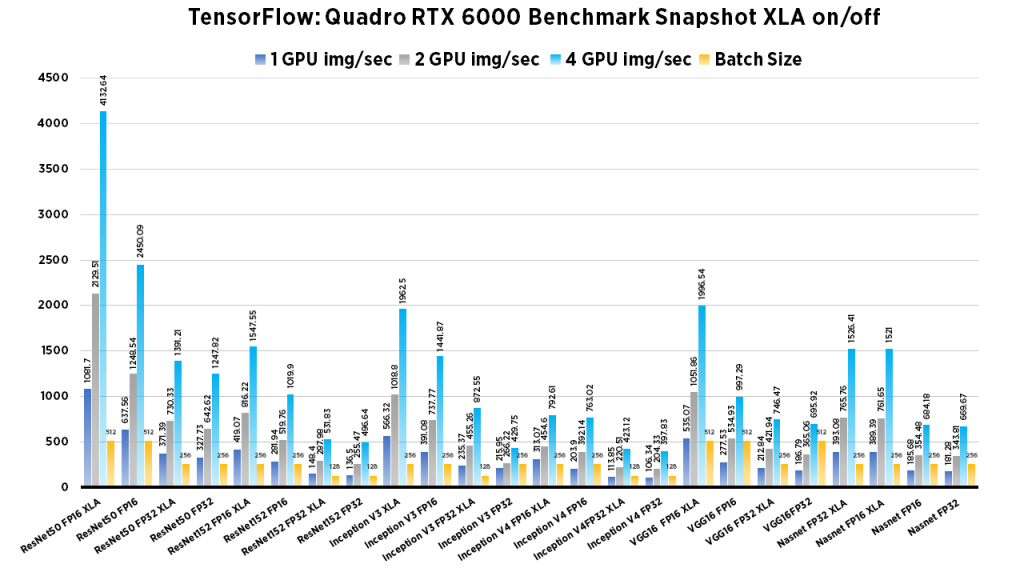
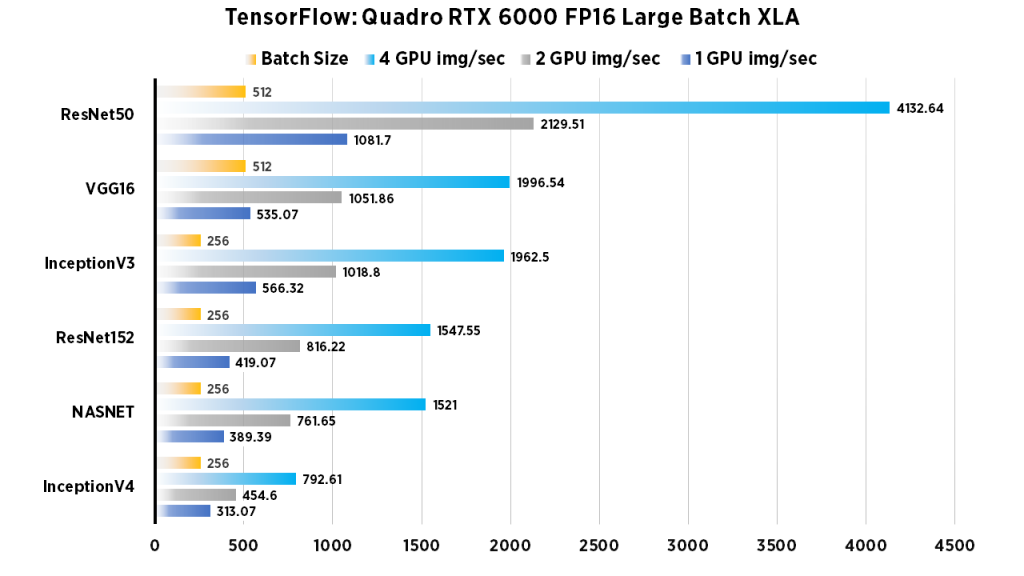
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 1081.7 | 2129.51 | 4132.64 | 512 |
| ResNet152 | 419.07 | 816.22 | 1547.55 | 256 |
| InceptionV3 | 566.32 | 1018.8 | 1962.5 | 256 |
| Inception V4 | 313.07 | 454.6 | 792.61 | 256 |
| VGG16 | 535.07 | 1051.86 | 1996.54 | 512 |
| NASNET | 389.39 | 761.65 | 1521 | 256 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=256 --num_batches=100 --model=inception4 --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --use_fp16=True --nodistortions --gradient_repacking=2 --datasets_use_codefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
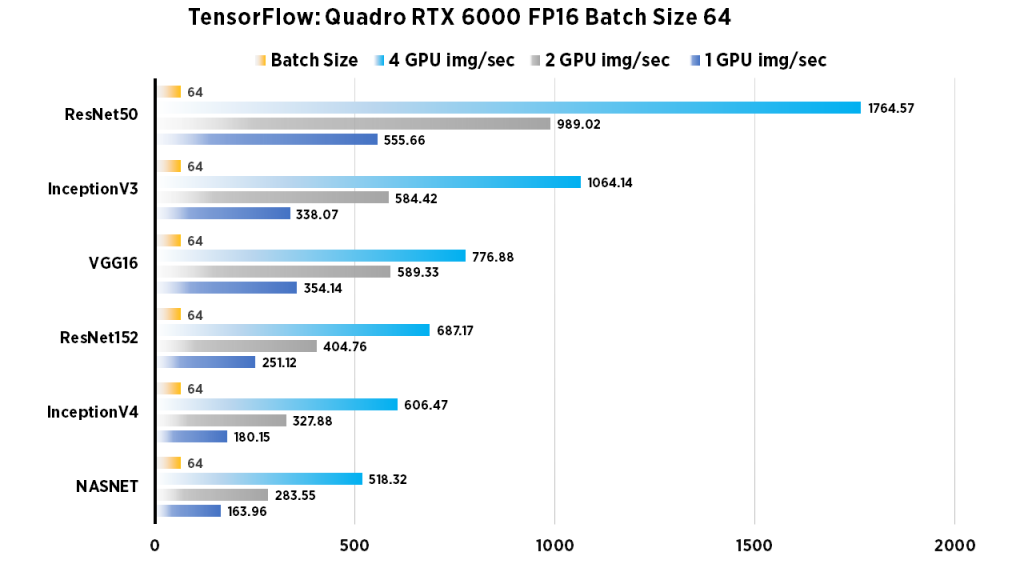
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 555.66 | 989.02 | 1764.57 | 64 |
| ResNet152 | 251.12 | 404.76 | 687.17 | 64 |
| InceptionV3 | 338.07 | 584.42 | 1064.14 | 64 |
| InceptionV4 | 180.15 | 327.88 | 606.47 | 64 |
| VGG16 | 354.14 | 589.33 | 776.88 | 64 |
| NASNET | 163.96 | 283.55 | 518.32 | 64 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=64 --model=resnet50 --variable_update=parameter_server --use_fp16=True
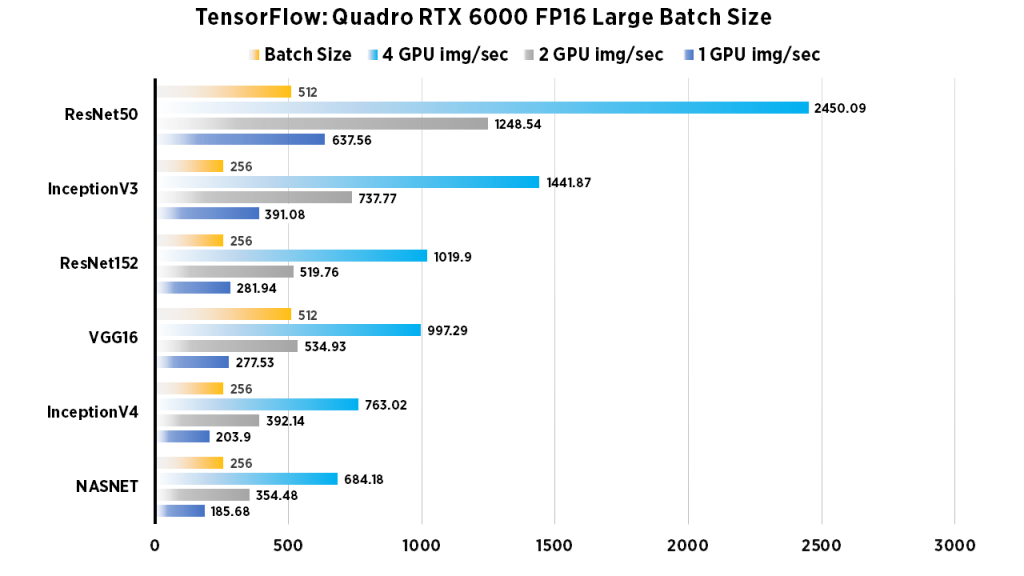
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 637.56 | 1248.54 | 2450.09 | 512 |
| ResNet152 | 281.94 | 519.76 | 1019.9 | 256 |
| InceptionV3 | 391.08 | 737.77 | 1441.87 | 256 |
| InceptionV4 | 203.9 | 392.14 | 763.02 | 256 |
| VGG16 | 277.53 | 534.93 | 997.29 | 512 |
| NASNET | 185.68 | 354.48 | 684.18 | 256 |

Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=512 --model=resnet50 --variable_update=parameter_server --use_fp16=True

| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| NASNET | 393.08 | 765.76 | 1526.41 | 256 |
| ResNet50 | 371.39 | 730.33 | 1391.21 | 256 |
| InceptionV3 | 235.37 | 455.26 | 872.55 | 128 |
| VGG16 | 212.84 | 421.94 | 746.47 | 256 |
| ResNet152 | 148.4 | 287.98 | 531.83 | 128 |
| InceptionV4 | 113.85 | 220.51 | 423.12 | 128 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture use .
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=256 --num_batches=100 --model=resnet50 --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --nodistortions --gradient_repacking=2 --datasets_use_codefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
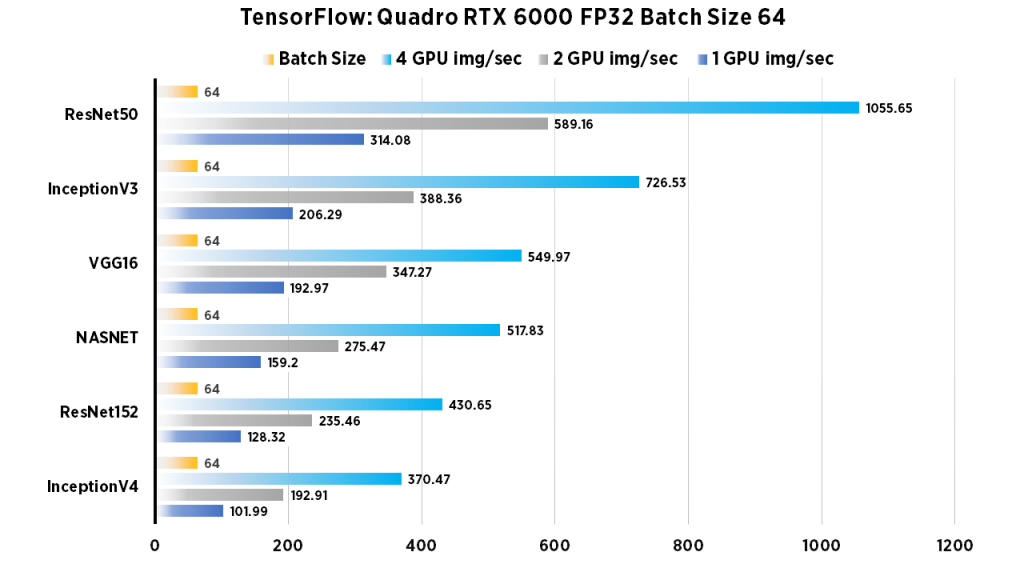
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 314.08 | 589.16 | 1055.65 | 64 |
| ResNet152 | 128.32 | 235.46 | 430.65 | 64 |
| InceptionV3 | 206.29 | 388.36 | 726.53 | 64 |
| InceptionV4 | 101.99 | 192.91 | 370.47 | 64 |
| VGG16 | 192.97 | 347.27 | 549.97 | 64 |
| NASNET | 159.2 | 275.47 | 517.83 | 64 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=64 --model=resnet50 --variable_update=parameter_server

| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 327.73 | 642.62 | 1247.82 | 256 |
| ResNet152 | 136.5 | 255.47 | 496.64 | 128 |
| InceptionV3* | 215.95 | 266.22 | 429.75 | 256 (*128 when using 1 GPU) |
| InceptionV4 | 106.34 | 204.33 | 397.83 | 128 |
| VGG16 | 186.79 | 365.06 | 695.92 | 512 |
| NASNET | 181.28 | 343.81 | 669.67 | 256 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=256 --model=resnet50 --variable_update=parameter_server
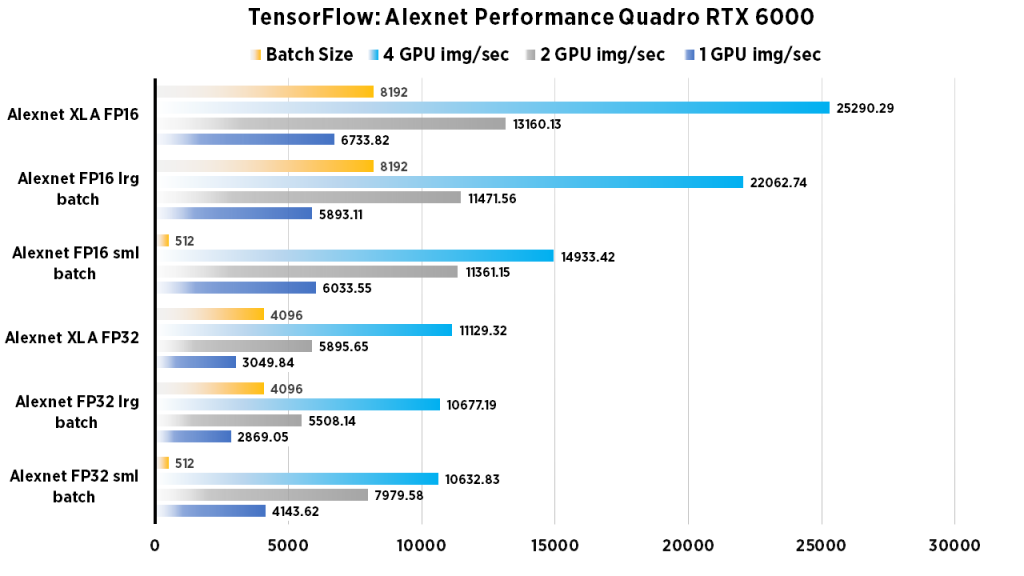
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| Alexnet FP16 (Large Batch) | 5893.11 | 11471.56 | 22062.74 | 8192 |
| Alexnet FP16 (Normal Batch) | 6033.55 | 11361.15 | 14933.42 | 512 |
| Alexnet FP32 (Large Batch) | 2869.05 | 5508.14 | 10677.19 | 4096 |
| Alexnet FP32 (Normal Batch) | 4143.62 | 7979.58 | 10632.83 | 512 |
| Alexnet XLA FP32 | 3049.84 | 5895.65 | 11129.32 | 4096 |
| Alexnet XLA FP16 | 6733.82 | 13160.13 | 25290.29 | 8192 |
Run these deep learning benchmarks
configure the num_gpus to the number of GPUs desired to test, and omit use_fp16 flag to run in fp32.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=8192 --model=alexnet --variable_update=parameter_server --use_fp16=True

| System | Exxact Valence Workstation |
| GPU | 4 x NVIDIA Quadro RTX 6000 |
| CPU | Intel CORE I7-7820X 3.6GHZ |
| RAM | 32GB DDR4 |
| SSD | 480 GB SSD |
| HDD (data) | 10 TB HDD |
| OS | Ubuntu 18.04 |
| NVIDIA DRIVER | 418.43 |
| CUDA Version | 10.1 |
| Python | 2.7 |
| TensorFlow | 1.14 |
| Docker Image | tensorflow/tensorflow:nightly-gpu |
| Dataset: | Imagenet (synthetic) |
| Mode: | training |
| SingleSess: | False |
| Batch Size: | Varied |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | sgd |
| Variables: | parameter_server |
| Dataset: | Imagenet (synthetic) |
| Mode: | training |
| SingleSess: | False |
| Batch Size: | Varied |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | momentum |
| Variables: | replicated |
| AllReduce | nccl |
For this post, we conducted deep learning performance benchmarks for TensorFlow using the new NVIDIA Quadro RTX 6000 GPUs. Our Exxact Valence Workstation was fitted with 4x Quadro RTX 6000's giving us 96 GB of GPU memory for our system.
We ran the standard "tf_cnn_benchmarks.py" benchmark script (found here in the official TensorFlow github) on the following networks: ResNet-50, ResNet-152, Inception v3, Inception v4, VGG-16, AlexNet, and Nasnet.
We also compared FP16 to FP32 performance, and used 'typical' batch sizes (64 in most cases), then incrementally doubled the batch size until we threw a memory error. We ran the same tests using 1,2 and 4 GPU configurations. In addition we've also ran benchmarks using XLA and noticed substantial improvements.
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 1081.7 | 2129.51 | 4132.64 | 512 |
| ResNet152 | 419.07 | 816.22 | 1547.55 | 256 |
| InceptionV3 | 566.32 | 1018.8 | 1962.5 | 256 |
| Inception V4 | 313.07 | 454.6 | 792.61 | 256 |
| VGG16 | 535.07 | 1051.86 | 1996.54 | 512 |
| NASNET | 389.39 | 761.65 | 1521 | 256 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=256 --num_batches=100 --model=inception4 --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --use_fp16=True --nodistortions --gradient_repacking=2 --datasets_use_codefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 555.66 | 989.02 | 1764.57 | 64 |
| ResNet152 | 251.12 | 404.76 | 687.17 | 64 |
| InceptionV3 | 338.07 | 584.42 | 1064.14 | 64 |
| InceptionV4 | 180.15 | 327.88 | 606.47 | 64 |
| VGG16 | 354.14 | 589.33 | 776.88 | 64 |
| NASNET | 163.96 | 283.55 | 518.32 | 64 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=64 --model=resnet50 --variable_update=parameter_server --use_fp16=True
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 637.56 | 1248.54 | 2450.09 | 512 |
| ResNet152 | 281.94 | 519.76 | 1019.9 | 256 |
| InceptionV3 | 391.08 | 737.77 | 1441.87 | 256 |
| InceptionV4 | 203.9 | 392.14 | 763.02 | 256 |
| VGG16 | 277.53 | 534.93 | 997.29 | 512 |
| NASNET | 185.68 | 354.48 | 684.18 | 256 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=512 --model=resnet50 --variable_update=parameter_server --use_fp16=True
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| NASNET | 393.08 | 765.76 | 1526.41 | 256 |
| ResNet50 | 371.39 | 730.33 | 1391.21 | 256 |
| InceptionV3 | 235.37 | 455.26 | 872.55 | 128 |
| VGG16 | 212.84 | 421.94 | 746.47 | 256 |
| ResNet152 | 148.4 | 287.98 | 531.83 | 128 |
| InceptionV4 | 113.85 | 220.51 | 423.12 | 128 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture use .
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=256 --num_batches=100 --model=resnet50 --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --nodistortions --gradient_repacking=2 --datasets_use_codefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 314.08 | 589.16 | 1055.65 | 64 |
| ResNet152 | 128.32 | 235.46 | 430.65 | 64 |
| InceptionV3 | 206.29 | 388.36 | 726.53 | 64 |
| InceptionV4 | 101.99 | 192.91 | 370.47 | 64 |
| VGG16 | 192.97 | 347.27 | 549.97 | 64 |
| NASNET | 159.2 | 275.47 | 517.83 | 64 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=64 --model=resnet50 --variable_update=parameter_server
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet50 | 327.73 | 642.62 | 1247.82 | 256 |
| ResNet152 | 136.5 | 255.47 | 496.64 | 128 |
| InceptionV3* | 215.95 | 266.22 | 429.75 | 256 (*128 when using 1 GPU) |
| InceptionV4 | 106.34 | 204.33 | 397.83 | 128 |
| VGG16 | 186.79 | 365.06 | 695.92 | 512 |
| NASNET | 181.28 | 343.81 | 669.67 | 256 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=256 --model=resnet50 --variable_update=parameter_server
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| Alexnet FP16 (Large Batch) | 5893.11 | 11471.56 | 22062.74 | 8192 |
| Alexnet FP16 (Normal Batch) | 6033.55 | 11361.15 | 14933.42 | 512 |
| Alexnet FP32 (Large Batch) | 2869.05 | 5508.14 | 10677.19 | 4096 |
| Alexnet FP32 (Normal Batch) | 4143.62 | 7979.58 | 10632.83 | 512 |
| Alexnet XLA FP32 | 3049.84 | 5895.65 | 11129.32 | 4096 |
| Alexnet XLA FP16 | 6733.82 | 13160.13 | 25290.29 | 8192 |
Run these deep learning benchmarks
configure the num_gpus to the number of GPUs desired to test, and omit use_fp16 flag to run in fp32.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=8192 --model=alexnet --variable_update=parameter_server --use_fp16=True
| System | Exxact Valence Workstation |
| GPU | 4 x NVIDIA Quadro RTX 6000 |
| CPU | Intel CORE I7-7820X 3.6GHZ |
| RAM | 32GB DDR4 |
| SSD | 480 GB SSD |
| HDD (data) | 10 TB HDD |
| OS | Ubuntu 18.04 |
| NVIDIA DRIVER | 418.43 |
| CUDA Version | 10.1 |
| Python | 2.7 |
| TensorFlow | 1.14 |
| Docker Image | tensorflow/tensorflow:nightly-gpu |
| Dataset: | Imagenet (synthetic) |
| Mode: | training |
| SingleSess: | False |
| Batch Size: | Varied |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | sgd |
| Variables: | parameter_server |
| Dataset: | Imagenet (synthetic) |
| Mode: | training |
| SingleSess: | False |
| Batch Size: | Varied |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | momentum |
| Variables: | replicated |
| AllReduce | nccl |
