Benchmarks
NVIDIA RTX 2080 Ti Benchmarks for Deep Learning with TensorFlow: Updated with XLA & FP16
May 23, 2019
28 min read


For this blog article, we conducted more extensive deep learning performance benchmarks for TensorFlow on NVIDIA GeForce RTX 2080 Ti GPUs. We recently discovered that the XLA library (Accelerated Linear Algebra) adds significant performance gains, and felt it was worth running the numbers again. Our Exxact Valence Workstation was fitted with 4x RTX 2080 Ti's and ran the standard "tf_cnn_benchmarks.py" benchmark script found here in the official TensorFlow github. We tested on the the following networks: ResNet50, ResNet152, Inception v3, Inception v4, VGG-16, AlexNet, and Nasnet. Also, we compared FP16 to FP32 performance, and compared numbers using the XLA flag. Furthermore, ran the same tests using 1,2, and 4 GPU configurations. Batch size was largest that could fit into available GPU memory (powers of two).
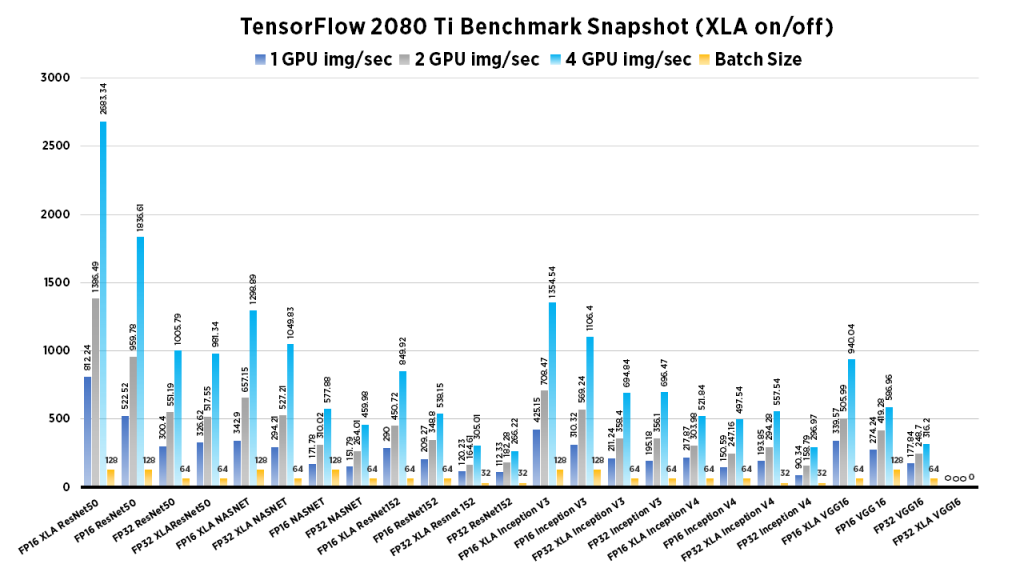

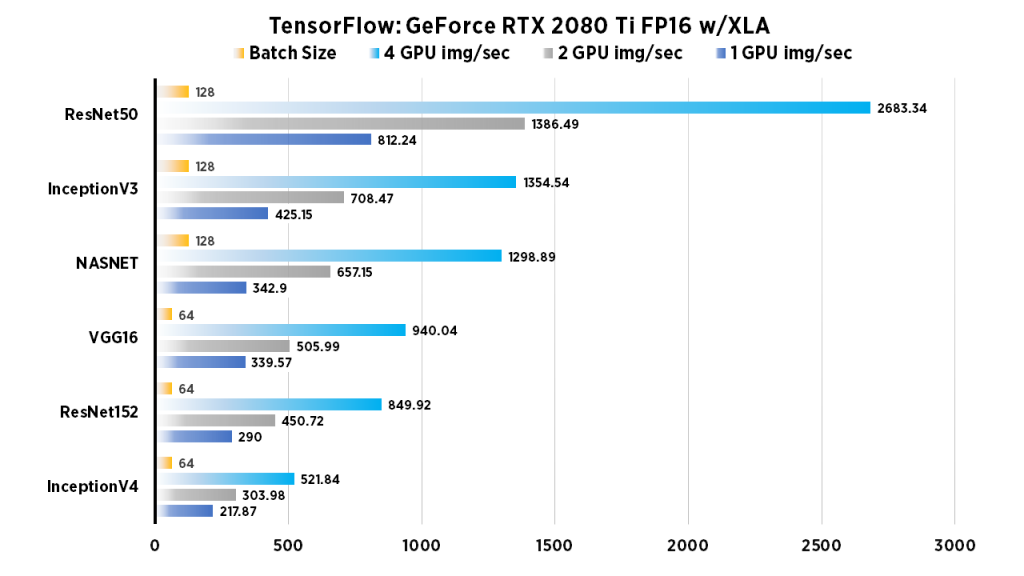
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| InceptionV4 | 217.87 | 303.98 | 521.84 | 64 |
| ResNet152 | 290 | 450.72 | 849.92 | 64 |
| VGG16 | 339.57 | 505.99 | 940.04 | 64 |
| NASNET | 342.9 | 657.15 | 1298.89 | 128 |
| InceptionV3 | 425.15 | 708.47 | 1354.54 | 128 |
| ResNet50 | 812.24 | 1386.49 | 2683.34 | 128 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=64 --num_batches=100 --model=inception4 --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --use_fp16=True --nodistortions --gradient_repacking=2 --datasets_use_prefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
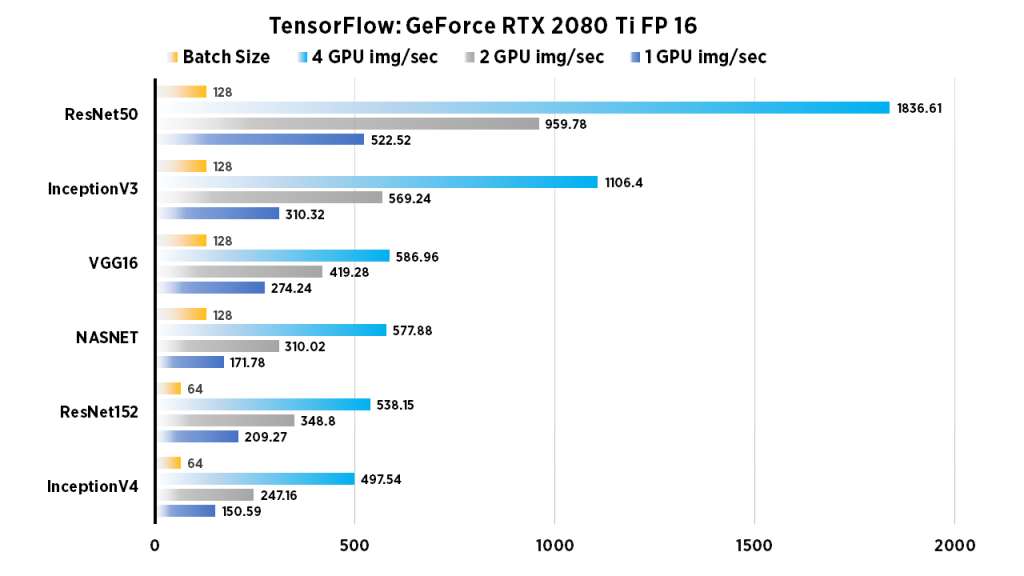
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| InceptionV4 | 150.59 | 247.16 | 497.54 | 64 |
| ResNet152 | 209.27 | 348.8 | 538.15 | 64 |
| NASNET | 171.78 | 310.02 | 577.88 | 128 |
| VGG16 | 274.24 | 419.28 | 586.96 | 128 |
| InceptionV3 | 310.32 | 569.24 | 1106.4 | 128 |
| ResNet50 | 522.52 | 959.78 | 1836.61 | 128 |

Run these benchmarks
To run these, set the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=128 --model=resnet50 --variable_update=parameter_server --use_fp16=True
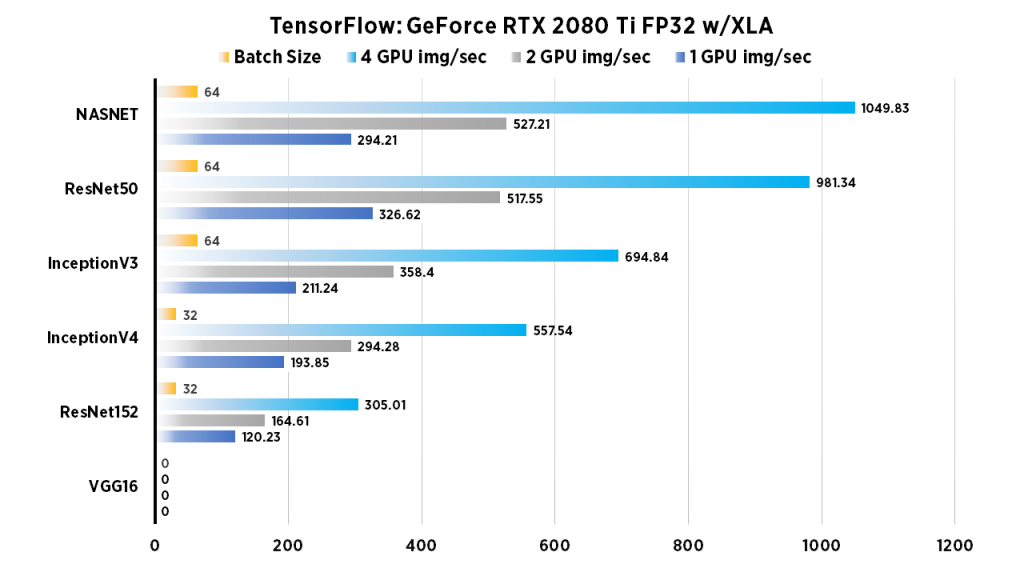
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| VGG16 | error | error | error | error |
| ResNet152 | 120.23 | 164.61 | 305.01 | 32 |
| InceptionV4 | 193.85 | 294.28 | 557.54 | 32 |
| InceptionV3 | 211.24 | 358.4 | 694.84 | 64 |
| ResNet50 | 326.62 | 517.55 | 981.34 | 64 |
| NASNET | 294.21 | 527.21 | 1049.83 | 64 |
Run these benchmarks
To run XLA FP32, set num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=64 --num_batches=100 --model=resnet50 --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --nodistortions --gradient_repacking=2 --datasets_use_prefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
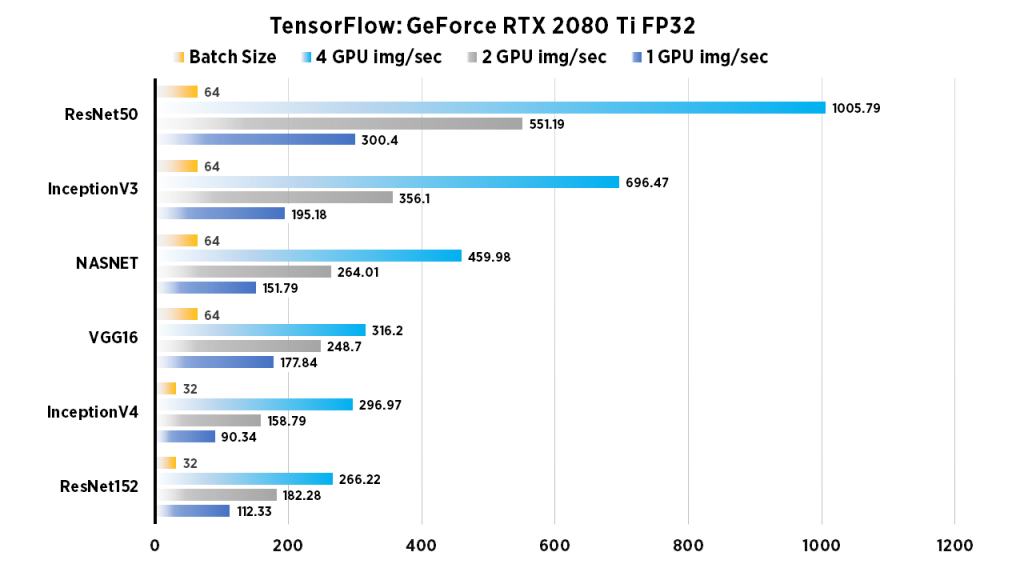
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet152 | 112.33 | 182.28 | 266.22 | 32 |
| InceptionV4 | 90.34 | 158.79 | 296.97 | 32 |
| VGG16 | 177.84 | 248.7 | 316.2 | 64 |
| NASNET | 151.79 | 264.01 | 459.98 | 64 |
| InceptionV3 | 195.18 | 356.1 | 696.47 | 64 |
| ResNet50 | 300.4 | 551.19 | 1005.79 | 64 |
Run these benchmarks
Set the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=64 --model=resnet50 --variable_update=parameter_server
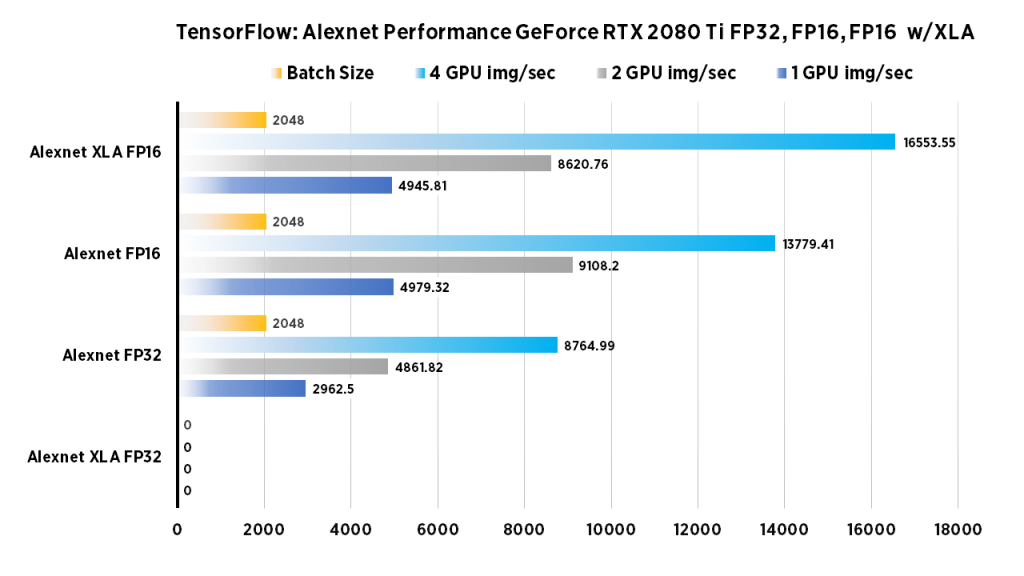
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| Alexnet FP32 | 2962.5 | 4861.82 | 8764.99 | 2048 |
| Alexnet XLA FP32 | error | error | error | error |
| Alexnet FP16 | 4979.32 | 9108.2 | 13779.41 | 2048 |
| Alexnet XLA FP16 | 4945.81 | 8620.76 | 16553.55 | 2048 |
How to run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=2048 --model=alexnet --variable_update=parameter_server --use_fp16=True
To run these benchmarks with XLA
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=2048 --num_batches=100 --model=alexnet --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --use_fp16=True --nodistortions --gradient_repacking=2 --datasets_use_prefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
| System | Exxact Valence Workstation |
| GPU | 4 x NVIDIA GeForce RTX 2080 Ti |
| CPU | Intel CORE I7-7820X 3.6GHZ |
| RAM | 32GB DDR4 |
| SSD | 480 GB SSD |
| HDD (data) | 10 TB HDD |
| OS | Ubuntu 18.04 |
| NVIDIA DRIVER | 418.43 |
| CUDA Version | 10.1 |
| Python | 2.7, 3.7 |
| TensorFlow | 1.14 |
| Docker Image | tensorflow/tensorflow:nightly-gpu |
| Dataset: | Imagenet (synthetic) |
|---|---|
| Mode: | training |
| SingleSess: | False |
| Batch Size: | Varied |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | sgd |
| Variables: | parameter_server |
| Dataset: | Imagenet (synthetic) |
|---|---|
| Mode: | training |
| SingleSess: | False |
| Batch Size: | Varied |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | momentum |
| Variables: | replicated |
| AllReduce | nccl |
Interested in our deep learning systems? Contact our sales team here.
For this blog article, we conducted more extensive deep learning performance benchmarks for TensorFlow on NVIDIA GeForce RTX 2080 Ti GPUs. We recently discovered that the XLA library (Accelerated Linear Algebra) adds significant performance gains, and felt it was worth running the numbers again. Our Exxact Valence Workstation was fitted with 4x RTX 2080 Ti's and ran the standard "tf_cnn_benchmarks.py" benchmark script found here in the official TensorFlow github. We tested on the the following networks: ResNet50, ResNet152, Inception v3, Inception v4, VGG-16, AlexNet, and Nasnet. Also, we compared FP16 to FP32 performance, and compared numbers using the XLA flag. Furthermore, ran the same tests using 1,2, and 4 GPU configurations. Batch size was largest that could fit into available GPU memory (powers of two).
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| InceptionV4 | 217.87 | 303.98 | 521.84 | 64 |
| ResNet152 | 290 | 450.72 | 849.92 | 64 |
| VGG16 | 339.57 | 505.99 | 940.04 | 64 |
| NASNET | 342.9 | 657.15 | 1298.89 | 128 |
| InceptionV3 | 425.15 | 708.47 | 1354.54 | 128 |
| ResNet50 | 812.24 | 1386.49 | 2683.34 | 128 |
Run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=64 --num_batches=100 --model=inception4 --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --use_fp16=True --nodistortions --gradient_repacking=2 --datasets_use_prefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| InceptionV4 | 150.59 | 247.16 | 497.54 | 64 |
| ResNet152 | 209.27 | 348.8 | 538.15 | 64 |
| NASNET | 171.78 | 310.02 | 577.88 | 128 |
| VGG16 | 274.24 | 419.28 | 586.96 | 128 |
| InceptionV3 | 310.32 | 569.24 | 1106.4 | 128 |
| ResNet50 | 522.52 | 959.78 | 1836.61 | 128 |
Run these benchmarks
To run these, set the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=128 --model=resnet50 --variable_update=parameter_server --use_fp16=True
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| VGG16 | error | error | error | error |
| ResNet152 | 120.23 | 164.61 | 305.01 | 32 |
| InceptionV4 | 193.85 | 294.28 | 557.54 | 32 |
| InceptionV3 | 211.24 | 358.4 | 694.84 | 64 |
| ResNet50 | 326.62 | 517.55 | 981.34 | 64 |
| NASNET | 294.21 | 527.21 | 1049.83 | 64 |
Run these benchmarks
To run XLA FP32, set num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=64 --num_batches=100 --model=resnet50 --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --nodistortions --gradient_repacking=2 --datasets_use_prefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| ResNet152 | 112.33 | 182.28 | 266.22 | 32 |
| InceptionV4 | 90.34 | 158.79 | 296.97 | 32 |
| VGG16 | 177.84 | 248.7 | 316.2 | 64 |
| NASNET | 151.79 | 264.01 | 459.98 | 64 |
| InceptionV3 | 195.18 | 356.1 | 696.47 | 64 |
| ResNet50 | 300.4 | 551.19 | 1005.79 | 64 |
Run these benchmarks
Set the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=64 --model=resnet50 --variable_update=parameter_server
| 1 GPU img/sec | 2 GPU img/sec | 4 GPU img/sec | Batch Size | |
| Alexnet FP32 | 2962.5 | 4861.82 | 8764.99 | 2048 |
| Alexnet XLA FP32 | error | error | error | error |
| Alexnet FP16 | 4979.32 | 9108.2 | 13779.41 | 2048 |
| Alexnet XLA FP16 | 4945.81 | 8620.76 | 16553.55 | 2048 |
How to run these benchmarks
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --num_gpus=1 --batch_size=2048 --model=alexnet --variable_update=parameter_server --use_fp16=True
To run these benchmarks with XLA
Configure the num_gpus to the number of GPUs desired to test. Change model to desired architecture.
python tf_cnn_benchmarks.py --data_format=NCHW --batch_size=2048 --num_batches=100 --model=alexnet --optimizer=momentum --variable_update=replicated --all_reduce_spec=nccl --use_fp16=True --nodistortions --gradient_repacking=2 --datasets_use_prefetch=True --per_gpu_thread_count=2 --loss_type_to_report=base_loss --compute_lr_on_cpu=True --single_l2_loss_op=True --xla_compile=True --local_parameter_device=gpu --num_gpus=1 --display_every=10
| System | Exxact Valence Workstation |
| GPU | 4 x NVIDIA GeForce RTX 2080 Ti |
| CPU | Intel CORE I7-7820X 3.6GHZ |
| RAM | 32GB DDR4 |
| SSD | 480 GB SSD |
| HDD (data) | 10 TB HDD |
| OS | Ubuntu 18.04 |
| NVIDIA DRIVER | 418.43 |
| CUDA Version | 10.1 |
| Python | 2.7, 3.7 |
| TensorFlow | 1.14 |
| Docker Image | tensorflow/tensorflow:nightly-gpu |
| Dataset: | Imagenet (synthetic) |
|---|---|
| Mode: | training |
| SingleSess: | False |
| Batch Size: | Varied |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | sgd |
| Variables: | parameter_server |
| Dataset: | Imagenet (synthetic) |
|---|---|
| Mode: | training |
| SingleSess: | False |
| Batch Size: | Varied |
| Num Batches: | 100 |
| Num Epochs: | 0.08 |
| Devices: | ['/gpu:0']...(varied) |
| NUMA bind: | False |
| Data format: | NCHW |
| Optimizer: | momentum |
| Variables: | replicated |
| AllReduce | nccl |
Interested in our deep learning systems? Contact our sales team here.
