Deep Learning
Evaluating the Most Popular Deep Learning Frameworks
October 5, 2017
7 min read


Choosing your deep learning software stack correctly from the beginning is crucial for the long-term success of your software projects, and deep learning is no exception. There are tons of frameworks out there, and choosing the correct one depends on the rest of your stack and how much level of control you want over what happens behind the scenes.
The most popular deep learning frameworks are currently: Caffe, Tensorflow, Theano, and Torch. Conveniently, all Exxact Deep Learning GPU Systems come pre-installed with these frameworks as part of our Deep Learning software suite.
Click here to learn more about Exxact's Deep Learning Server & Workstation GPU Solutions and our pre-installed software package.

The main ingredients of a deep learning framework are:
A tensor is a generalization of a matrix: think of a picture, for instance. The inner representation of a picture consists of horizontal and vertical coordinates for the pixels, and each pixel is represented by a vector of colors, corresponding to the RGB (red, green, and blue) decomposition. So we would expect that a deep learning framework would allow us to interact with different data sources (text, video, audio) and convert them into tensors, and conversely to convert back tensors into something human-readable.
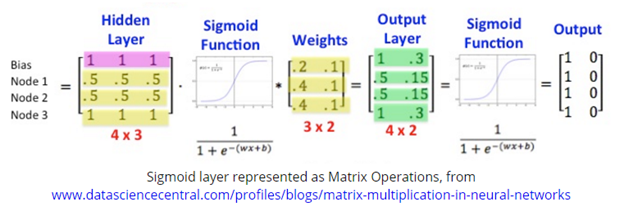
So having tensors is nice because we can run the usual neural networks workflow as recalled below: multiplying each input by the weight matrix and then passed through the activation function successively through many layers. All deep learning frameworks have this basic workflow implemented.
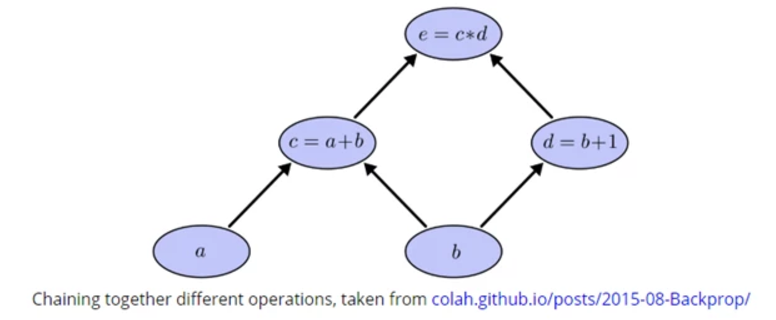
The most esoteric part of the inner workings of a framework is the computation graph. The computation graph takes care of the logic order on which operations should be performed and parallelizing whenever possible. A simple computation graph is shown below. Sure, it does look like overkill for the toy problem depicted there, but the issue is that the computation graph helps to allocate and coordinate resources. This is crucial for the data-intensive deep learning computations.
Differentiation tools are important because, as you know, backpropagation is basically the chain rule applied over and over, so we need to be able to reliably compute gradients numerically. It would be too much asking the user to implement those every time, so all deep learning frameworks have these tools.
Finally, for the implementation to be optimal, it needs to be close to machine language. Implementing complicated algorithms in low-level languages like C++ is error-prone, so having bindings from higher-level languages like Python or Lua to lower-level languages that can efficiently talk to the GPU is crucial.
Let’s go through some of the most popular frameworks:
![]()
The jury is still out there to say whether Theano or Caffe is the oldest framework. Although it does computer vision only, it works extremely well. It is based on C++, and it was the basis of the DeepDream project that Google released a few months back, to show how its network viewed images. It has been ported to Spark by Yahoo. Originally developed by the Berkeley Vision Lab.
Pros: Very flexible and performant. Top RNN support.
Cons: The installation is really painful, having lots of dependencies to solve.
Use cases: The undisputed leader for production in computer vision systems. Prototype with Keras, deploy with Caffe.
Learn more about the Caffe deep learning framework here.
![]()
Built on top of Theano, Tensorflow aims to provide a higher level of interaction. However, it is still too low level, and many well known deep learning experts use rather higher-level libraries, such as tf.contrib or Keras. However, as it is backed by Google, it has earned large user momentum in recent months. It is definitely a safe bet.
Pros: Large community, Google-supported. You can log events interactively with TensorBoard and see how the network is performing (learning rate, loss values, accuracy).
Cons: Still too low-level for many common tasks.
Use cases: For the intermediate user, when you need a compromise between flexibility and a large community to fall back into.
Learn more about the Tensorflow deep learning framework here.
![]()
Theano is the heart of higher-level frameworks (for instance, Tensorflow). The purpose of Theano is to be the symbolic mathematics library, and as such, you need to be quite familiar with the algorithms that are normally hidden away. It was developed by Frédéric Bastien, from the University of Montreal’s MILA lab.
Pros: Very flexible and performant. Top RNN support.
Cons: Low-level API. You need to be an expert in math powering the algorithms to get the most of it.
Use cases: Academic machine learning expert, bleeding-edge algorithms.
Learn more about the Theano deep learning framework here.
![]()
Torch, developed by the Facebook Artificial Intelligence Research Team (FAIR), has been around since 2002. There are many extensions available and a growing community. It is, however, developed in Lua, which is not precisely the most popular language.
Pros: Used by Facebook, IBM, Yandex, among others
Cons: Limited references outside the official documentation
Use cases: If you absolutely love/must program in Lua, this framework is for you.
While the jury is still out there for the best deep learning framework, our choice is to go from top-down and try a higher-level framework first (Keras, Tensorflow) and then dive deeper into lower-level frameworks for production (Theano, Caffe).
Learn more about the Torch deep learning framework here.

Choosing your deep learning software stack correctly from the beginning is crucial for the long-term success of your software projects, and deep learning is no exception. There are tons of frameworks out there, and choosing the correct one depends on the rest of your stack and how much level of control you want over what happens behind the scenes.
The most popular deep learning frameworks are currently: Caffe, Tensorflow, Theano, and Torch. Conveniently, all Exxact Deep Learning GPU Systems come pre-installed with these frameworks as part of our Deep Learning software suite.
Click here to learn more about Exxact's Deep Learning Server & Workstation GPU Solutions and our pre-installed software package.
The main ingredients of a deep learning framework are:
A tensor is a generalization of a matrix: think of a picture, for instance. The inner representation of a picture consists of horizontal and vertical coordinates for the pixels, and each pixel is represented by a vector of colors, corresponding to the RGB (red, green, and blue) decomposition. So we would expect that a deep learning framework would allow us to interact with different data sources (text, video, audio) and convert them into tensors, and conversely to convert back tensors into something human-readable.
So having tensors is nice because we can run the usual neural networks workflow as recalled below: multiplying each input by the weight matrix and then passed through the activation function successively through many layers. All deep learning frameworks have this basic workflow implemented.
The most esoteric part of the inner workings of a framework is the computation graph. The computation graph takes care of the logic order on which operations should be performed and parallelizing whenever possible. A simple computation graph is shown below. Sure, it does look like overkill for the toy problem depicted there, but the issue is that the computation graph helps to allocate and coordinate resources. This is crucial for the data-intensive deep learning computations.
Differentiation tools are important because, as you know, backpropagation is basically the chain rule applied over and over, so we need to be able to reliably compute gradients numerically. It would be too much asking the user to implement those every time, so all deep learning frameworks have these tools.
Finally, for the implementation to be optimal, it needs to be close to machine language. Implementing complicated algorithms in low-level languages like C++ is error-prone, so having bindings from higher-level languages like Python or Lua to lower-level languages that can efficiently talk to the GPU is crucial.
Let’s go through some of the most popular frameworks:
![]()
The jury is still out there to say whether Theano or Caffe is the oldest framework. Although it does computer vision only, it works extremely well. It is based on C++, and it was the basis of the DeepDream project that Google released a few months back, to show how its network viewed images. It has been ported to Spark by Yahoo. Originally developed by the Berkeley Vision Lab.
Pros: Very flexible and performant. Top RNN support.
Cons: The installation is really painful, having lots of dependencies to solve.
Use cases: The undisputed leader for production in computer vision systems. Prototype with Keras, deploy with Caffe.
Learn more about the Caffe deep learning framework here.
![]()
Built on top of Theano, Tensorflow aims to provide a higher level of interaction. However, it is still too low level, and many well known deep learning experts use rather higher-level libraries, such as tf.contrib or Keras. However, as it is backed by Google, it has earned large user momentum in recent months. It is definitely a safe bet.
Pros: Large community, Google-supported. You can log events interactively with TensorBoard and see how the network is performing (learning rate, loss values, accuracy).
Cons: Still too low-level for many common tasks.
Use cases: For the intermediate user, when you need a compromise between flexibility and a large community to fall back into.
Learn more about the Tensorflow deep learning framework here.
![]()
Theano is the heart of higher-level frameworks (for instance, Tensorflow). The purpose of Theano is to be the symbolic mathematics library, and as such, you need to be quite familiar with the algorithms that are normally hidden away. It was developed by Frédéric Bastien, from the University of Montreal’s MILA lab.
Pros: Very flexible and performant. Top RNN support.
Cons: Low-level API. You need to be an expert in math powering the algorithms to get the most of it.
Use cases: Academic machine learning expert, bleeding-edge algorithms.
Learn more about the Theano deep learning framework here.
![]()
Torch, developed by the Facebook Artificial Intelligence Research Team (FAIR), has been around since 2002. There are many extensions available and a growing community. It is, however, developed in Lua, which is not precisely the most popular language.
Pros: Used by Facebook, IBM, Yandex, among others
Cons: Limited references outside the official documentation
Use cases: If you absolutely love/must program in Lua, this framework is for you.
While the jury is still out there for the best deep learning framework, our choice is to go from top-down and try a higher-level framework first (Keras, Tensorflow) and then dive deeper into lower-level frameworks for production (Theano, Caffe).
Learn more about the Torch deep learning framework here.
