Deep Learning
RNN vs CNN for Deep Learning: Let's Learn the Difference
April 17, 2019
13 min read


Many people are familiar with the term deep learning, as it has gained widespread attention as a reliable way to tackle difficult and computationally expensive problems. However, especially among newcomers to the field, there is little concern for how these systems were originally developed. Without this context, it is sometimes difficult to decide which specific framework, or architecture is required for a particular application.
In this post will learn the difference between a deep learning RNN vs CNN.
Modern day deep learning systems are based on the Artificial Neural Network (ANN), which is a system of computing that is loosely modeled on the structure of the brain.
Neural networks are not stand alone computing algorithms. Rather, they represent a structure, or framework, that is used to combine machine learning algorithms for the purpose of solving specific tasks.
Neural Networks (NN) are comprised of layers, where each layer contains many artificial neurons. A connection between neurons is analogous to a synapse within the brain, where a signal can be transmitted from one neuron to another. Connections between layers are defined by the links between neurons from one layer to the next.
A traditional NN is comprised of several layers, each performing a specific function that contributes to solving the problem at hand. The first of these is the input layer, which assumes the role of a sense. In an image recognition task this can be thought of as the eyes, whereas it would accept audio data in a speech recognition system. The input layer is followed by one or more hidden layers, and ultimately the chain is completed with an output layer. The output layer can be thought of as the final decision maker, whereas the hidden layers are where the real learning takes place.
The data “moves”, by way of transformation, from the input, sequentially through each of the hidden layers, and terminates in the output layer. This is more generally known as a feedforward neural network.
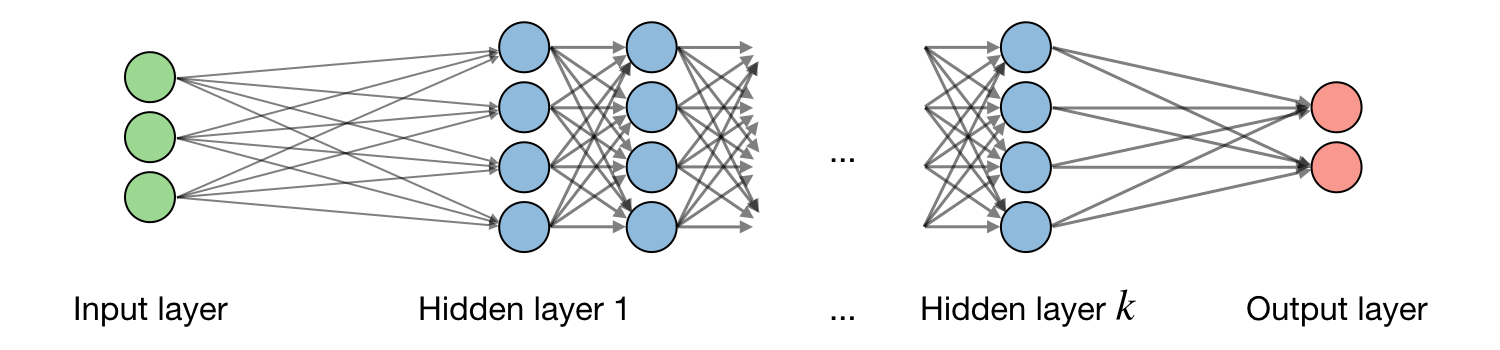
Image Source: "Deep Learning cheatsheet" Afshine Amidi, Shervine Amidi
While the traditional NN proved successful in many tasks, recognition of its true strength began with the introduction of very large amounts of data and the computing power required to process it. Essentially, deep learning systems are very large neural networks that are trained using considerable volumes of data. With the realization that these systems had vast and untapped potential, the composition of the underlying structure became an important research topic.
An important milestone in the history of deep learning was the introduction of the Recurrent Neural Network (RNN), which constituted a significant change in the makeup of the framework.
Interested in a deep learning solution?
Learn more about Exxact workstations starting at $3700
The RNN uses an architecture that is not dissimilar to the traditional NN. The difference is that the RNN introduces the concept of memory, and it exists in the form of a different type of link. Unlike a feedforward NN, the outputs of some layers are fed back into the inputs of a previous layer. This addition allows for the analysis of sequential data, which is something that the traditional NN is incapable of. Also, traditional NNs are limited to a fixed-length input, whereas the RNN has no such restriction.
The inclusion of links between layers in the reverse direction allows for feedback loops, which are used to help learn concepts based on context. In terms of what this can do for a deep learning application, it depends very much on the requirements (or goal) and the data.
For time series data that contains repeated patterns, the RNN is able to recognize and take advantage of the time-related context. This is accomplished by applying more weight to patterns where the previous and following tokens are recognized, as opposed to being evaluated in isolation. For example, consider a system that is learning to recognize spoken language. Such a system would benefit greatly by taking into account recently spoken words to predict the next sentence.
On this topic, a popular framework for learning sequence data is called the Long Short-Term Memory Network (LSTM). This is a type of RNN that is capable of learning long-term relationships. If, for example, the prediction of the next word in an autocomplete task is dependent on context from much earlier in the sentence, or paragraph, then the LSTM is designed to assist with this. LSTMs have also achieved success in acoustic modeling and part-of-speech tasks.
RNNs come in different varieties that are also typically dependent on the task. The type of RNN is described by the number of inputs in relation to the number of outputs. The four different types are:
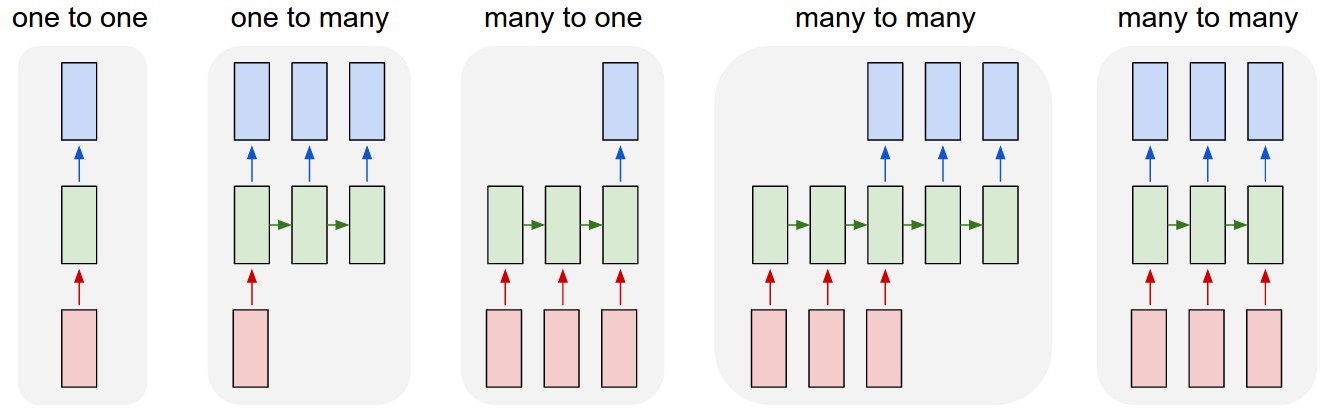
To understand which of these is best suited for a particular job, it is worthwhile to review some of the applications for RNNs and CNNs.
RNNs are applied successfully in many types of tasks. Some of these include:
When comparing RNN vs CNN, the next important innovation in neural network frameworks is the CNN. The defining feature of the CNN is that it performs the convolution operation in certain layers – hence, the name Convolutional Neural Network. The architecture varies slightly from the traditional NN, starting with the makeup of the individual layers.
In CNNs, the first layer is always a Convolutional layer. These are defined using the three spatial dimensions: length, width, and depth. These layers are not fully connected – meaning that the neurons from one layer do not connect to each and every neuron in the following layer. The output of the final convolution layer is the input to the first fully connected layer.
Interactive Demo of CNN recognizing hand written digits:
Try it for yourself at http://scs.ryerson.ca/~aharley/vis/conv/flat.html
Mathematically speaking, a convolution is a grouping function that takes place between two matrices. More generally it combines two functions to make a third, thereby merging information. In practice they can be thought of as a filter, or a mechanism for feature selection. A single layer may be responsible for pinpointing very bright pixels in an image, and a subsequent layer recognizes that these highlights, taken together, represent the edge of an object in the image.
In addition to the convolution layers, it is common to add pooling layers in between them. A pooling layer is responsible for simplifying the data by reducing its dimensionality. This effectively shortens the time required for training, and helps to curb the problem of overfitting. After the convolution and pooling layers come the fully connected layers.
In the final, fully connected layers, every neuron in the first is connected to every neuron in the next. The process during this stage looks at what features most accurately describe the specific classes, and the result is a single vector of probabilities that are organized according to depth. For example, in a vehicle recognition system, there are numerous features to consider.
A side-view picture of a car may only show two wheels. Taken in isolation, this incomplete description will potentially match a motorcycle. As such, there will be a non-zero probability, albeit small, that a car will be classified as a motorcycle or vice-versa. Importantly, additional features such as the presence of windows and/or doors will help to more accurately determine the vehicle type. The output layer generates the probabilities that correspond to each class. That with the highest probability is assumed to be the best choice. In this example of identifying a car, the motorcycle would have a lower probability because, among other things, there are no visible doors.
The most common application for CNNs is in the general field of computer vision. Examples of this are medical image analysis, image recognition, face detection and recognition systems, and full motion video analysis.
One such system is AlexNet, which is a CNN that gained attention when it won the 2012 ImageNet Large Scale Visual Recognition Challenge. It is a CNN that consists of eight layers, where the first five are convolutional, and the final three are fully connected layers.
CNN has been the subject of research and testing for other tasks, and it has been effective in solving traditional Natural Language Processing (NLP) tasks. Specifically, it has achieved very impressive results in semantic parsing, sentence modeling, and search query retrieval.
CNNs have been employed in the field of drug discovery. AtomNet is a deep learning NN that trains on 3D representations of chemical interactions. It discovers chemical features, and has been used to predict novel biomolecules for combating disease.
Finally, it is worth noting that CNNs have been applied to more traditional machine learning problems, such as game playing. Both Checkers and Go are games for which CNN has learned to play at the professional level.
A comparison of RNN vs CNN would not be complete without mention that these two approaches are not mutually exclusive of each other. At first glance it may seem that they are used to handle different problems, but it is important to note that some types of data can be processed by either architecture. Examples of this are image classification and text classification, where both systems have been effective. Moreover, some deep learning applications may benefit from the combination of the two architectures.
Suppose that the data being modeled, whether representative of an image or otherwise, has temporal properties. This is an ideal situation for the merging of these techniques. One such hybrid approach is known as the DanQ architecture. It takes a fixed length DNA sequence as input and predicts properties of the DNA. The convolutional layer discovers sequence motifs, which are short recurring patterns that are presumed to have a biological function. The recurrent layer is responsible for capturing long-term relationships, or dependencies between motifs. This allows the system to learn the DNA’s grammar and consequently, improve predictions.
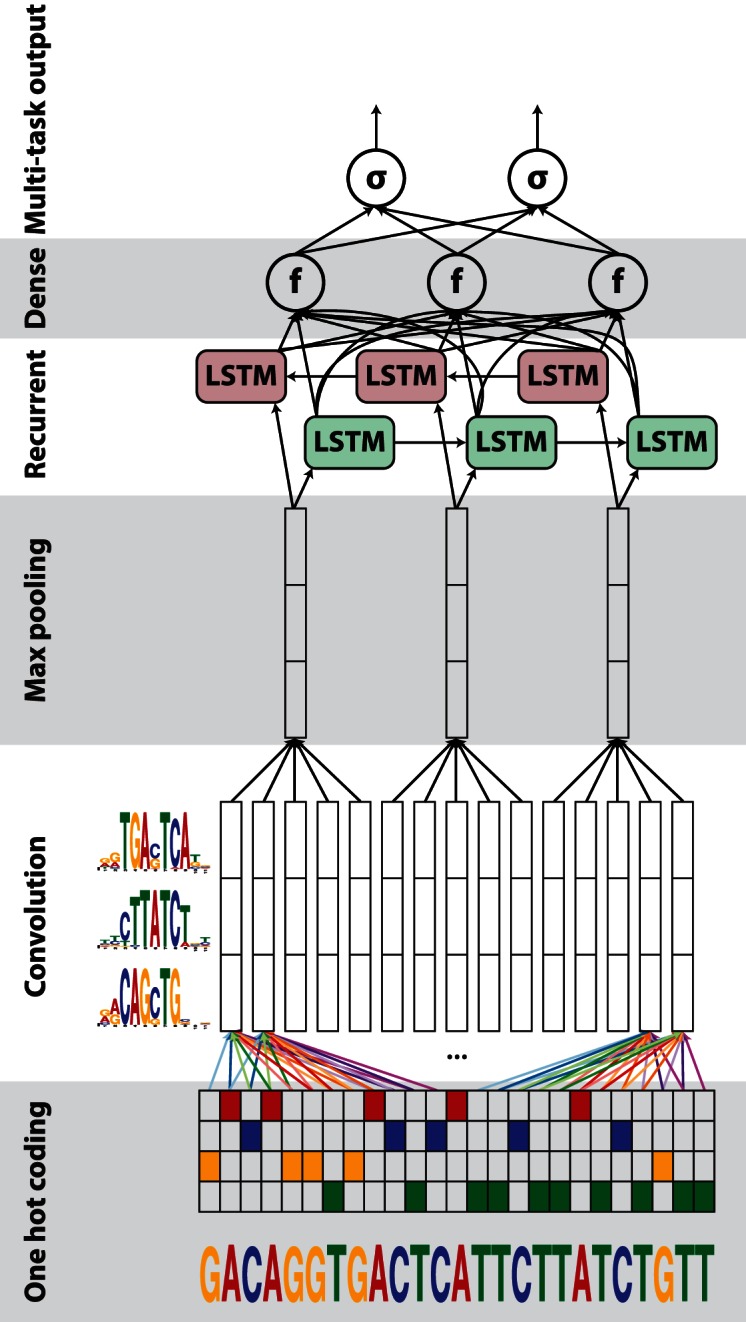
Image source: DanQ: a hybrid convolutional and recurrent deep neural network for quantifying the function of DNA sequences - D. Quang, X. Xie
DanQ was built upon the DeepSEA model, which performs the same function as DanQ, but does not include the RNN component. The DanQ model performs superiorly to its predecessor, thereby highlighting the significance of adding memory and feedback loops to the architecture. Similarly, the RNN component benefits by considering only the more abstract data that has been filtered by the CNN, making the long-term relationships easier to discover.
It goes without question when comparing RNN vs CNN, both are commonplace in the field of Deep Learning. Each architecture has advantages and disadvantages that are dependent upon the type of data that is being modeled. When choosing one framework over the other, or alternatively creating a hybrid approach, the type of data and the job at hand are the most important points to consider.
An RNN is used for cases where the data contains temporal properties, such as a time series. Similarly, where the data is context sensitive, as in the case of sentence completion, the function of memory provided by the feedback loops is critical for adequate performance.
A CNN is the top choice for image classification and more generally, computer vision. In addition, CNNs have been used for myriad tasks, and outperform other machine learning algorithms in some domains. CNNs are not, however, capable of handling a variable-length input.
Finally, a hybrid RNN and CNN approach may be superior when the data is suitable for a CNN, but has temporal characteristics that can be identified and exploited by an RNN component.
Have any questions?
Contact Exxact Today
Many people are familiar with the term deep learning, as it has gained widespread attention as a reliable way to tackle difficult and computationally expensive problems. However, especially among newcomers to the field, there is little concern for how these systems were originally developed. Without this context, it is sometimes difficult to decide which specific framework, or architecture is required for a particular application.
In this post will learn the difference between a deep learning RNN vs CNN.
Modern day deep learning systems are based on the Artificial Neural Network (ANN), which is a system of computing that is loosely modeled on the structure of the brain.
Neural networks are not stand alone computing algorithms. Rather, they represent a structure, or framework, that is used to combine machine learning algorithms for the purpose of solving specific tasks.
Neural Networks (NN) are comprised of layers, where each layer contains many artificial neurons. A connection between neurons is analogous to a synapse within the brain, where a signal can be transmitted from one neuron to another. Connections between layers are defined by the links between neurons from one layer to the next.
A traditional NN is comprised of several layers, each performing a specific function that contributes to solving the problem at hand. The first of these is the input layer, which assumes the role of a sense. In an image recognition task this can be thought of as the eyes, whereas it would accept audio data in a speech recognition system. The input layer is followed by one or more hidden layers, and ultimately the chain is completed with an output layer. The output layer can be thought of as the final decision maker, whereas the hidden layers are where the real learning takes place.
The data “moves”, by way of transformation, from the input, sequentially through each of the hidden layers, and terminates in the output layer. This is more generally known as a feedforward neural network.
Image Source: "Deep Learning cheatsheet" Afshine Amidi, Shervine Amidi
While the traditional NN proved successful in many tasks, recognition of its true strength began with the introduction of very large amounts of data and the computing power required to process it. Essentially, deep learning systems are very large neural networks that are trained using considerable volumes of data. With the realization that these systems had vast and untapped potential, the composition of the underlying structure became an important research topic.
An important milestone in the history of deep learning was the introduction of the Recurrent Neural Network (RNN), which constituted a significant change in the makeup of the framework.
Interested in a deep learning solution?
Learn more about Exxact workstations starting at $3700
The RNN uses an architecture that is not dissimilar to the traditional NN. The difference is that the RNN introduces the concept of memory, and it exists in the form of a different type of link. Unlike a feedforward NN, the outputs of some layers are fed back into the inputs of a previous layer. This addition allows for the analysis of sequential data, which is something that the traditional NN is incapable of. Also, traditional NNs are limited to a fixed-length input, whereas the RNN has no such restriction.
The inclusion of links between layers in the reverse direction allows for feedback loops, which are used to help learn concepts based on context. In terms of what this can do for a deep learning application, it depends very much on the requirements (or goal) and the data.
For time series data that contains repeated patterns, the RNN is able to recognize and take advantage of the time-related context. This is accomplished by applying more weight to patterns where the previous and following tokens are recognized, as opposed to being evaluated in isolation. For example, consider a system that is learning to recognize spoken language. Such a system would benefit greatly by taking into account recently spoken words to predict the next sentence.
On this topic, a popular framework for learning sequence data is called the Long Short-Term Memory Network (LSTM). This is a type of RNN that is capable of learning long-term relationships. If, for example, the prediction of the next word in an autocomplete task is dependent on context from much earlier in the sentence, or paragraph, then the LSTM is designed to assist with this. LSTMs have also achieved success in acoustic modeling and part-of-speech tasks.
RNNs come in different varieties that are also typically dependent on the task. The type of RNN is described by the number of inputs in relation to the number of outputs. The four different types are:
To understand which of these is best suited for a particular job, it is worthwhile to review some of the applications for RNNs and CNNs.
RNNs are applied successfully in many types of tasks. Some of these include:
When comparing RNN vs CNN, the next important innovation in neural network frameworks is the CNN. The defining feature of the CNN is that it performs the convolution operation in certain layers – hence, the name Convolutional Neural Network. The architecture varies slightly from the traditional NN, starting with the makeup of the individual layers.
In CNNs, the first layer is always a Convolutional layer. These are defined using the three spatial dimensions: length, width, and depth. These layers are not fully connected – meaning that the neurons from one layer do not connect to each and every neuron in the following layer. The output of the final convolution layer is the input to the first fully connected layer.
Interactive Demo of CNN recognizing hand written digits:
Try it for yourself at http://scs.ryerson.ca/~aharley/vis/conv/flat.html
Mathematically speaking, a convolution is a grouping function that takes place between two matrices. More generally it combines two functions to make a third, thereby merging information. In practice they can be thought of as a filter, or a mechanism for feature selection. A single layer may be responsible for pinpointing very bright pixels in an image, and a subsequent layer recognizes that these highlights, taken together, represent the edge of an object in the image.
In addition to the convolution layers, it is common to add pooling layers in between them. A pooling layer is responsible for simplifying the data by reducing its dimensionality. This effectively shortens the time required for training, and helps to curb the problem of overfitting. After the convolution and pooling layers come the fully connected layers.
In the final, fully connected layers, every neuron in the first is connected to every neuron in the next. The process during this stage looks at what features most accurately describe the specific classes, and the result is a single vector of probabilities that are organized according to depth. For example, in a vehicle recognition system, there are numerous features to consider.
A side-view picture of a car may only show two wheels. Taken in isolation, this incomplete description will potentially match a motorcycle. As such, there will be a non-zero probability, albeit small, that a car will be classified as a motorcycle or vice-versa. Importantly, additional features such as the presence of windows and/or doors will help to more accurately determine the vehicle type. The output layer generates the probabilities that correspond to each class. That with the highest probability is assumed to be the best choice. In this example of identifying a car, the motorcycle would have a lower probability because, among other things, there are no visible doors.
The most common application for CNNs is in the general field of computer vision. Examples of this are medical image analysis, image recognition, face detection and recognition systems, and full motion video analysis.
One such system is AlexNet, which is a CNN that gained attention when it won the 2012 ImageNet Large Scale Visual Recognition Challenge. It is a CNN that consists of eight layers, where the first five are convolutional, and the final three are fully connected layers.
CNN has been the subject of research and testing for other tasks, and it has been effective in solving traditional Natural Language Processing (NLP) tasks. Specifically, it has achieved very impressive results in semantic parsing, sentence modeling, and search query retrieval.
CNNs have been employed in the field of drug discovery. AtomNet is a deep learning NN that trains on 3D representations of chemical interactions. It discovers chemical features, and has been used to predict novel biomolecules for combating disease.
Finally, it is worth noting that CNNs have been applied to more traditional machine learning problems, such as game playing. Both Checkers and Go are games for which CNN has learned to play at the professional level.
A comparison of RNN vs CNN would not be complete without mention that these two approaches are not mutually exclusive of each other. At first glance it may seem that they are used to handle different problems, but it is important to note that some types of data can be processed by either architecture. Examples of this are image classification and text classification, where both systems have been effective. Moreover, some deep learning applications may benefit from the combination of the two architectures.
Suppose that the data being modeled, whether representative of an image or otherwise, has temporal properties. This is an ideal situation for the merging of these techniques. One such hybrid approach is known as the DanQ architecture. It takes a fixed length DNA sequence as input and predicts properties of the DNA. The convolutional layer discovers sequence motifs, which are short recurring patterns that are presumed to have a biological function. The recurrent layer is responsible for capturing long-term relationships, or dependencies between motifs. This allows the system to learn the DNA’s grammar and consequently, improve predictions.
Image source: DanQ: a hybrid convolutional and recurrent deep neural network for quantifying the function of DNA sequences - D. Quang, X. Xie
DanQ was built upon the DeepSEA model, which performs the same function as DanQ, but does not include the RNN component. The DanQ model performs superiorly to its predecessor, thereby highlighting the significance of adding memory and feedback loops to the architecture. Similarly, the RNN component benefits by considering only the more abstract data that has been filtered by the CNN, making the long-term relationships easier to discover.
It goes without question when comparing RNN vs CNN, both are commonplace in the field of Deep Learning. Each architecture has advantages and disadvantages that are dependent upon the type of data that is being modeled. When choosing one framework over the other, or alternatively creating a hybrid approach, the type of data and the job at hand are the most important points to consider.
An RNN is used for cases where the data contains temporal properties, such as a time series. Similarly, where the data is context sensitive, as in the case of sentence completion, the function of memory provided by the feedback loops is critical for adequate performance.
A CNN is the top choice for image classification and more generally, computer vision. In addition, CNNs have been used for myriad tasks, and outperform other machine learning algorithms in some domains. CNNs are not, however, capable of handling a variable-length input.
Finally, a hybrid RNN and CNN approach may be superior when the data is suitable for a CNN, but has temporal characteristics that can be identified and exploited by an RNN component.
Have any questions?
Contact Exxact Today
