Deep Learning
CVPR 2020 Highlights: Here’s a Few Things You May Have Missed
June 23, 2020
6 min read


With all the madness going on with Covid-19, CVPR 2020 as well as most other conferences went totally virtual for 2020. However, if you think the research areas of computer vision, pattern recognition, and deep learning would have slowed during this time, you’ve been mistaken. Hopefully, you had a chance to attend CVPR Virtual this year, and even if you did, there were a lot of interesting things you may have missed. Today, we look at a few interesting topics/papers discussed.
This new paper by Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila from NVIDIA Research and aptly named StyleGAN2, presented at CVPR 2020 uses transfer learning to generate a seemingly infinite numbers of portraits in an infinite variety of painting styles. This research builds on NVIDIA’s previous StyleGAN project.
Demonstrated in the video, this model allows the user to create and fluidly explore the latent space in portraits. The UI allows modification of artistic style, color scheme, and brush strokes.
This model was trained in TensorFlow using a NVIDIA DGX system which boasts NVIDIA V100 GPUs. The code and pre-trained models are available on the StyleGAN2 GitHub repo.

Computer vision and ethics has become quite the controversial topic . From law enforcement, to employment screening,assigning trust scores, and more, computer vision systems are starting to become ingrained in all aspects of society. Recently a rise in public discourse regarding the use of CV In research, with examples of research that claims to classify “violent individuals” from drone footage.
This workshop also seeks to highlight research on uncovering and mitigating issues of unfair bias and historical discrimination that trained machine learning models learn to mimic and propagate.
Presenters: Timnit Gebru, Emily Denton from Google

The paper proposed a a learning-based approach for removing unwanted obstructions, such as window reflections, fence occlusions or raindrops, from a short sequence of images captured by a moving camera. The method leverages the motion differences between the background and the obstructing elements to recover both layers. The Researchers (Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, Jia-Bin Huang) showed that training on synthetically generated data transfers well to real images.

Image Source: https://arxiv.org/pdf/2004.011...
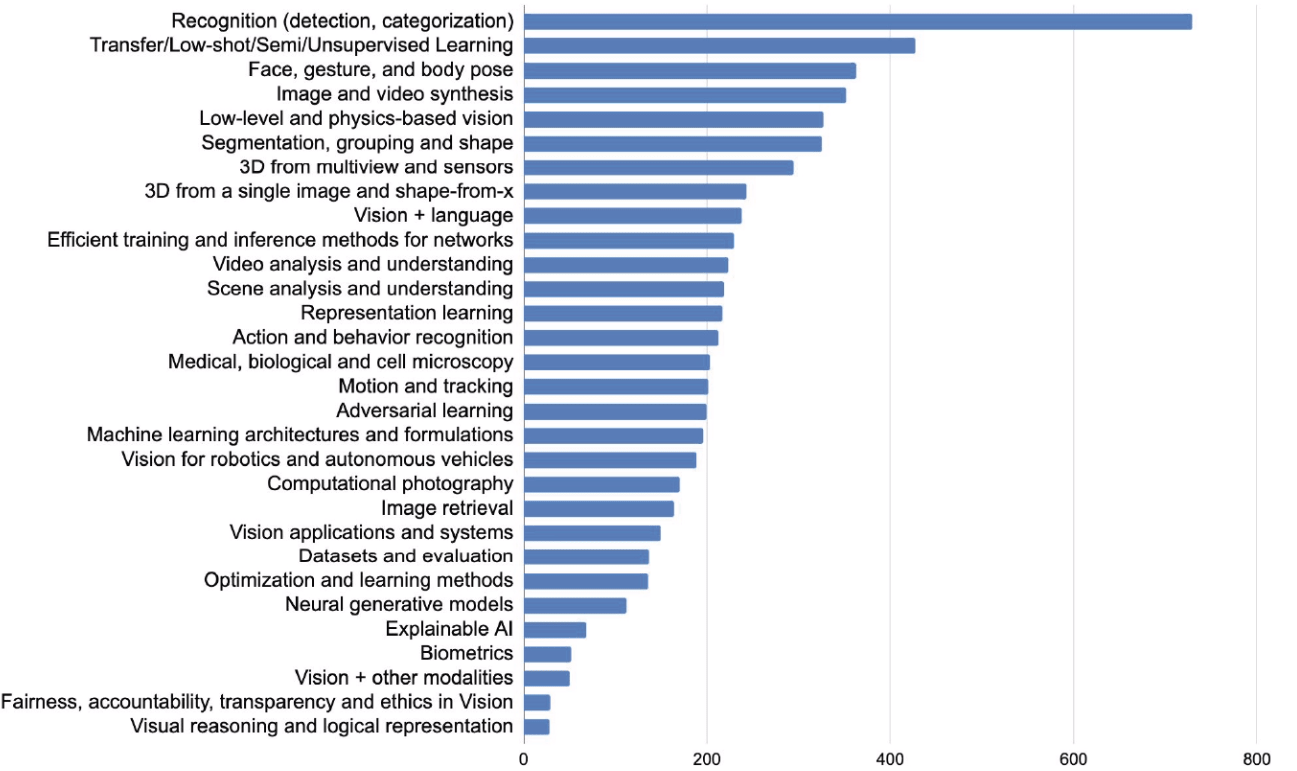
The numbers below were taken from the Opening & Awards presentation.





With all the madness going on with Covid-19, CVPR 2020 as well as most other conferences went totally virtual for 2020. However, if you think the research areas of computer vision, pattern recognition, and deep learning would have slowed during this time, you’ve been mistaken. Hopefully, you had a chance to attend CVPR Virtual this year, and even if you did, there were a lot of interesting things you may have missed. Today, we look at a few interesting topics/papers discussed.
This new paper by Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila from NVIDIA Research and aptly named StyleGAN2, presented at CVPR 2020 uses transfer learning to generate a seemingly infinite numbers of portraits in an infinite variety of painting styles. This research builds on NVIDIA’s previous StyleGAN project.
Demonstrated in the video, this model allows the user to create and fluidly explore the latent space in portraits. The UI allows modification of artistic style, color scheme, and brush strokes.
This model was trained in TensorFlow using a NVIDIA DGX system which boasts NVIDIA V100 GPUs. The code and pre-trained models are available on the StyleGAN2 GitHub repo.
Computer vision and ethics has become quite the controversial topic . From law enforcement, to employment screening,assigning trust scores, and more, computer vision systems are starting to become ingrained in all aspects of society. Recently a rise in public discourse regarding the use of CV In research, with examples of research that claims to classify “violent individuals” from drone footage.
This workshop also seeks to highlight research on uncovering and mitigating issues of unfair bias and historical discrimination that trained machine learning models learn to mimic and propagate.
Presenters: Timnit Gebru, Emily Denton from Google
The paper proposed a a learning-based approach for removing unwanted obstructions, such as window reflections, fence occlusions or raindrops, from a short sequence of images captured by a moving camera. The method leverages the motion differences between the background and the obstructing elements to recover both layers. The Researchers (Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, Jia-Bin Huang) showed that training on synthetically generated data transfers well to real images.
Image Source: https://arxiv.org/pdf/2004.011...
The numbers below were taken from the Opening & Awards presentation.
