Deep Learning
A Deep Dive Into the Transformer Architecture – The Development of Transformer Models
July 14, 2020
17 min read


It may seem like a long time since the world of natural language processing (NLP) was transformed by the seminal “Attention is All You Need” paper by Vaswani et al., but in fact that was less than 3 years ago. The relative recency of the introduction of transformer architectures and the ubiquity with which they have upended language tasks speaks to the rapid rate of progress in machine learning and artificial intelligence. There’s no better time than now to gain a deep understanding of the inner workings of transformer architectures, especially with transformer models making big inroads into diverse new applications like predicting chemical reactions and reinforcement learning.
Whether you’re an old hand or you’re only paying attention to transformer style architecture for the first time, this article should offer something for you. First, we’ll dive deep into the fundamental concepts used to build the original 2017 Transformer. Then we’ll touch on some of the developments implemented in subsequent transformer models. Where appropriate we’ll point out some limitations and how modern models inheriting ideas from the original Transformer are trying to overcome various shortcomings or improve performance.

Transformers are the current state-of-the-art type of model for dealing with sequences. Perhaps the most prominent application of these models is in text processing tasks, and the most prominent of these is machine translation. In fact, transformers and their conceptual progeny have infiltrated just about every benchmark leaderboard in natural language processing (NLP), from question answering to grammar correction. In many ways transformer architectures are undergoing a surge in development similar to what we saw with convolutional neural networks following the 2012 ImageNet competition, for better and for worse.

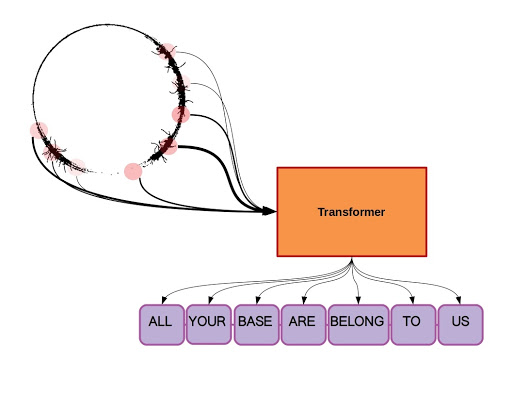
Transformer represented as a black box. An entire sequence of (x’s in the diagram) is parsed simultaneously in feed-forward manner, producing a transformed output tensor. In this diagram the output sequence is more concise than the input sequence. For practical NLP tasks, word order and sentence length may vary substantially.
Unlike previous state-of-the-art architectures for NLP, such as the many variants of RNNs and LSTMs, there are no recurrent connections and thus no real memory of previous states. Transformers get around this lack of memory by perceiving entire sequences simultaneously. Perhaps a transformer neural network perceives the world a bit like the aliens in the movie Arrival. Strictly speaking the future elements are usually masked out during training, but other than that the model is free to learn long-term semantic dependencies throughout the entire sequence.
Transformers do away with recurrent connections and parse entire sequences simultaneously, sort of like the Heptapods in Arrival. You can make your own logograms using the open source python2 repository by FlxB2 (https://github.com/FlxB2/arrival_logograms).
Operating as feed-forward-only models, transformers require a slightly different approach to hardware. Transformers are actually much better suited to run on modern machine learning accelerators, because unlike recurrent networks there is no sequential processing: the model doesn’t have to process a string of elements in order to develop a useful hidden cell state. Transformers can require a lot of memory during training, but running training or inference at reduced precision can help to alleviate memory requirements.
Transfer learning is an important shortcut to state-of-the-art performance on a given text-based task, and quite frankly necessary for most practitioners on realistic budgets. Energy and financial costs of training a large modern transformer can easily dwarf an individual researcher’s total yearly energy consumption, at a cost of thousands of dollars if using cloud compute. Luckily, similar to deep learning for computer vision, the new skills needed for a specialized task can be transferred to large pre-trained transformers, e.g. downloaded from the HuggingFace repository.
The secret sauce in transformer architectures is the incorporation of some sort of attention mechanism, and the 2017 original is no exception. To avoid confusion, we’ll refer to the model demonstrated by Vaswani et al. as either just Transformer or as vanilla Transformer to distinguish it from successors with similar names like Transformer-XL. We’ll start by looking at the attention mechanism and build outward to a high-level view of the entire model.
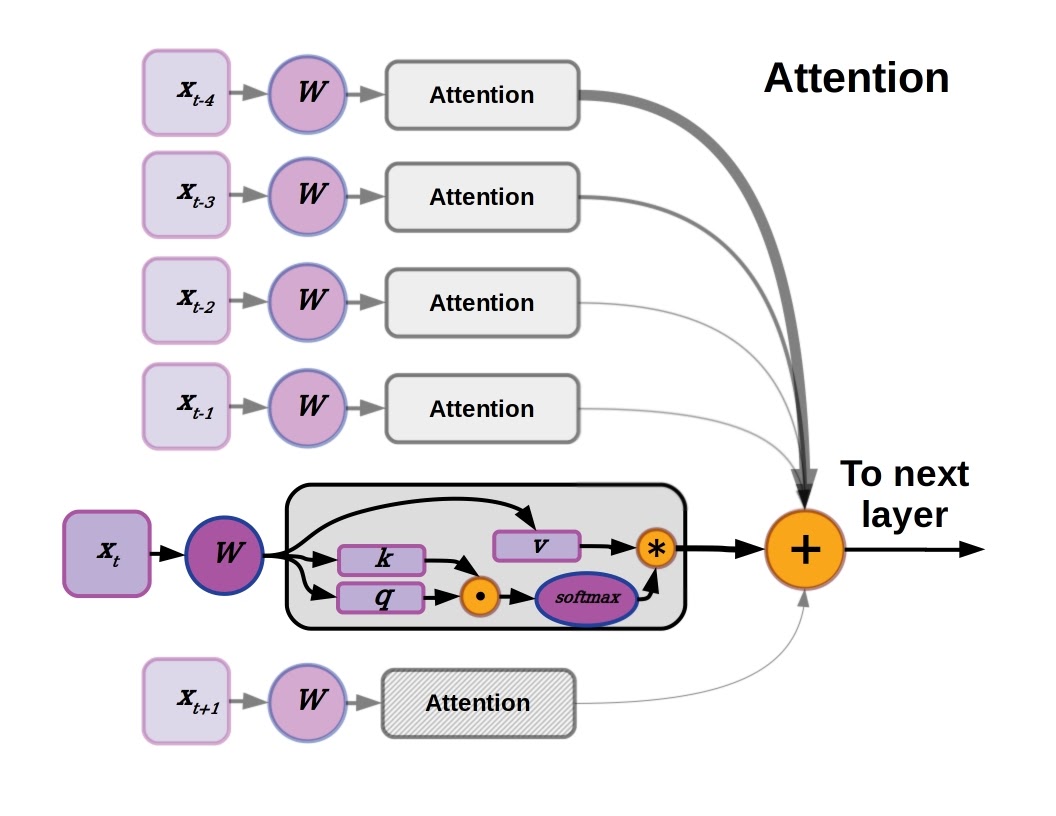
Attention is a means of selectively weighting different elements in input data, so that they will have an adjusted impact on the hidden states of downstream layers. The vanilla Transformer implements attention by parsing input word vectors into key, query, and value vectors. The dot product of the key and query provide the attention weight, which is squashed using a softmax function across all attention weights so that the total weighting sums to 1. The value vectors corresponding to each element are summed according to their attention weights before being fed into subsequent layers. That may be a bit complicated to take in all at once, so let’s zoom in and go through it step-by-step.

Starting with a sequence of words forming a sentence, each element (word) in the sequence is first converted to an embedded representation called a word vector. Word vector embedding is a much more nuanced representation than something like a one-hot encoded bag-of-words model, like used by Salakhutidinov and Hinton in their 2007 Semantic Hashing paper.
Word embeddings (also sometimes called tokens) are useful because they impart semantic meaning in a numerical way that can be understood by neural networks. Learned word embeddings can contain contextual and relational information, for example as the semantic relationship between “dog” and “puppy” is roughly equivalent to “cat” and “kitten,” so we may be able to manipulate their word embeddings like so:

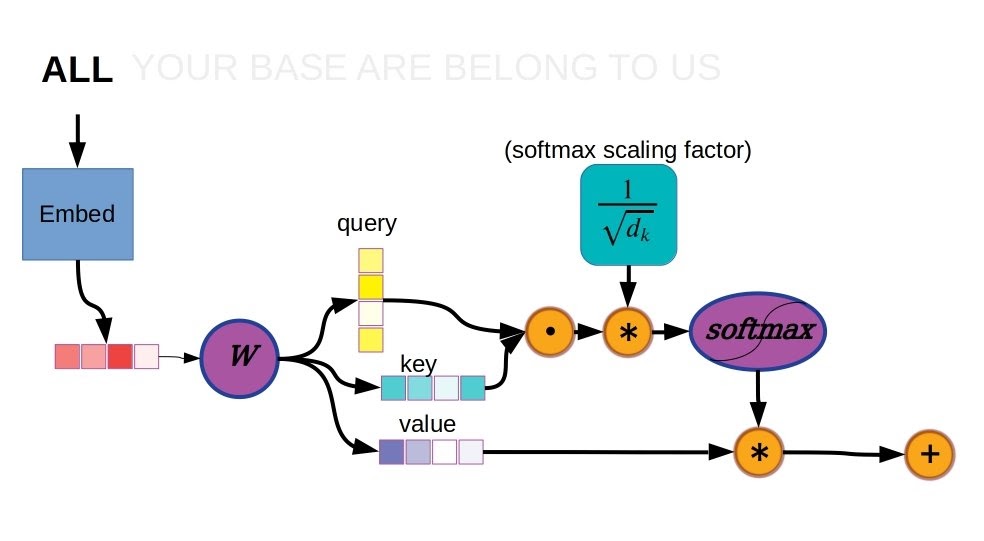
Vanilla Transformer attention mechanism detail.
Starting from the top left in the diagram above, an input word is first tokenized by an embedding function, replacing the string “ALL” with a numerical vector which will be the input to the attention layer. Note that the only layer which has an embedding function is the first encoder, every other layer just takes the preceding output vectors as inputs. The attention layer (W in the diagram) computes three vectors based on the input, termed key, query, and value. The dot product of key and query, a scalar, is the relative weighting for a given position.
The attention mechanism is applied in parallel at every element in the sequence, so every other element also has an attention score as well. These attention scores are subjected to a softmax function to ensure that the total weighting sums to 1.0, and then multiplied with the corresponding value vector. The values for all elements, now weighted by their attention scores, are summed together. The resulting vector is the new value in a sequence of vectors forming an internal representation of the input sequence, which will then be passed to a feed-forward fully connected layer.
Another important detail that may have gotten lost so far is the scaling factor used to stabilize the softmax function, i.e. before inputting values to the softmax function used by the attention layers, the numbers are scaled inversely proportional to the square root of the number of units in the key vector. This is important for making learning work well regardless of the size of the key and query vectors. Without a scaling factor the dot product will tend to be a large value when using long key and query vectors, pushing the gradient of the softmax function into a relatively flat area and making it difficult for error information to propagate.

As mentioned earlier, a useful consequence of doing away with recurrent connections is that the entire sequence can be processed at once in a feed-forward manner. When we combine the self-attention layer described above with a dense feed-forward layer, we get one encoder layer. The feed-forward layer is composed of two linear layers with a rectified linear unit (ReLU) in between them. That is to say the input is first transformed by a linear layer (matrix multiply), the resulting values are then clipped to always be 0 or greater, and finally the result is fed into a second linear layer to produce the feed-forward layer output.
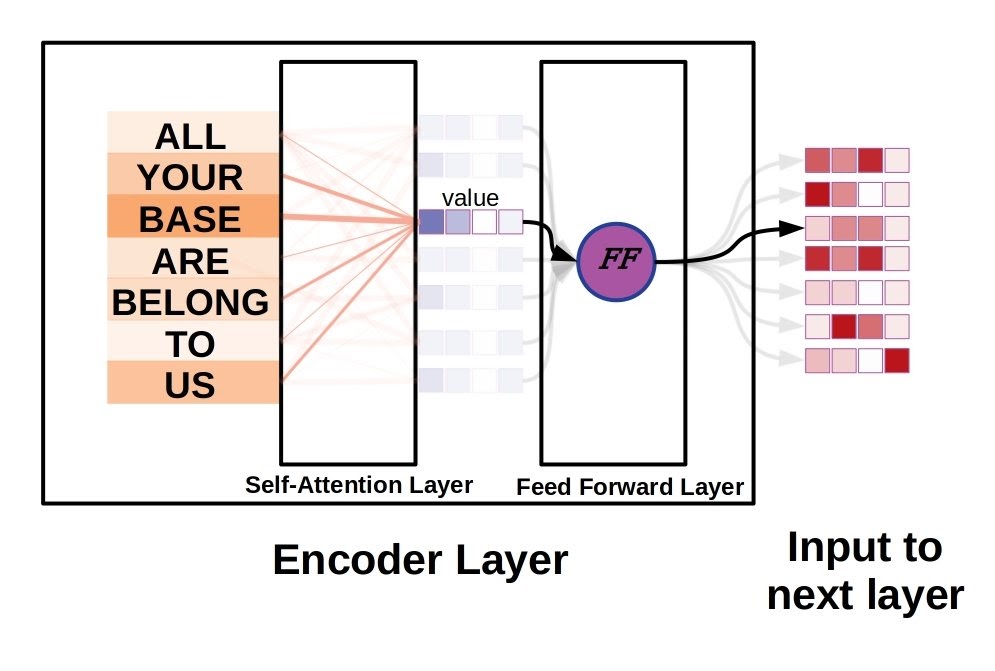
Vanilla Transformer uses six of these encoder layers (self-attention layer + feed forward layer), followed by six decoder layers. Transformer uses a variant of self-attention called multi-headed attention, so in fact the attention layer will compute 8 different key, query, value vector sets for each sequence element. These will then be concatenated into one matrix, and put through another matrix multiply that yields the properly sized output vector.
Decoder layers share many of the features we saw in encoder layers, but with the addition of a second attention layer, the so-called encoder-decoder attention layer. Unlike the self-attention layer, only the query vectors come from the decoder layer itself. The key and value vectors are taken from the output of the encoder stack. Decoder layers also each contain a self-attention layer, just like we saw in the encoder, and the queries, keys, and values feeding into the self-attention layer are generated in the decoder stack.
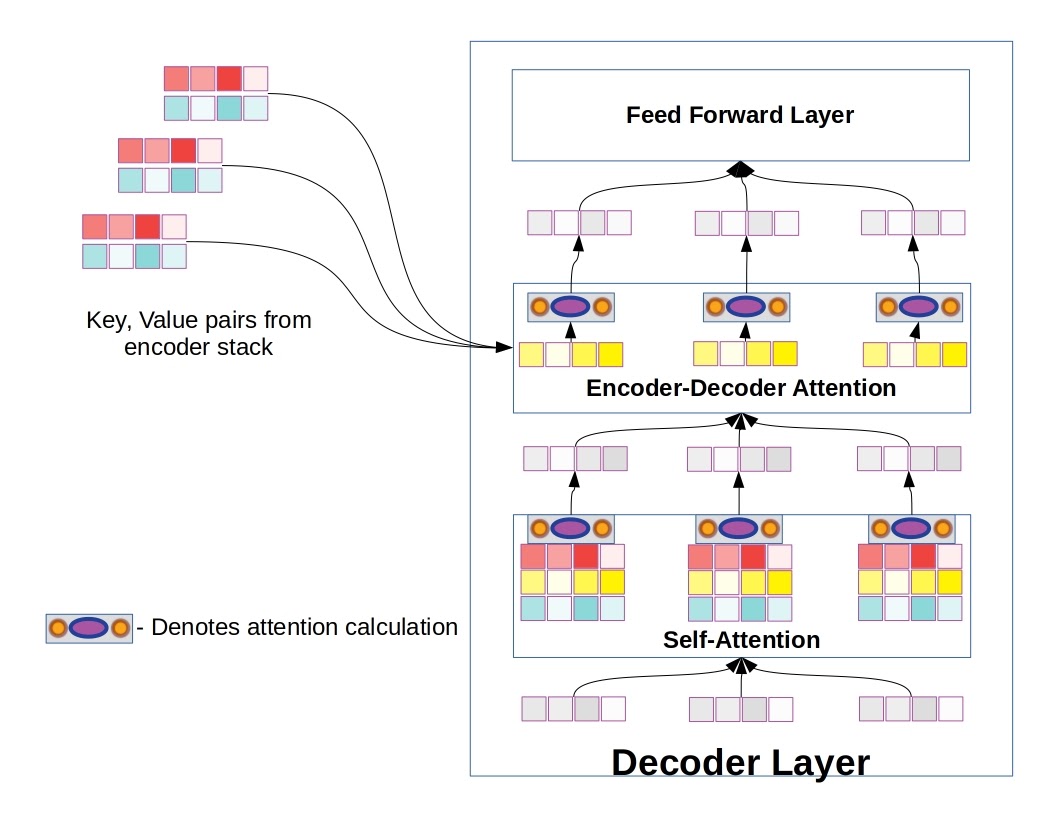
Decoder layer, differing from encoder layers in the addition of a encoder-decoder attention sub-layer. Six of these make up the decoder in vanilla Transformer.
Now we have recipes for both encoder and decoder layers. To build a transformer out of these components, we have only to make two stacks, each with either six encoder layers or six decoder layers. The output of the encoder stack flows into the decoder stack, and each layer in the decoder stack also has access to the output from the encoders. But there are just a few details left to fully understand how the vanilla Transformer is put together.
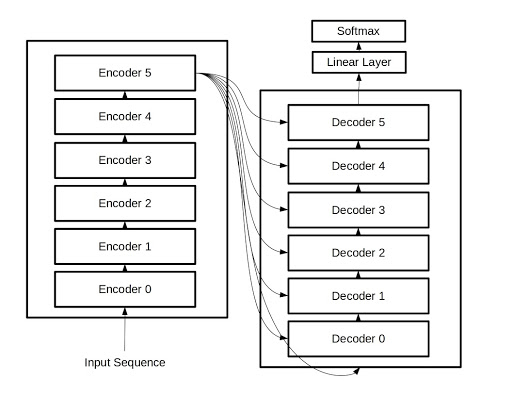
Overview of the full Transformer.
Like many other extremely deep neural networks with many parameters, training them can sometimes be difficult when gradients don’t flow through from input to outputs as well as we’d like. In computer vision, this led to the powerful ResNet style of convolutional neural networks. ResNets, short for residual networks, explicitly add the input from the last layer to its own output. In this way the residuals are retained through the entire stack of layers and gradients can more easily flow from the loss function at the output all the way back to the inputs. DenseNet architectures aim to solve the same problem by concatenating input tensors and output tensors together, instead of adding. In the vanilla Transformer model, the residual summing operation is followed by layer normalization, a method for improving training that, unlike batch normalization, is not sensitive to minibatch size.
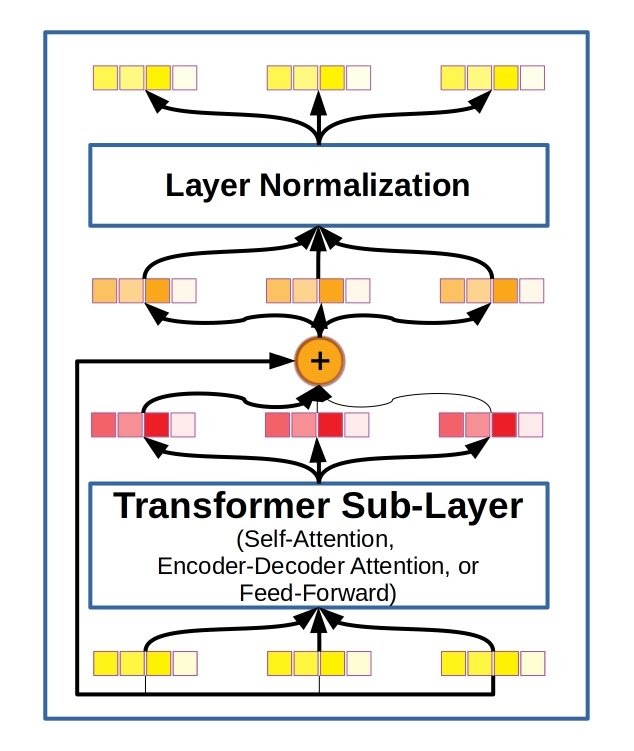
Diagram of residual connections and layer normalization. Every sub-layer in the encoder and decoder layers of vanilla Transformer incorporated this scheme.
In recurrent architectures like LSTMs the model can essentially learn to count and gauge sequence distances internally. Vanilla Transformer doesn’t use recurrent connections and perceives entire sequences simultaneously, so how does it learn which element came from which part of the sequence, especially when sequence length is allowed to vary? The answer is a positional encoding based on a decaying sinusoidal function that is concatenated to the sequence element embeddings. Vaswani et al. also experimented with learned positional encodings with almost identical results, but reasoned that using sinusoidal encodings should allow the model to generalize better to sequence lengths not seen during training.
The introduction of the vanilla Transformer in 2017 disrupted sequence-based deep learning significantly. By doing away with recurrent connections entirely, transformer architectures are better suited for massively parallel computation on modern machine learning acceleration hardware. It’s surprising that vanilla Transformer could learn long-term dependencies in a sequence at all, and in fact there is an upper limit to the distances over which vanilla Transformer can easily learn relationships.
Transformer-XL was introduced by Dai et al. In 2019 to address this problem with a new positional encoding, and also incorporated a sort of pseudo-recurrent connection where the key and value vectors depend in part on the previous hidden state as well as the current one. Additional transformer variants include decoder-only transformers (e.g. OpenAI’s GPT and GPT-2), adding bidirectionality (i.e. BERT-based transformers), among others. Transformers were designed for sequences and have found their most prominent applications in natural language processing, but transformer architectures have also been adapted for image generation, reinforcement learning (by modifying Transformer-XL), and for chemistry.
Hopefully this post has helped you to build intuition for working with modern transformer architectures for NLP and beyond. But you don’t have to be a hero and build and train a new transformer from scratch in order to try out your own ideas. Open source repositories like HuggingFace provide pre-trained models that you can fine-tune to fuel your NLP projects. Google has provided a notebook you can use to tinker with transformer models in their tensor2tensor library. And of course you can always talk to transformer or play a text-based dungeon adventure game with OpenAI’s GPT-2 as dungeon master. Depending on your preferred level of abstraction the above resources may be more than enough, but if you won’t be happy until you put code to concepts you may be interested in a code-annotated version of the paper from Alexander Rush and others at the Harvard NLP lab.
Happy transforming!

It may seem like a long time since the world of natural language processing (NLP) was transformed by the seminal “Attention is All You Need” paper by Vaswani et al., but in fact that was less than 3 years ago. The relative recency of the introduction of transformer architectures and the ubiquity with which they have upended language tasks speaks to the rapid rate of progress in machine learning and artificial intelligence. There’s no better time than now to gain a deep understanding of the inner workings of transformer architectures, especially with transformer models making big inroads into diverse new applications like predicting chemical reactions and reinforcement learning.
Whether you’re an old hand or you’re only paying attention to transformer style architecture for the first time, this article should offer something for you. First, we’ll dive deep into the fundamental concepts used to build the original 2017 Transformer. Then we’ll touch on some of the developments implemented in subsequent transformer models. Where appropriate we’ll point out some limitations and how modern models inheriting ideas from the original Transformer are trying to overcome various shortcomings or improve performance.
Transformers are the current state-of-the-art type of model for dealing with sequences. Perhaps the most prominent application of these models is in text processing tasks, and the most prominent of these is machine translation. In fact, transformers and their conceptual progeny have infiltrated just about every benchmark leaderboard in natural language processing (NLP), from question answering to grammar correction. In many ways transformer architectures are undergoing a surge in development similar to what we saw with convolutional neural networks following the 2012 ImageNet competition, for better and for worse.
Transformer represented as a black box. An entire sequence of (x’s in the diagram) is parsed simultaneously in feed-forward manner, producing a transformed output tensor. In this diagram the output sequence is more concise than the input sequence. For practical NLP tasks, word order and sentence length may vary substantially.
Unlike previous state-of-the-art architectures for NLP, such as the many variants of RNNs and LSTMs, there are no recurrent connections and thus no real memory of previous states. Transformers get around this lack of memory by perceiving entire sequences simultaneously. Perhaps a transformer neural network perceives the world a bit like the aliens in the movie Arrival. Strictly speaking the future elements are usually masked out during training, but other than that the model is free to learn long-term semantic dependencies throughout the entire sequence.
Transformers do away with recurrent connections and parse entire sequences simultaneously, sort of like the Heptapods in Arrival. You can make your own logograms using the open source python2 repository by FlxB2 (https://github.com/FlxB2/arrival_logograms).
Operating as feed-forward-only models, transformers require a slightly different approach to hardware. Transformers are actually much better suited to run on modern machine learning accelerators, because unlike recurrent networks there is no sequential processing: the model doesn’t have to process a string of elements in order to develop a useful hidden cell state. Transformers can require a lot of memory during training, but running training or inference at reduced precision can help to alleviate memory requirements.
Transfer learning is an important shortcut to state-of-the-art performance on a given text-based task, and quite frankly necessary for most practitioners on realistic budgets. Energy and financial costs of training a large modern transformer can easily dwarf an individual researcher’s total yearly energy consumption, at a cost of thousands of dollars if using cloud compute. Luckily, similar to deep learning for computer vision, the new skills needed for a specialized task can be transferred to large pre-trained transformers, e.g. downloaded from the HuggingFace repository.
The secret sauce in transformer architectures is the incorporation of some sort of attention mechanism, and the 2017 original is no exception. To avoid confusion, we’ll refer to the model demonstrated by Vaswani et al. as either just Transformer or as vanilla Transformer to distinguish it from successors with similar names like Transformer-XL. We’ll start by looking at the attention mechanism and build outward to a high-level view of the entire model.
Attention is a means of selectively weighting different elements in input data, so that they will have an adjusted impact on the hidden states of downstream layers. The vanilla Transformer implements attention by parsing input word vectors into key, query, and value vectors. The dot product of the key and query provide the attention weight, which is squashed using a softmax function across all attention weights so that the total weighting sums to 1. The value vectors corresponding to each element are summed according to their attention weights before being fed into subsequent layers. That may be a bit complicated to take in all at once, so let’s zoom in and go through it step-by-step.
Starting with a sequence of words forming a sentence, each element (word) in the sequence is first converted to an embedded representation called a word vector. Word vector embedding is a much more nuanced representation than something like a one-hot encoded bag-of-words model, like used by Salakhutidinov and Hinton in their 2007 Semantic Hashing paper.
Word embeddings (also sometimes called tokens) are useful because they impart semantic meaning in a numerical way that can be understood by neural networks. Learned word embeddings can contain contextual and relational information, for example as the semantic relationship between “dog” and “puppy” is roughly equivalent to “cat” and “kitten,” so we may be able to manipulate their word embeddings like so:
Vanilla Transformer attention mechanism detail.
Starting from the top left in the diagram above, an input word is first tokenized by an embedding function, replacing the string “ALL” with a numerical vector which will be the input to the attention layer. Note that the only layer which has an embedding function is the first encoder, every other layer just takes the preceding output vectors as inputs. The attention layer (W in the diagram) computes three vectors based on the input, termed key, query, and value. The dot product of key and query, a scalar, is the relative weighting for a given position.
The attention mechanism is applied in parallel at every element in the sequence, so every other element also has an attention score as well. These attention scores are subjected to a softmax function to ensure that the total weighting sums to 1.0, and then multiplied with the corresponding value vector. The values for all elements, now weighted by their attention scores, are summed together. The resulting vector is the new value in a sequence of vectors forming an internal representation of the input sequence, which will then be passed to a feed-forward fully connected layer.
Another important detail that may have gotten lost so far is the scaling factor used to stabilize the softmax function, i.e. before inputting values to the softmax function used by the attention layers, the numbers are scaled inversely proportional to the square root of the number of units in the key vector. This is important for making learning work well regardless of the size of the key and query vectors. Without a scaling factor the dot product will tend to be a large value when using long key and query vectors, pushing the gradient of the softmax function into a relatively flat area and making it difficult for error information to propagate.
As mentioned earlier, a useful consequence of doing away with recurrent connections is that the entire sequence can be processed at once in a feed-forward manner. When we combine the self-attention layer described above with a dense feed-forward layer, we get one encoder layer. The feed-forward layer is composed of two linear layers with a rectified linear unit (ReLU) in between them. That is to say the input is first transformed by a linear layer (matrix multiply), the resulting values are then clipped to always be 0 or greater, and finally the result is fed into a second linear layer to produce the feed-forward layer output.
Vanilla Transformer uses six of these encoder layers (self-attention layer + feed forward layer), followed by six decoder layers. Transformer uses a variant of self-attention called multi-headed attention, so in fact the attention layer will compute 8 different key, query, value vector sets for each sequence element. These will then be concatenated into one matrix, and put through another matrix multiply that yields the properly sized output vector.
Decoder layers share many of the features we saw in encoder layers, but with the addition of a second attention layer, the so-called encoder-decoder attention layer. Unlike the self-attention layer, only the query vectors come from the decoder layer itself. The key and value vectors are taken from the output of the encoder stack. Decoder layers also each contain a self-attention layer, just like we saw in the encoder, and the queries, keys, and values feeding into the self-attention layer are generated in the decoder stack.
Decoder layer, differing from encoder layers in the addition of a encoder-decoder attention sub-layer. Six of these make up the decoder in vanilla Transformer.
Now we have recipes for both encoder and decoder layers. To build a transformer out of these components, we have only to make two stacks, each with either six encoder layers or six decoder layers. The output of the encoder stack flows into the decoder stack, and each layer in the decoder stack also has access to the output from the encoders. But there are just a few details left to fully understand how the vanilla Transformer is put together.
Overview of the full Transformer.
Like many other extremely deep neural networks with many parameters, training them can sometimes be difficult when gradients don’t flow through from input to outputs as well as we’d like. In computer vision, this led to the powerful ResNet style of convolutional neural networks. ResNets, short for residual networks, explicitly add the input from the last layer to its own output. In this way the residuals are retained through the entire stack of layers and gradients can more easily flow from the loss function at the output all the way back to the inputs. DenseNet architectures aim to solve the same problem by concatenating input tensors and output tensors together, instead of adding. In the vanilla Transformer model, the residual summing operation is followed by layer normalization, a method for improving training that, unlike batch normalization, is not sensitive to minibatch size.
Diagram of residual connections and layer normalization. Every sub-layer in the encoder and decoder layers of vanilla Transformer incorporated this scheme.
In recurrent architectures like LSTMs the model can essentially learn to count and gauge sequence distances internally. Vanilla Transformer doesn’t use recurrent connections and perceives entire sequences simultaneously, so how does it learn which element came from which part of the sequence, especially when sequence length is allowed to vary? The answer is a positional encoding based on a decaying sinusoidal function that is concatenated to the sequence element embeddings. Vaswani et al. also experimented with learned positional encodings with almost identical results, but reasoned that using sinusoidal encodings should allow the model to generalize better to sequence lengths not seen during training.
The introduction of the vanilla Transformer in 2017 disrupted sequence-based deep learning significantly. By doing away with recurrent connections entirely, transformer architectures are better suited for massively parallel computation on modern machine learning acceleration hardware. It’s surprising that vanilla Transformer could learn long-term dependencies in a sequence at all, and in fact there is an upper limit to the distances over which vanilla Transformer can easily learn relationships.
Transformer-XL was introduced by Dai et al. In 2019 to address this problem with a new positional encoding, and also incorporated a sort of pseudo-recurrent connection where the key and value vectors depend in part on the previous hidden state as well as the current one. Additional transformer variants include decoder-only transformers (e.g. OpenAI’s GPT and GPT-2), adding bidirectionality (i.e. BERT-based transformers), among others. Transformers were designed for sequences and have found their most prominent applications in natural language processing, but transformer architectures have also been adapted for image generation, reinforcement learning (by modifying Transformer-XL), and for chemistry.
Hopefully this post has helped you to build intuition for working with modern transformer architectures for NLP and beyond. But you don’t have to be a hero and build and train a new transformer from scratch in order to try out your own ideas. Open source repositories like HuggingFace provide pre-trained models that you can fine-tune to fuel your NLP projects. Google has provided a notebook you can use to tinker with transformer models in their tensor2tensor library. And of course you can always talk to transformer or play a text-based dungeon adventure game with OpenAI’s GPT-2 as dungeon master. Depending on your preferred level of abstraction the above resources may be more than enough, but if you won’t be happy until you put code to concepts you may be interested in a code-annotated version of the paper from Alexander Rush and others at the Harvard NLP lab.
Happy transforming!



