Deep Learning
Compute Goes Brrr: Revisiting Sutton’s Bitter Lesson for Artificial Intelligence
October 27, 2020
22 min read


Not that long ago, in a world not far changed from the one we inhabit today, an ambitious project at Dartmouth College aimed to bridge the gap between human and machine intelligence. That was 1956, and while the Dartmouth Summer Research Project on Artificial Intelligence wasn’t the first project to consider the potential of thinking machines, it did give it a name and inaugurated a pantheon of influential researchers. In the proposal put together by John McCarthy, Marvin Minsky, Claude Shannon, and Nathaniel Rochester, the authors lay out ambitions that seem quaint today in their naïve ambition:
“An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves. We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.” –A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence, 1955
In the intervening period between then and now, there have been a series of waxing and waning periods of enthusiasm for AI research. Popular approaches in 1956 included cellular automata, cybernetics, and information theory, and throughout the years there would be debuts and revivals with expert systems, formal reasoning, connectionism and other methods all taking their turn in the limelight.
The current resurgence of AI is being driven by the latest incarnation of the connectionism lineage in the form of deep learning. Although a few new ideas have made major impacts in the field, (attention, residual connections, and batch normalization to name a few), most of the ideas about how to build and train deep neural networks had already been proposed in the 80s and 90s. And yet the role of AI or AI-adjacent technology today certainly isn’t what a researcher active in one of the previous “AI springs” would have envisaged. Few could have predicted the prevalence and societal repercussions of adtech and algorithmic newsfeeds, for example, and I’m sure many would be disappointed at the lack of androids in present day society.

John McCarthy, co-author of the Dartmouth proposal and coiner of the term Artificial Intelligence. Image CC BY SA flickr user null0.
A quote attributed to John McCarthy complains AI techniques that find real-world use invariably become less impressive, and lose the “AI” moniker in the process. That’s not what we see today, however, and perhaps we can blame venture capital and government funding bodies for incentivizing the opposite. A survey by London venture capital firm MMC found that up to 40% of self-described AI startups in Europe didn’t actually use AI as a core component of their business in 2019.
The difference between the deep learning era and previous highs in the AI research cycles seems to come down to our place on the sigmoidal curve of Moore’s Law. Many point to the “ImageNet Moment” as the beginning of the current AI/ML resurgence, when a model known as AlexNet won the 2012 ImageNet Large Scale Visual Recognition Competition (ILSVRC) by a substantial margin. The AlexNet architecture wasn’t much different from LeNet-5 developed more than two decades earlier.
AlexNet is slightly larger with 5 convolutional layers to LeNet’s 3, and 8 total layers vs 7 for LeNet (although those 7 layers include 2 pooling layers). The big breakthrough, then, came from implementing neural network primitives (convolutions and matrix multiplies) to take advantage of parallel execution on graphics processing units (GPUs), and the size and quality of the ImageNet dataset developed by Fei-Fei Li and her lab at Stanford.
Interested in an AI workstation?
Learn more about Exxact deep learning workstations starting at $3,700
Hardware acceleration is something that today’s deep learning practitioners take for granted. It’s part and parcel to popular deep learning libraries like PyTorch, TensorFlow, and JAX. The growing community of deep learners and commercial demand for AI/ML data products fuels a synergistic feedback loop, that fuels good hardware support. As new hardware accelerators based on FPGAs, ASICs, or even photonic or quantum chips, become available, software support in the major libraries is sure to follow close behind.
The impact of ML hardware accelerators and more available compute on AI research was succinctly described in a short and (in)famous essay by Richard Sutton called “The Bitter Lesson.” In the essay Sutton, who literally (co)-wrote the book on reinforcement learning, appears to claim that all the diligent efforts and clever hacks that AI researchers strive to make amount to very little in the grand scheme of things. The main driver of AI progress, according to Sutton, is the increasing availability of compute applied to simple learning and search algorithms we already have, with a minimum of hard-coded human knowledge. Specifically, Sutton argues for AI based only on methods that are as general as possible, such as unconstrained search and learning.
It’s no surprise that many researchers had contrary reactions to Sutton’s lesson. After all, many of these people have dedicated their lives to developing clever tricks and theoretical foundations to move the needle on AI progress. Many researchers in AI are not just interested in figuring out how to best state-of-the-art metrics, but to learn something about the nature of intelligence in general and, more abstractly, the role of humanity in the universe. Sutton’s statement seems to support the unsatisfying conclusion that searching for insights from theoretical neuroscience, mathematics, cognitive psychology, etc., are useless for driving AI progress.

Meme from gwern.net.
Noteworthy criticisms of Sutton’s essay include roboticist Rodney Brooks’ “A Better Lesson,” a tweet sequence from Oxford computer science professor Shimon Whiteson, and a blog post by Shopify data scientist Katherine Bailey. Bailey argues that, while Sutton may be right for the limited-scope tasks that serve as metrics for the modern AI field, that short-sightedness is missing the point entirely. The point of AI research is ultimately to understand intelligence in a useful way, not to train from scratch a new model for every narrow metric-based task, incurring substantial financial and energy costs along the way. Bailey thinks that modern machine learning practitioners too often mistake the metric for the goal; researchers did not set out to build superhuman chess engines or Go players for their own sake, but because these tasks seem to exemplify some aspect of human intelligence in a crucial way.
Brooks and Whiteson argue that in fact, all the examples used by Sutton as free from human priors are in fact the fruit of substantial human ingenuity. It’s hard to imagine deep neural networks that perform as well as modern ResNets without the translational invariance of convolutional layers, for example. We can also identify specific areas where current networks fall short, a lack of rotational invariance or color constancy are just 2 examples out of many. Architectures and training specifics also tend to make heavy use of human intuition and ingenuity. Even if neural architecture search (NAS) automation can sometimes find better architectures than models designed manually by human engineers, the component space available to NAS algorithms is vastly reduced from the space of all possible operations, and this narrowing down of what’s useful is invariably the purview of human designers.
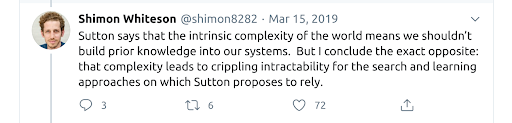
Whiteson argues that complexity necessitates, rather than obviates, human ingenuity in building machine learning systems.
There is substantial overlap between vocal critics of the bitter lesson and researchers that are skeptical of deep learning in general. Deep learning continues to impress with scale, despite ballooning compute budgets and growing environmental concerns about energy usage. And there’s no guarantee that deep learning won’t run up against a wall at some point in the future, possibly quite soon.
When will marginal gains no longer justify the additional expense? One reason that progress in deep learning is so surprising is that the models themselves can be nigh inscrutable; the performance of a model is an emergent product of a complex system with millions to billions of parameters. It’s difficult to predict or analyze what they may ultimately be capable of.
Perhaps we should all take to heart a lesson from the quintessential reference on good old-fashioned AI (GOFAI): “Artificial Intelligence: A Modern Approach” by Stuart Russell and Peter Norvig. Nestled towards the end of the last chapter we find this warning that our preferred approach to AI, in our case deep learning, may be like:
“… trying to get to the moon by climbing a tree; one can report steady progress, all the way to the top of the tree.“ -AIMA, Russel and Norvig
The authors are paraphrasing an analogy from a 1992 book by Hubert Drefyfus “What Computers Can’t Do,” which frequently returns to the analogy of the arboreal strategy for lunar travel. While many a primitive Homo sapiens may have attempted this method, actually reaching the moon requires one to come down from the trees and get started on building the foundations of a space program.
As appealing as these criticisms are, they can come across as little more than sour grapes. While academics are put off by the intellectually unfulfilling cry for “more compute,” researchers at large private research institutions continue to make headlines from projects where engineering efforts are primarily applied directly to scaling.
Perhaps most notorious for this approach is OpenAI.
Key personnel at OpenAI, which transitioned from a non-profit to a limited partnership corporate structure last year, have never been shy about their predilection for massive amounts of compute. Founders Greg Brockman and Ilya Sutskever fall firmly within Richard Sutton’s Bitter Lesson camp, as do many of the technical staff at the growing company. This has led to impressive feats of infrastructural engineering to empower the big training runs OpenAI turns to for reaching milestones.
OpenAI Five was able to beat the (human) Dota 2 world champions, Team OG, and it only took the agents 45,0000 simulated years, or about 250 years of gameplay per day to learn to play. That comes out to 800 petaflop/s-days over 10 months. Assuming a world-leading efficiency of 17 Gigaflop/s per watt, that comes to over 1.1 gigawatt hours: about 92 years of electricity use for an average US home.
Another high-profile and high-resource project from OpenAI was their Dactyl dexterity project with the Shadow robotic hand. That project culminated in achieving dexterous manipulation sufficient to solve a Rubik’s cube (although a deterministic solver was used to choose moves). The Rubik’s cube project was built on approximately 13,000 years of simulated experience. Comparable projects from DeepMind, such as AlphaStar (44 days of 384 TPUs training 12 agents, had thousands of years of simulated gameplay) or the AlphaGo lineage (AlphaGo Zero: ~1800 petaflop/s days) also required massive expenditures of computational resources.
A remarkable exception from the trends noted in The Bitter Lesson can be seen in the AlphaGo family of game playing agents, which actually required less compute as they reached better performance. The AlphaGo lineage is indeed a curious case that doesn’t fit kindly into the bitter lesson framework. Yes, the project started off with a heavy dose of overpowered HPC training, AlphaGo ran on 176 GPUs and consumed 40,000 watts at test time. But each successive iteration of AlphaGo up to MuZero used less energy and compute for both training and play.
In fact, when AlphaGo Zero played against StockFish, the pre-deep learning state-of-the-art chess engine, it used substantially less, and more specialized, search than StockFish. Whereas AlphaGo Zero did use Monte Carlo tree search, it was guided by a deep neural network value function. The alpha-beta pruning search employed by Stockfish is more general, and Stockfish evaluated about 400 times as many board positions as AlphaGo Zero during each turn.
You’ll recall that unrestrained search was a principal example of a general method used by Sutton, and if we take the Bitter Lesson at face value, it should outperform a more specialized method that performs narrowed search. Instead what we saw with the AlphaGo lineage was that each successive iteration (AlphaGo, AlphaGo Zero, AlphaZero, and MuZero) was more generally capable than the last, but employed more specialized learning and search. MuZero replaced the ground truth game simulator used for search by all its Alpha predecessors with a learned deep model for game state representation, game dynamics, and prediction.
Designing the learned game model represents substantially more human development than the original AlphaGo, while MuZero expanded in terms of general learning ability by reaching SOTA performance on the 57 game Atari benchmark, in addition to chess, shogi and Go learned by previous Alpha models. MuZero used 20% less computation per search node than AlphaZero, and, in part thanks to hardware improvements, 4 to 5 times fewer TPUs during training.

Stockfish, salted and hanging out to dry (after being defeated by AlphaGo Zero). Public Domain image.
The AlphaGo lineage of machine game players from Deepmind are a particularly elegant example of progress in deep reinforcement learning. If the AlphaGo team managed to continuously build capability and general learning competence while decreasing computational requirements, doesn’t that directly contradict the bitter lesson?
If so, what does it tell about the quest for general intelligence? RL is, according to many, a good candidate for building artificial general intelligence due to the similarity to how humans and animals learn in response to rewards. There are other modes of intelligence that some preferred as candidates for AGI precursors, however.
One reason Sutton’s article is getting a fresh round of attention (it was even recently reposted as a top article on KDNuggets) is the attention-grabbing release of OpenAI’s GPT-3 language model and API. GPT-3 is a 175 billion parameter transformer, eclipsing the previous record for language model size held by Microsoft’s Turing-NLG, by a little more than 10 times. GPT-3 is also more than 100 times larger than the “too dangerous to release” GPT-2.
The release of GPT-3 was a central part of the announcement of OpenAI’s API beta. Basically, the API gives experimenters access to the GPT-3 model (but not the ability to fine-tune parameters) and control over several hyperparameters that can be used to control inference. Understandingly, the beta testers lucky enough to get access to the API approached GPT-3 with much enthusiasm, and the results were impressive. Experimenters built text-based games, user interface generators, fake blogs, and many other creative uses of the massive model. GPT-3 is markedly better than GPT-2, and the only major difference is scale.
The trend toward larger language models predates the big GPTs, and isn’t limited to research at OpenAI. But the trend has really taken off since the introduction of the first transformer in “Attention is all You Need”. Transformers have been steadily creeping into the tens of billions of parameters, and it wouldn’t surprise me if there was a trillion parameter transformer demonstrated in about a year or so. Transformers seem to be particularly amenable to improving with scale, and the transformer architecture is not limited to natural language processing with text. Transformers have been adapted for reinforcement learning, predicting chemical reactions, generating music, and generating images. For a visual explainer of the attention mechanism used by transformer models, read this.
At the current rate of model growth someone will train a model with a comparable number of parameters as the total synapses in a human brain (~100 trillion) within a few years. Science fiction is riddled with examples of machines reaching consciousness and general intelligence simply by accruing sufficient scale and complexity. Is that the end result we can expect from growing transformers?

The performance of big transformers is certainly impressive, and continued progress due to scale seems to be in line with the Bitter Lesson. Triaging all other AI efforts behind scale remains inelegant and unsatisfying, however, and the concomitant demand for energy resources yields its own concerns. Training in the cloud separates many researchers at big labs from the physical reminders of training inefficiency. But anyone who runs deep learning experiments in a small office or apartment has a constant reminder in the stream of hot air constantly exiting the back of their workstation.

Portrait of Richard Sutton modified CC BY Steve Jurvetson
The carbon output of training a large NLP transformer with hyperparameter and architecture search can easily be larger than the combined carbon contributions of all other activities for individuals on a small research team.
We know that intelligence can run on hardware that runs continuously on about 20 watts (plus another ~80 watts for supporting machinery), and if you doubt that you should verify the existence proof between your ears. In contrast, the energy requirements used to train OpenAI Five were greater than the lifetime caloric needs of a human player, generously assuming a 90 year lifespan.
An attentive observer will point out that the 20 watt power consumption of a human brain doesn’t represent the entire learning algorithm. Rather, the architecture and operating rules are the results of a 4 billion year long black-box optimization process called evolution. Accounting for the sum of energy consumption for all ancestors might make the comparison between human and machine game players more favorable. Even so, the collective progress in model architectures and training algorithms is far from a purely general random search, and human-driven progress in machine intelligence certainly seems much faster compared to the evolution of intelligence in animals.
The obvious answer, potentially unsatisfying for absolutists, lies somewhere in between extremes. Attention mechanisms, convolutional layers, multiplicative recurrent connections, and many other mechanisms common in big models are all products of human ingenuity. In other words these are priors that humans thought might make learning work better, and they are essential for the scaling improvements we’ve seen so far. Discounting those inventions strictly in favor of Moore’s law and the Bitter Lesson is at least as short-sighted as relying on hand-coded expert knowledge.
An optimization process configured incorrectly can run to the heat death of the universe without ever solving a problem. Keeping that lesson in mind is essential to reaping the benefits of scale.

Have any questions about AI solutions?
Contact Exxact Today
Not that long ago, in a world not far changed from the one we inhabit today, an ambitious project at Dartmouth College aimed to bridge the gap between human and machine intelligence. That was 1956, and while the Dartmouth Summer Research Project on Artificial Intelligence wasn’t the first project to consider the potential of thinking machines, it did give it a name and inaugurated a pantheon of influential researchers. In the proposal put together by John McCarthy, Marvin Minsky, Claude Shannon, and Nathaniel Rochester, the authors lay out ambitions that seem quaint today in their naïve ambition:
“An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves. We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.” –A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence, 1955
In the intervening period between then and now, there have been a series of waxing and waning periods of enthusiasm for AI research. Popular approaches in 1956 included cellular automata, cybernetics, and information theory, and throughout the years there would be debuts and revivals with expert systems, formal reasoning, connectionism and other methods all taking their turn in the limelight.
The current resurgence of AI is being driven by the latest incarnation of the connectionism lineage in the form of deep learning. Although a few new ideas have made major impacts in the field, (attention, residual connections, and batch normalization to name a few), most of the ideas about how to build and train deep neural networks had already been proposed in the 80s and 90s. And yet the role of AI or AI-adjacent technology today certainly isn’t what a researcher active in one of the previous “AI springs” would have envisaged. Few could have predicted the prevalence and societal repercussions of adtech and algorithmic newsfeeds, for example, and I’m sure many would be disappointed at the lack of androids in present day society.
John McCarthy, co-author of the Dartmouth proposal and coiner of the term Artificial Intelligence. Image CC BY SA flickr user null0.
A quote attributed to John McCarthy complains AI techniques that find real-world use invariably become less impressive, and lose the “AI” moniker in the process. That’s not what we see today, however, and perhaps we can blame venture capital and government funding bodies for incentivizing the opposite. A survey by London venture capital firm MMC found that up to 40% of self-described AI startups in Europe didn’t actually use AI as a core component of their business in 2019.
The difference between the deep learning era and previous highs in the AI research cycles seems to come down to our place on the sigmoidal curve of Moore’s Law. Many point to the “ImageNet Moment” as the beginning of the current AI/ML resurgence, when a model known as AlexNet won the 2012 ImageNet Large Scale Visual Recognition Competition (ILSVRC) by a substantial margin. The AlexNet architecture wasn’t much different from LeNet-5 developed more than two decades earlier.
AlexNet is slightly larger with 5 convolutional layers to LeNet’s 3, and 8 total layers vs 7 for LeNet (although those 7 layers include 2 pooling layers). The big breakthrough, then, came from implementing neural network primitives (convolutions and matrix multiplies) to take advantage of parallel execution on graphics processing units (GPUs), and the size and quality of the ImageNet dataset developed by Fei-Fei Li and her lab at Stanford.
Interested in an AI workstation?
Learn more about Exxact deep learning workstations starting at $3,700
Hardware acceleration is something that today’s deep learning practitioners take for granted. It’s part and parcel to popular deep learning libraries like PyTorch, TensorFlow, and JAX. The growing community of deep learners and commercial demand for AI/ML data products fuels a synergistic feedback loop, that fuels good hardware support. As new hardware accelerators based on FPGAs, ASICs, or even photonic or quantum chips, become available, software support in the major libraries is sure to follow close behind.
The impact of ML hardware accelerators and more available compute on AI research was succinctly described in a short and (in)famous essay by Richard Sutton called “The Bitter Lesson.” In the essay Sutton, who literally (co)-wrote the book on reinforcement learning, appears to claim that all the diligent efforts and clever hacks that AI researchers strive to make amount to very little in the grand scheme of things. The main driver of AI progress, according to Sutton, is the increasing availability of compute applied to simple learning and search algorithms we already have, with a minimum of hard-coded human knowledge. Specifically, Sutton argues for AI based only on methods that are as general as possible, such as unconstrained search and learning.
It’s no surprise that many researchers had contrary reactions to Sutton’s lesson. After all, many of these people have dedicated their lives to developing clever tricks and theoretical foundations to move the needle on AI progress. Many researchers in AI are not just interested in figuring out how to best state-of-the-art metrics, but to learn something about the nature of intelligence in general and, more abstractly, the role of humanity in the universe. Sutton’s statement seems to support the unsatisfying conclusion that searching for insights from theoretical neuroscience, mathematics, cognitive psychology, etc., are useless for driving AI progress.
Meme from gwern.net.
Noteworthy criticisms of Sutton’s essay include roboticist Rodney Brooks’ “A Better Lesson,” a tweet sequence from Oxford computer science professor Shimon Whiteson, and a blog post by Shopify data scientist Katherine Bailey. Bailey argues that, while Sutton may be right for the limited-scope tasks that serve as metrics for the modern AI field, that short-sightedness is missing the point entirely. The point of AI research is ultimately to understand intelligence in a useful way, not to train from scratch a new model for every narrow metric-based task, incurring substantial financial and energy costs along the way. Bailey thinks that modern machine learning practitioners too often mistake the metric for the goal; researchers did not set out to build superhuman chess engines or Go players for their own sake, but because these tasks seem to exemplify some aspect of human intelligence in a crucial way.
Brooks and Whiteson argue that in fact, all the examples used by Sutton as free from human priors are in fact the fruit of substantial human ingenuity. It’s hard to imagine deep neural networks that perform as well as modern ResNets without the translational invariance of convolutional layers, for example. We can also identify specific areas where current networks fall short, a lack of rotational invariance or color constancy are just 2 examples out of many. Architectures and training specifics also tend to make heavy use of human intuition and ingenuity. Even if neural architecture search (NAS) automation can sometimes find better architectures than models designed manually by human engineers, the component space available to NAS algorithms is vastly reduced from the space of all possible operations, and this narrowing down of what’s useful is invariably the purview of human designers.
Whiteson argues that complexity necessitates, rather than obviates, human ingenuity in building machine learning systems.
There is substantial overlap between vocal critics of the bitter lesson and researchers that are skeptical of deep learning in general. Deep learning continues to impress with scale, despite ballooning compute budgets and growing environmental concerns about energy usage. And there’s no guarantee that deep learning won’t run up against a wall at some point in the future, possibly quite soon.
When will marginal gains no longer justify the additional expense? One reason that progress in deep learning is so surprising is that the models themselves can be nigh inscrutable; the performance of a model is an emergent product of a complex system with millions to billions of parameters. It’s difficult to predict or analyze what they may ultimately be capable of.
Perhaps we should all take to heart a lesson from the quintessential reference on good old-fashioned AI (GOFAI): “Artificial Intelligence: A Modern Approach” by Stuart Russell and Peter Norvig. Nestled towards the end of the last chapter we find this warning that our preferred approach to AI, in our case deep learning, may be like:
“… trying to get to the moon by climbing a tree; one can report steady progress, all the way to the top of the tree.“ -AIMA, Russel and Norvig
The authors are paraphrasing an analogy from a 1992 book by Hubert Drefyfus “What Computers Can’t Do,” which frequently returns to the analogy of the arboreal strategy for lunar travel. While many a primitive Homo sapiens may have attempted this method, actually reaching the moon requires one to come down from the trees and get started on building the foundations of a space program.
As appealing as these criticisms are, they can come across as little more than sour grapes. While academics are put off by the intellectually unfulfilling cry for “more compute,” researchers at large private research institutions continue to make headlines from projects where engineering efforts are primarily applied directly to scaling.
Perhaps most notorious for this approach is OpenAI.
Key personnel at OpenAI, which transitioned from a non-profit to a limited partnership corporate structure last year, have never been shy about their predilection for massive amounts of compute. Founders Greg Brockman and Ilya Sutskever fall firmly within Richard Sutton’s Bitter Lesson camp, as do many of the technical staff at the growing company. This has led to impressive feats of infrastructural engineering to empower the big training runs OpenAI turns to for reaching milestones.
OpenAI Five was able to beat the (human) Dota 2 world champions, Team OG, and it only took the agents 45,0000 simulated years, or about 250 years of gameplay per day to learn to play. That comes out to 800 petaflop/s-days over 10 months. Assuming a world-leading efficiency of 17 Gigaflop/s per watt, that comes to over 1.1 gigawatt hours: about 92 years of electricity use for an average US home.
Another high-profile and high-resource project from OpenAI was their Dactyl dexterity project with the Shadow robotic hand. That project culminated in achieving dexterous manipulation sufficient to solve a Rubik’s cube (although a deterministic solver was used to choose moves). The Rubik’s cube project was built on approximately 13,000 years of simulated experience. Comparable projects from DeepMind, such as AlphaStar (44 days of 384 TPUs training 12 agents, had thousands of years of simulated gameplay) or the AlphaGo lineage (AlphaGo Zero: ~1800 petaflop/s days) also required massive expenditures of computational resources.
A remarkable exception from the trends noted in The Bitter Lesson can be seen in the AlphaGo family of game playing agents, which actually required less compute as they reached better performance. The AlphaGo lineage is indeed a curious case that doesn’t fit kindly into the bitter lesson framework. Yes, the project started off with a heavy dose of overpowered HPC training, AlphaGo ran on 176 GPUs and consumed 40,000 watts at test time. But each successive iteration of AlphaGo up to MuZero used less energy and compute for both training and play.
In fact, when AlphaGo Zero played against StockFish, the pre-deep learning state-of-the-art chess engine, it used substantially less, and more specialized, search than StockFish. Whereas AlphaGo Zero did use Monte Carlo tree search, it was guided by a deep neural network value function. The alpha-beta pruning search employed by Stockfish is more general, and Stockfish evaluated about 400 times as many board positions as AlphaGo Zero during each turn.
You’ll recall that unrestrained search was a principal example of a general method used by Sutton, and if we take the Bitter Lesson at face value, it should outperform a more specialized method that performs narrowed search. Instead what we saw with the AlphaGo lineage was that each successive iteration (AlphaGo, AlphaGo Zero, AlphaZero, and MuZero) was more generally capable than the last, but employed more specialized learning and search. MuZero replaced the ground truth game simulator used for search by all its Alpha predecessors with a learned deep model for game state representation, game dynamics, and prediction.
Designing the learned game model represents substantially more human development than the original AlphaGo, while MuZero expanded in terms of general learning ability by reaching SOTA performance on the 57 game Atari benchmark, in addition to chess, shogi and Go learned by previous Alpha models. MuZero used 20% less computation per search node than AlphaZero, and, in part thanks to hardware improvements, 4 to 5 times fewer TPUs during training.
Stockfish, salted and hanging out to dry (after being defeated by AlphaGo Zero). Public Domain image.
The AlphaGo lineage of machine game players from Deepmind are a particularly elegant example of progress in deep reinforcement learning. If the AlphaGo team managed to continuously build capability and general learning competence while decreasing computational requirements, doesn’t that directly contradict the bitter lesson?
If so, what does it tell about the quest for general intelligence? RL is, according to many, a good candidate for building artificial general intelligence due to the similarity to how humans and animals learn in response to rewards. There are other modes of intelligence that some preferred as candidates for AGI precursors, however.
One reason Sutton’s article is getting a fresh round of attention (it was even recently reposted as a top article on KDNuggets) is the attention-grabbing release of OpenAI’s GPT-3 language model and API. GPT-3 is a 175 billion parameter transformer, eclipsing the previous record for language model size held by Microsoft’s Turing-NLG, by a little more than 10 times. GPT-3 is also more than 100 times larger than the “too dangerous to release” GPT-2.
The release of GPT-3 was a central part of the announcement of OpenAI’s API beta. Basically, the API gives experimenters access to the GPT-3 model (but not the ability to fine-tune parameters) and control over several hyperparameters that can be used to control inference. Understandingly, the beta testers lucky enough to get access to the API approached GPT-3 with much enthusiasm, and the results were impressive. Experimenters built text-based games, user interface generators, fake blogs, and many other creative uses of the massive model. GPT-3 is markedly better than GPT-2, and the only major difference is scale.
The trend toward larger language models predates the big GPTs, and isn’t limited to research at OpenAI. But the trend has really taken off since the introduction of the first transformer in “Attention is all You Need”. Transformers have been steadily creeping into the tens of billions of parameters, and it wouldn’t surprise me if there was a trillion parameter transformer demonstrated in about a year or so. Transformers seem to be particularly amenable to improving with scale, and the transformer architecture is not limited to natural language processing with text. Transformers have been adapted for reinforcement learning, predicting chemical reactions, generating music, and generating images. For a visual explainer of the attention mechanism used by transformer models, read this.
At the current rate of model growth someone will train a model with a comparable number of parameters as the total synapses in a human brain (~100 trillion) within a few years. Science fiction is riddled with examples of machines reaching consciousness and general intelligence simply by accruing sufficient scale and complexity. Is that the end result we can expect from growing transformers?
The performance of big transformers is certainly impressive, and continued progress due to scale seems to be in line with the Bitter Lesson. Triaging all other AI efforts behind scale remains inelegant and unsatisfying, however, and the concomitant demand for energy resources yields its own concerns. Training in the cloud separates many researchers at big labs from the physical reminders of training inefficiency. But anyone who runs deep learning experiments in a small office or apartment has a constant reminder in the stream of hot air constantly exiting the back of their workstation.
Portrait of Richard Sutton modified CC BY Steve Jurvetson
The carbon output of training a large NLP transformer with hyperparameter and architecture search can easily be larger than the combined carbon contributions of all other activities for individuals on a small research team.
We know that intelligence can run on hardware that runs continuously on about 20 watts (plus another ~80 watts for supporting machinery), and if you doubt that you should verify the existence proof between your ears. In contrast, the energy requirements used to train OpenAI Five were greater than the lifetime caloric needs of a human player, generously assuming a 90 year lifespan.
An attentive observer will point out that the 20 watt power consumption of a human brain doesn’t represent the entire learning algorithm. Rather, the architecture and operating rules are the results of a 4 billion year long black-box optimization process called evolution. Accounting for the sum of energy consumption for all ancestors might make the comparison between human and machine game players more favorable. Even so, the collective progress in model architectures and training algorithms is far from a purely general random search, and human-driven progress in machine intelligence certainly seems much faster compared to the evolution of intelligence in animals.
The obvious answer, potentially unsatisfying for absolutists, lies somewhere in between extremes. Attention mechanisms, convolutional layers, multiplicative recurrent connections, and many other mechanisms common in big models are all products of human ingenuity. In other words these are priors that humans thought might make learning work better, and they are essential for the scaling improvements we’ve seen so far. Discounting those inventions strictly in favor of Moore’s law and the Bitter Lesson is at least as short-sighted as relying on hand-coded expert knowledge.
An optimization process configured incorrectly can run to the heat death of the universe without ever solving a problem. Keeping that lesson in mind is essential to reaping the benefits of scale.
Have any questions about AI solutions?
Contact Exxact Today




{kind=link}