Benchmarks
NVIDIA Quadro RTX 8000 BERT Large Fine Tuning Benchmarks in TensorFlow
December 18, 2019
13 min read


For this post, we measured fine-tuning performance (training and inference) for the BERT (Bidirectional Encoder Representations from Transformers) implementation in TensorFlow using NVIDIA Quadro RTX 8000 GPUs. For testing, we used an Exxact Valence Workstation fitted with 4x Quadro RTX 8000’s with NVLink, giving us 192 GB of GPU memory for our system. These tests measure performance for a popular use case for BERT and NLP in general and are meant to show typical GPU performance for such a task.
Benchmark scripts we used for evaluation was the finetune_train_benchmark.sh and finetune_inference_benchmark.sh from NVIDIA NGC Repository BERT for TensorFlow. We made slight modifications to the training benchmark script to get the larger batch size metrics.
The script runs multiple tests on the SQuAD v1.1 dataset using batch sizes 1, 2, 4, 8, 16, 32, and 64 for training, and 1, 2, 4, and 8 for inference. We conducted tests using 1, 2, and 4 GPU configurations on BERT Large (We used 1 GPU for inference benchmark). In addition, we ran all benchmarks using TensorFlow's XLA across all runs. Furthermore, other training settings can be viewed at the end of this blog in the Appendix/Additional Information section.
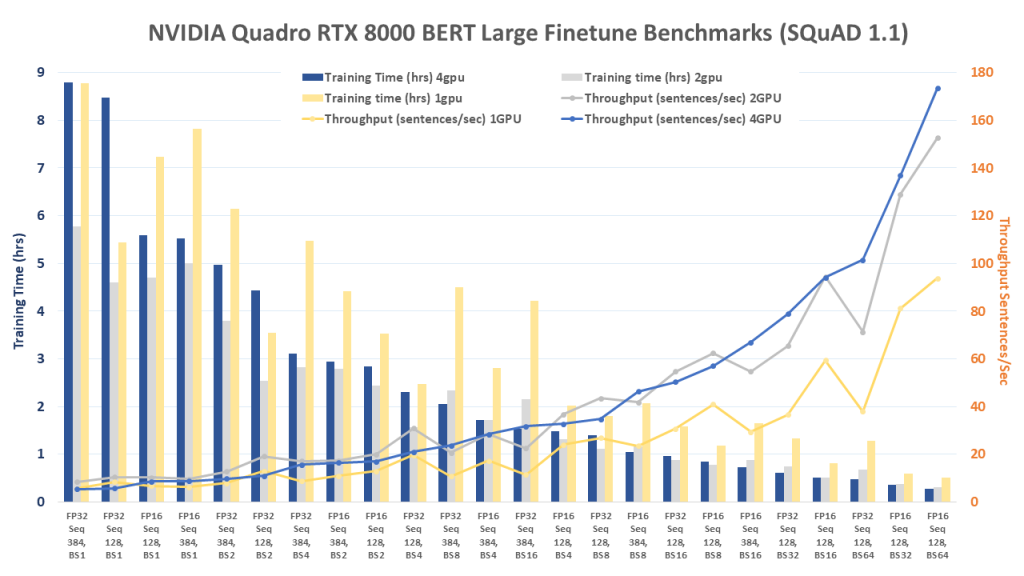
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size

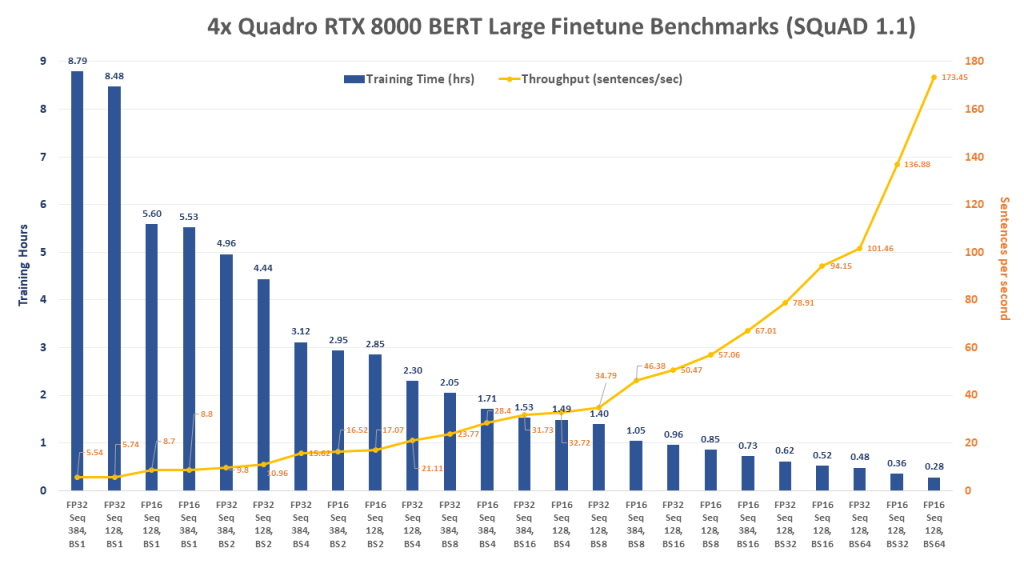
[supsystic-tables id=56]
Run these benchmarks
Assuming you're using the NGC BERT for TensorFlow container, run the following command.
scripts/finetune_train_benchmark.sh large true 4 squad
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size
[supsystic-tables id=57]
Run these benchmarks
Assuming you're using the NGC BERT for TensorFlow container, run the following command.
scripts/finetune_train_benchmark.sh large true 2 squad

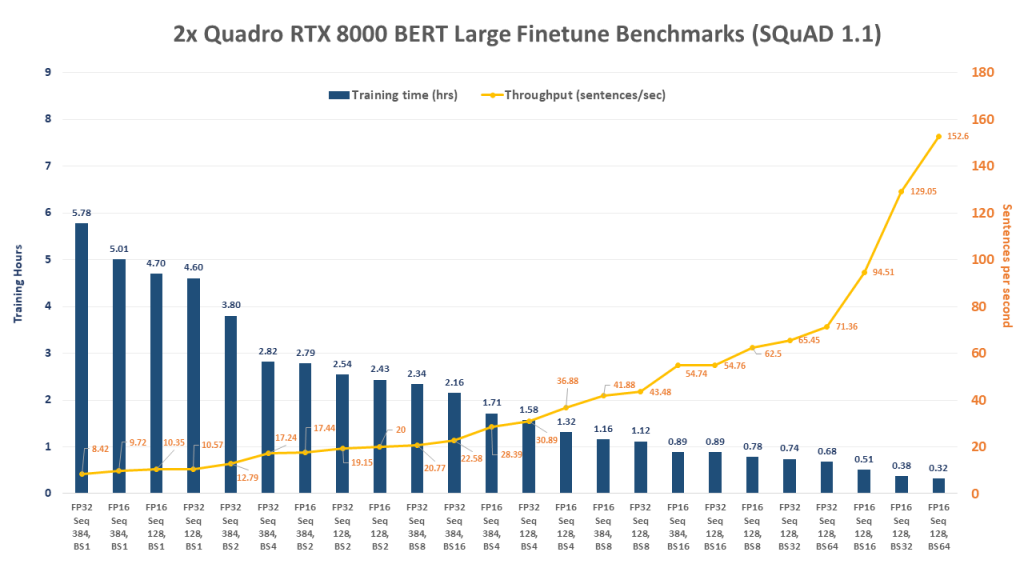
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size
[supsystic-tables id=58]
Run these benchmarks
Assuming you're using the NGC BERT for TensorFlow container, run the following command.
scripts/finetune_train_benchmark.sh large true 1 squad
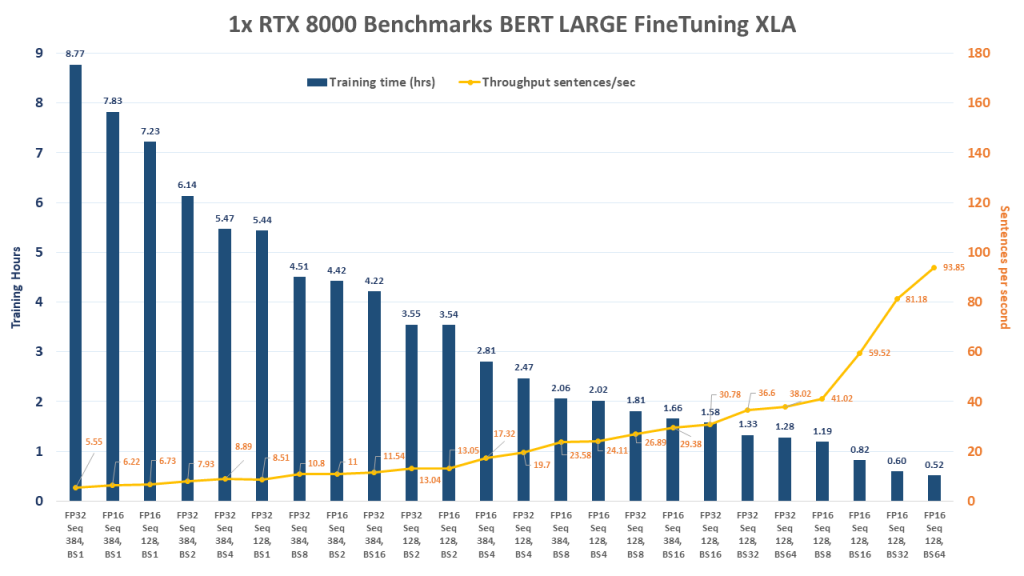
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size
| Training Settings | Total Inference Time | Number of sentences | Latency Confidence Level 50ms | Latency Confidence Level 90 ms | Latency Confidence Level 95 ms | Latency Confidence Level 99 ms | Latency Confidence Level 100 ms | Latency Avg | Throughput (sentences/sec) |
| FP16 Seq 384, BS1 | 18.4 | 1042 | 17.9 | 18.33 | 18.59 | 19.25 | 21.78 | 17.66 | 56.64 |
| FP16 Seq 384, BS2 | 24.66 | 2068 | 23.54 | 24.16 | 24.37 | 25.28 | 637.7 | 23.85 | 83.87 |
| FP16 Seq 128, BS2 | 24.73 | 3402 | 15.07 | 16.17 | 16.47 | 17.07 | 22.4 | 14.54 | 137.57 |
| FP16 Seq 128, BS1 | 26.23 | 1800 | 15.42 | 16.56 | 16.76 | 17.6 | 20.43 | 14.57 | 68.36 |
| FP16 Seq 128, BS4 | 29.39 | 7128 | 16.13 | 16.84 | 17.2 | 17.89 | 687.32 | 16.49 | 242.54 |
| FP32 Seq 128, BS1 | 34.34 | 1800 | 20.93 | 22.66 | 23.16 | 24.63 | 28.59 | 19.08 | 52.41 |
| FP32 Seq 128, BS2 | 39.02 | 3402 | 23.1 | 23.92 | 24.15 | 24.71 | 29.27 | 22.94 | 87.18 |
| FP16 Seq 384, BS4 | 40.64 | 4128 | 39.09 | 39.71 | 39.93 | 41.64 | 624.06 | 39.38 | 101.58 |
| FP32 Seq 384, BS1 | 42.74 | 1042 | 42.77 | 44.19 | 44.3 | 44.54 | 46.82 | 41.02 | 24.38 |
| FP16 Seq 128, BS8 | 45.61 | 16040 | 22.68 | 23.4 | 23.71 | 24.43 | 531.04 | 22.75 | 351.67 |
| FP32 Seq 384, BS2 | 74.92 | 2068 | 73.38 | 74.53 | 74.68 | 74.95 | 90.78 | 72.46 | 27.6 |
| FP16 Seq 128, BS8 | 76.95 | 8432 | 72.57 | 74.13 | 74.46 | 75.62 | 624.44 | 73.01 | 109.58 |
| FP32 Seq 128, BS4 | 82.92 | 7128 | 47.23 | 48.57 | 48.71 | 49.23 | 208.24 | 46.53 | 85.96 |
| FP32 Seq 384, BS4 | 159.02 | 4128 | 156.41 | 159.25 | 159.95 | 160.72 | 175.58 | 154.09 | 25.96 |
| FP32 Seq 128, BS8 | 172.07 | 16040 | 86.33 | 87.54 | 87.71 | 88.23 | 98.14 | 85.82 | 93.33 |
| FP32 Seq 128, BS8 | 301.05 | 8432 | 287.52 | 289.06 | 289.48 | 291.17 | 499.43 | 285.62 | 28.01 |
Run these benchmarks
Assuming you're using the NGC BERT for TensorFlow container, run the following command.
scripts/finetune_inference_benchmark.sh large squad
| System | Exxact Valence Workstation |
| GPU | 4 x NVIDIA Quadro RTX 8000 |
| CPU | Intel CORE I7-7820X 3.6GHZ |
| RAM | 64GB DDR4 |
| SSD | 480 GB SSD |
| HDD (data) | 10 TB HDD |
| OS | Ubuntu 18.04 |
| NVIDIA DRIVER | 435.21 |
| CUDA Version | 10.1 |
| Python | 2.7/3.6 |
| TensorFlow | 1.14 |
| Container (usingNVIDIA Docker) | TensorFlow 19.08-py3+ NGC container |

NOTE: these will change with each run depending on batch size, sequence length, etc.
***** Configuaration *****
I1212 17:24:48.136919 139750589261632 run_squad.py:950] logtostderr: False
I1212 17:24:48.136960 139750589261632 run_squad.py:950] alsologtostderr: False
I1212 17:24:48.137000 139750589261632 run_squad.py:950] log_dir:
I1212 17:24:48.137040 139750589261632 run_squad.py:950] v: 0
I1212 17:24:48.137079 139750589261632 run_squad.py:950] verbosity: 0
I1212 17:24:48.137117 139750589261632 run_squad.py:950] stderrthreshold: fatal
I1212 17:24:48.137156 139750589261632 run_squad.py:950] showprefixforinfo: True
I1212 17:24:48.137195 139750589261632 run_squad.py:950] run_with_pdb: False
I1212 17:24:48.137233 139750589261632 run_squad.py:950] pdb_post_mortem: False
I1212 17:24:48.137271 139750589261632 run_squad.py:950] run_with_profiling: False
I1212 17:24:48.137310 139750589261632 run_squad.py:950] profile_file: None
I1212 17:24:48.137349 139750589261632 run_squad.py:950] use_cprofile_for_profiling: True
I1212 17:24:48.137388 139750589261632 run_squad.py:950] only_check_args: False
I1212 17:24:48.137426 139750589261632 run_squad.py:950] op_conversion_fallback_to_while_loop: False
I1212 17:24:48.137465 139750589261632 run_squad.py:950] test_random_seed: 301
I1212 17:24:48.137504 139750589261632 run_squad.py:950] test_srcdir:
I1212 17:24:48.137542 139750589261632 run_squad.py:950] test_tmpdir: /tmp/absl_testing
I1212 17:24:48.137581 139750589261632 run_squad.py:950] test_randomize_ordering_seed: None
I1212 17:24:48.137620 139750589261632 run_squad.py:950] xml_output_file:
I1212 17:24:48.137658 139750589261632 run_squad.py:950] bert_config_file: data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/bert_config.json
I1212 17:24:48.137696 139750589261632 run_squad.py:950] vocab_file: data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/vocab.txt
I1212 17:24:48.137734 139750589261632 run_squad.py:950] output_dir: /results/bert_large_gpu_1_sl_128_prec_fp16_bs_1
I1212 17:24:48.137772 139750589261632 run_squad.py:950] train_file: data/download/squad/v1.1/train-v1.1.json
I1212 17:24:48.137810 139750589261632 run_squad.py:950] predict_file: None
I1212 17:24:48.137849 139750589261632 run_squad.py:950] init_checkpoint: data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/bert_model.ckpt
I1212 17:24:48.137887 139750589261632 run_squad.py:950] do_lower_case: True
I1212 17:24:48.137926 139750589261632 run_squad.py:950] max_seq_length: 128
I1212 17:24:48.137964 139750589261632 run_squad.py:950] doc_stride: 64
I1212 17:24:48.138002 139750589261632 run_squad.py:950] max_query_length: 64
I1212 17:24:48.138040 139750589261632 run_squad.py:950] do_train: True
I1212 17:24:48.138079 139750589261632 run_squad.py:950] do_predict: False
I1212 17:24:48.138117 139750589261632 run_squad.py:950] train_batch_size: 1
I1212 17:24:48.138156 139750589261632 run_squad.py:950] predict_batch_size: 8
I1212 17:24:48.138199 139750589261632 run_squad.py:950] learning_rate: 5e-06
I1212 17:24:48.138237 139750589261632 run_squad.py:950] use_trt: False
I1212 17:24:48.138276 139750589261632 run_squad.py:950] horovod: False
I1212 17:24:48.138315 139750589261632 run_squad.py:950] num_train_epochs: 2.0
I1212 17:24:48.138354 139750589261632 run_squad.py:950] warmup_proportion: 0.1
I1212 17:24:48.138392 139750589261632 run_squad.py:950] save_checkpoints_steps: 1000
I1212 17:24:48.138430 139750589261632 run_squad.py:950] iterations_per_loop: 1000
I1212 17:24:48.138469 139750589261632 run_squad.py:950] num_accumulation_steps: 1
I1212 17:24:48.138506 139750589261632 run_squad.py:950] n_best_size: 20
I1212 17:24:48.138545 139750589261632 run_squad.py:950] max_answer_length: 30
I1212 17:24:48.138583 139750589261632 run_squad.py:950] verbose_logging: False
I1212 17:24:48.138622 139750589261632 run_squad.py:950] version_2_with_negative: False
I1212 17:24:48.138660 139750589261632 run_squad.py:950] null_score_diff_threshold: 0.0
I1212 17:24:48.138699 139750589261632 run_squad.py:950] use_fp16: True
I1212 17:24:48.138737 139750589261632 run_squad.py:950] use_xla: True
I1212 17:24:48.138775 139750589261632 run_squad.py:950] num_eval_iterations: None
I1212 17:24:48.138813 139750589261632 run_squad.py:950] export_trtis: False
I1212 17:24:48.138851 139750589261632 run_squad.py:950] trtis_model_name: bert
I1212 17:24:48.138890 139750589261632 run_squad.py:950] trtis_model_version: 1
I1212 17:24:48.138928 139750589261632 run_squad.py:950] trtis_server_url: localhost:8001
I1212 17:24:48.138966 139750589261632 run_squad.py:950] trtis_model_overwrite: False
I1212 17:24:48.139004 139750589261632 run_squad.py:950] trtis_max_batch_size: 8
I1212 17:24:48.139043 139750589261632 run_squad.py:950] trtis_dyn_batching_delay: 0.0
I1212 17:24:48.139081 139750589261632 run_squad.py:950] trtis_engine_count: 1
I1212 17:24:48.139120 139750589261632 run_squad.py:950] ?: False
I1212 17:24:48.139158 139750589261632 run_squad.py:950] help: False
I1212 17:24:48.139196 139750589261632 run_squad.py:950] helpshort: False
I1212 17:24:48.139235 139750589261632 run_squad.py:950] helpfull: False
I1212 17:24:48.139273 139750589261632 run_squad.py:950] helpxml: False
I1212 17:24:48.139307 139750589261632 run_squad.py:951] **************************
For this post, we measured fine-tuning performance (training and inference) for the BERT (Bidirectional Encoder Representations from Transformers) implementation in TensorFlow using NVIDIA Quadro RTX 8000 GPUs. For testing, we used an Exxact Valence Workstation fitted with 4x Quadro RTX 8000’s with NVLink, giving us 192 GB of GPU memory for our system. These tests measure performance for a popular use case for BERT and NLP in general and are meant to show typical GPU performance for such a task.
Benchmark scripts we used for evaluation was the finetune_train_benchmark.sh and finetune_inference_benchmark.sh from NVIDIA NGC Repository BERT for TensorFlow. We made slight modifications to the training benchmark script to get the larger batch size metrics.
The script runs multiple tests on the SQuAD v1.1 dataset using batch sizes 1, 2, 4, 8, 16, 32, and 64 for training, and 1, 2, 4, and 8 for inference. We conducted tests using 1, 2, and 4 GPU configurations on BERT Large (We used 1 GPU for inference benchmark). In addition, we ran all benchmarks using TensorFlow's XLA across all runs. Furthermore, other training settings can be viewed at the end of this blog in the Appendix/Additional Information section.
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size
[supsystic-tables id=56]
Run these benchmarks
Assuming you're using the NGC BERT for TensorFlow container, run the following command.
scripts/finetune_train_benchmark.sh large true 4 squad
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size
[supsystic-tables id=57]
Run these benchmarks
Assuming you're using the NGC BERT for TensorFlow container, run the following command.
scripts/finetune_train_benchmark.sh large true 2 squad
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size
[supsystic-tables id=58]
Run these benchmarks
Assuming you're using the NGC BERT for TensorFlow container, run the following command.
scripts/finetune_train_benchmark.sh large true 1 squad
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size
| Training Settings | Total Inference Time | Number of sentences | Latency Confidence Level 50ms | Latency Confidence Level 90 ms | Latency Confidence Level 95 ms | Latency Confidence Level 99 ms | Latency Confidence Level 100 ms | Latency Avg | Throughput (sentences/sec) |
| FP16 Seq 384, BS1 | 18.4 | 1042 | 17.9 | 18.33 | 18.59 | 19.25 | 21.78 | 17.66 | 56.64 |
| FP16 Seq 384, BS2 | 24.66 | 2068 | 23.54 | 24.16 | 24.37 | 25.28 | 637.7 | 23.85 | 83.87 |
| FP16 Seq 128, BS2 | 24.73 | 3402 | 15.07 | 16.17 | 16.47 | 17.07 | 22.4 | 14.54 | 137.57 |
| FP16 Seq 128, BS1 | 26.23 | 1800 | 15.42 | 16.56 | 16.76 | 17.6 | 20.43 | 14.57 | 68.36 |
| FP16 Seq 128, BS4 | 29.39 | 7128 | 16.13 | 16.84 | 17.2 | 17.89 | 687.32 | 16.49 | 242.54 |
| FP32 Seq 128, BS1 | 34.34 | 1800 | 20.93 | 22.66 | 23.16 | 24.63 | 28.59 | 19.08 | 52.41 |
| FP32 Seq 128, BS2 | 39.02 | 3402 | 23.1 | 23.92 | 24.15 | 24.71 | 29.27 | 22.94 | 87.18 |
| FP16 Seq 384, BS4 | 40.64 | 4128 | 39.09 | 39.71 | 39.93 | 41.64 | 624.06 | 39.38 | 101.58 |
| FP32 Seq 384, BS1 | 42.74 | 1042 | 42.77 | 44.19 | 44.3 | 44.54 | 46.82 | 41.02 | 24.38 |
| FP16 Seq 128, BS8 | 45.61 | 16040 | 22.68 | 23.4 | 23.71 | 24.43 | 531.04 | 22.75 | 351.67 |
| FP32 Seq 384, BS2 | 74.92 | 2068 | 73.38 | 74.53 | 74.68 | 74.95 | 90.78 | 72.46 | 27.6 |
| FP16 Seq 128, BS8 | 76.95 | 8432 | 72.57 | 74.13 | 74.46 | 75.62 | 624.44 | 73.01 | 109.58 |
| FP32 Seq 128, BS4 | 82.92 | 7128 | 47.23 | 48.57 | 48.71 | 49.23 | 208.24 | 46.53 | 85.96 |
| FP32 Seq 384, BS4 | 159.02 | 4128 | 156.41 | 159.25 | 159.95 | 160.72 | 175.58 | 154.09 | 25.96 |
| FP32 Seq 128, BS8 | 172.07 | 16040 | 86.33 | 87.54 | 87.71 | 88.23 | 98.14 | 85.82 | 93.33 |
| FP32 Seq 128, BS8 | 301.05 | 8432 | 287.52 | 289.06 | 289.48 | 291.17 | 499.43 | 285.62 | 28.01 |
Run these benchmarks
Assuming you're using the NGC BERT for TensorFlow container, run the following command.
scripts/finetune_inference_benchmark.sh large squad
| System | Exxact Valence Workstation |
| GPU | 4 x NVIDIA Quadro RTX 8000 |
| CPU | Intel CORE I7-7820X 3.6GHZ |
| RAM | 64GB DDR4 |
| SSD | 480 GB SSD |
| HDD (data) | 10 TB HDD |
| OS | Ubuntu 18.04 |
| NVIDIA DRIVER | 435.21 |
| CUDA Version | 10.1 |
| Python | 2.7/3.6 |
| TensorFlow | 1.14 |
| Container (usingNVIDIA Docker) | TensorFlow 19.08-py3+ NGC container |
NOTE: these will change with each run depending on batch size, sequence length, etc.
***** Configuaration *****
I1212 17:24:48.136919 139750589261632 run_squad.py:950] logtostderr: False
I1212 17:24:48.136960 139750589261632 run_squad.py:950] alsologtostderr: False
I1212 17:24:48.137000 139750589261632 run_squad.py:950] log_dir:
I1212 17:24:48.137040 139750589261632 run_squad.py:950] v: 0
I1212 17:24:48.137079 139750589261632 run_squad.py:950] verbosity: 0
I1212 17:24:48.137117 139750589261632 run_squad.py:950] stderrthreshold: fatal
I1212 17:24:48.137156 139750589261632 run_squad.py:950] showprefixforinfo: True
I1212 17:24:48.137195 139750589261632 run_squad.py:950] run_with_pdb: False
I1212 17:24:48.137233 139750589261632 run_squad.py:950] pdb_post_mortem: False
I1212 17:24:48.137271 139750589261632 run_squad.py:950] run_with_profiling: False
I1212 17:24:48.137310 139750589261632 run_squad.py:950] profile_file: None
I1212 17:24:48.137349 139750589261632 run_squad.py:950] use_cprofile_for_profiling: True
I1212 17:24:48.137388 139750589261632 run_squad.py:950] only_check_args: False
I1212 17:24:48.137426 139750589261632 run_squad.py:950] op_conversion_fallback_to_while_loop: False
I1212 17:24:48.137465 139750589261632 run_squad.py:950] test_random_seed: 301
I1212 17:24:48.137504 139750589261632 run_squad.py:950] test_srcdir:
I1212 17:24:48.137542 139750589261632 run_squad.py:950] test_tmpdir: /tmp/absl_testing
I1212 17:24:48.137581 139750589261632 run_squad.py:950] test_randomize_ordering_seed: None
I1212 17:24:48.137620 139750589261632 run_squad.py:950] xml_output_file:
I1212 17:24:48.137658 139750589261632 run_squad.py:950] bert_config_file: data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/bert_config.json
I1212 17:24:48.137696 139750589261632 run_squad.py:950] vocab_file: data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/vocab.txt
I1212 17:24:48.137734 139750589261632 run_squad.py:950] output_dir: /results/bert_large_gpu_1_sl_128_prec_fp16_bs_1
I1212 17:24:48.137772 139750589261632 run_squad.py:950] train_file: data/download/squad/v1.1/train-v1.1.json
I1212 17:24:48.137810 139750589261632 run_squad.py:950] predict_file: None
I1212 17:24:48.137849 139750589261632 run_squad.py:950] init_checkpoint: data/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/bert_model.ckpt
I1212 17:24:48.137887 139750589261632 run_squad.py:950] do_lower_case: True
I1212 17:24:48.137926 139750589261632 run_squad.py:950] max_seq_length: 128
I1212 17:24:48.137964 139750589261632 run_squad.py:950] doc_stride: 64
I1212 17:24:48.138002 139750589261632 run_squad.py:950] max_query_length: 64
I1212 17:24:48.138040 139750589261632 run_squad.py:950] do_train: True
I1212 17:24:48.138079 139750589261632 run_squad.py:950] do_predict: False
I1212 17:24:48.138117 139750589261632 run_squad.py:950] train_batch_size: 1
I1212 17:24:48.138156 139750589261632 run_squad.py:950] predict_batch_size: 8
I1212 17:24:48.138199 139750589261632 run_squad.py:950] learning_rate: 5e-06
I1212 17:24:48.138237 139750589261632 run_squad.py:950] use_trt: False
I1212 17:24:48.138276 139750589261632 run_squad.py:950] horovod: False
I1212 17:24:48.138315 139750589261632 run_squad.py:950] num_train_epochs: 2.0
I1212 17:24:48.138354 139750589261632 run_squad.py:950] warmup_proportion: 0.1
I1212 17:24:48.138392 139750589261632 run_squad.py:950] save_checkpoints_steps: 1000
I1212 17:24:48.138430 139750589261632 run_squad.py:950] iterations_per_loop: 1000
I1212 17:24:48.138469 139750589261632 run_squad.py:950] num_accumulation_steps: 1
I1212 17:24:48.138506 139750589261632 run_squad.py:950] n_best_size: 20
I1212 17:24:48.138545 139750589261632 run_squad.py:950] max_answer_length: 30
I1212 17:24:48.138583 139750589261632 run_squad.py:950] verbose_logging: False
I1212 17:24:48.138622 139750589261632 run_squad.py:950] version_2_with_negative: False
I1212 17:24:48.138660 139750589261632 run_squad.py:950] null_score_diff_threshold: 0.0
I1212 17:24:48.138699 139750589261632 run_squad.py:950] use_fp16: True
I1212 17:24:48.138737 139750589261632 run_squad.py:950] use_xla: True
I1212 17:24:48.138775 139750589261632 run_squad.py:950] num_eval_iterations: None
I1212 17:24:48.138813 139750589261632 run_squad.py:950] export_trtis: False
I1212 17:24:48.138851 139750589261632 run_squad.py:950] trtis_model_name: bert
I1212 17:24:48.138890 139750589261632 run_squad.py:950] trtis_model_version: 1
I1212 17:24:48.138928 139750589261632 run_squad.py:950] trtis_server_url: localhost:8001
I1212 17:24:48.138966 139750589261632 run_squad.py:950] trtis_model_overwrite: False
I1212 17:24:48.139004 139750589261632 run_squad.py:950] trtis_max_batch_size: 8
I1212 17:24:48.139043 139750589261632 run_squad.py:950] trtis_dyn_batching_delay: 0.0
I1212 17:24:48.139081 139750589261632 run_squad.py:950] trtis_engine_count: 1
I1212 17:24:48.139120 139750589261632 run_squad.py:950] ?: False
I1212 17:24:48.139158 139750589261632 run_squad.py:950] help: False
I1212 17:24:48.139196 139750589261632 run_squad.py:950] helpshort: False
I1212 17:24:48.139235 139750589261632 run_squad.py:950] helpfull: False
I1212 17:24:48.139273 139750589261632 run_squad.py:950] helpxml: False
I1212 17:24:48.139307 139750589261632 run_squad.py:951] **************************



