Deep Learning
New Deep Learning Software Release: NVIDIA TensorRT 5
November 20, 2018
3 min read


NVIDIA TensorRT™ is a platform for high-performance deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high-throughput for deep learning inference applications. TensorRT-based applications perform up to 40x faster than CPU-only platforms during inference. With TensorRT, you can optimize neural network models trained in all major frameworks, calibrate for lower precision with high accuracy, and finally deploy to hyperscale data centers, embedded, or automotive product platforms.
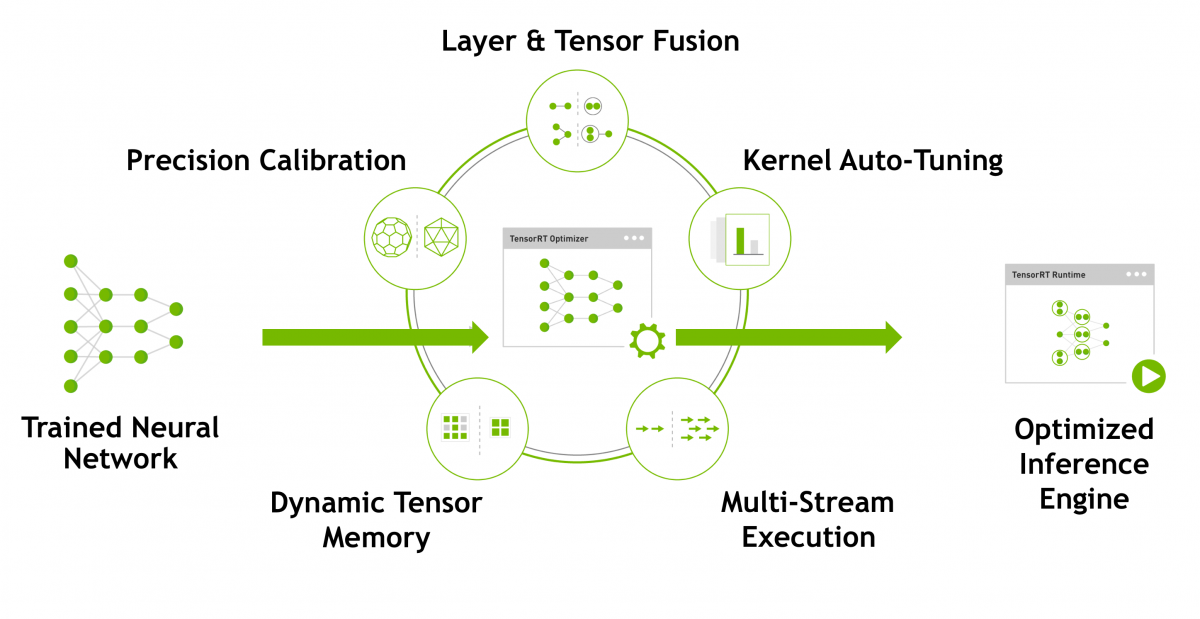
TensorRT provides INT8 and FP16 optimizations for production deployments of deep learning inference applications such as video streaming, speech recognition, recommendation and natural language processing. Reduced precision inference significantly reduces application latency, which is a requirement for many real-time services, auto and embedded applications.

TensorRT 5, the latest version of NVIDIA's optimizer and runtime, delivers up to 40x faster inference over CPU-only platforms through support for Turing GPUs, new INT8 APIs and optimizations. It uses multi-precision compute to dramatically speed up recommenders, neural machine translation, speech and natural language processing.
With TensorRT 5, you can:
The NVIDIA TensorRT inference server makes state-of-the-art AI-driven experiences possible in real-time. It’s a containerized inference microservice for data center production that maximizes GPU utilization and seamlessly integrates into DevOps deployments with Docker and Kubernetes integration.
The TensorRT inference server:
With the NVIDIA TensorRT inference server, there’s now a common solution for AI inference, allowing researchers to focus on creating high-quality trained models, DevOps engineers to focus on deployment, and developers to focus on their applications, without needing to reinvent the plumbing for each AI-powered application.

Have any questions? Contact us directly here.
NVIDIA TensorRT™ is a platform for high-performance deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high-throughput for deep learning inference applications. TensorRT-based applications perform up to 40x faster than CPU-only platforms during inference. With TensorRT, you can optimize neural network models trained in all major frameworks, calibrate for lower precision with high accuracy, and finally deploy to hyperscale data centers, embedded, or automotive product platforms.
TensorRT provides INT8 and FP16 optimizations for production deployments of deep learning inference applications such as video streaming, speech recognition, recommendation and natural language processing. Reduced precision inference significantly reduces application latency, which is a requirement for many real-time services, auto and embedded applications.
TensorRT 5, the latest version of NVIDIA's optimizer and runtime, delivers up to 40x faster inference over CPU-only platforms through support for Turing GPUs, new INT8 APIs and optimizations. It uses multi-precision compute to dramatically speed up recommenders, neural machine translation, speech and natural language processing.
With TensorRT 5, you can:
The NVIDIA TensorRT inference server makes state-of-the-art AI-driven experiences possible in real-time. It’s a containerized inference microservice for data center production that maximizes GPU utilization and seamlessly integrates into DevOps deployments with Docker and Kubernetes integration.
The TensorRT inference server:
With the NVIDIA TensorRT inference server, there’s now a common solution for AI inference, allowing researchers to focus on creating high-quality trained models, DevOps engineers to focus on deployment, and developers to focus on their applications, without needing to reinvent the plumbing for each AI-powered application.
Have any questions? Contact us directly here.
