Deep Learning
The Unreasonable Progress of Deep Neural Networks in Natural Language Processing (NLP)
June 22, 2020
19 min read


Humans have a lot of senses, and yet our sensory experiences are typically dominated by vision. With that in mind, perhaps it is unsurprising that the vanguard of modern machine learning has been led by computer vision tasks. Likewise, when humans want to communicate or receive information, the most ubiquitous and natural avenue they use is language. Language can be conveyed by spoken and written words, gestures, or some combination of modalities, but for the purposes of this article we’ll focus on the written word (although many of the lessons here overlap with verbal speech as well).
Over the years we’ve seen the field of natural language processing (aka NLP, not to be confused with that NLP) with deep neural networks follow closely on the heels of progress in deep learning for computer vision. With the advent of pre-trained generalized language models, we now have methods for transfer learning to new tasks with massive pre-trained models like GPT-2, BERT, and ELMO. These and similar models are doing real work in the world, both as a matter of everyday course (translation, transcription, etc.), and discovery at the frontiers of scientific knowledge (e.g. predicting advances in material science from publication text [pdf]).
Mastery of language both foreign and native has long been considered an indicator of learned individuals; an exceptional writer or a person that understands multiple languages with good fluency is held in high-esteem, and is expected to be intelligent in other areas as well. Mastering any language to native-level fluency is difficult, imparting an elegant style and/or exceptional clarity even more so. But even typical human proficiency demonstrates an impressive ability to parse complex messages while deciphering substantial coding variations across context, slang, dialects, and the unshakeable confounders of language understanding: sarcasm and satire.
Understanding language remains a hard problem, and despite widespread use in many areas, the challenge of language understanding with machines still presents plenty of unsolved problems. Consider the following ambiguous and strange word or phrase pairs. Ostensibly the members of each pair have the same meaning, but undoubtedly convey distinct nuance. For many of us the only nuance may be a disregard for precision of grammar and language, but refusing to acknowledge common use meanings mostly makes a language model look foolish.
| Couldn’t care less | = (?) | Could care less |
| Irregardless | = (?) | Regardless |
| Literally | = (?) | Figuratively |
| Dynamical | = (?) | Dynamic |

Much of the modern success of deep learning has been due to the utility of transfer learning. Transfer learning allows practitioners to leverage a model’s previous training experience to more quickly learn a novel task. With the raw parameter counts and computational requirements of training state of the art deep networks, transfer learning is essential for the accessibility and efficiency of deep learning in practice. If you are already familiar with the concept of transfer learning, skip ahead to the next section to have a look at the succession of deep NLP models over time.
Transfer learning is a process of fine-tuning: rather than training an entire model from scratch, re-training only those parts of the model which are task-specific can save time and energy of both computational and engineering resources. This is the “don’t be a hero” mentality espoused by Andrej Karpathy, Jeremy Howard, and many others in the deep learning community.
Fundamentally, transfer learning involves retaining the low-level, generic components of a model while only re-training those parts of the model that are specialized. It’s also sometimes advantageous to train the entire pre-trained model after only re-initializing a few task-specific layers.
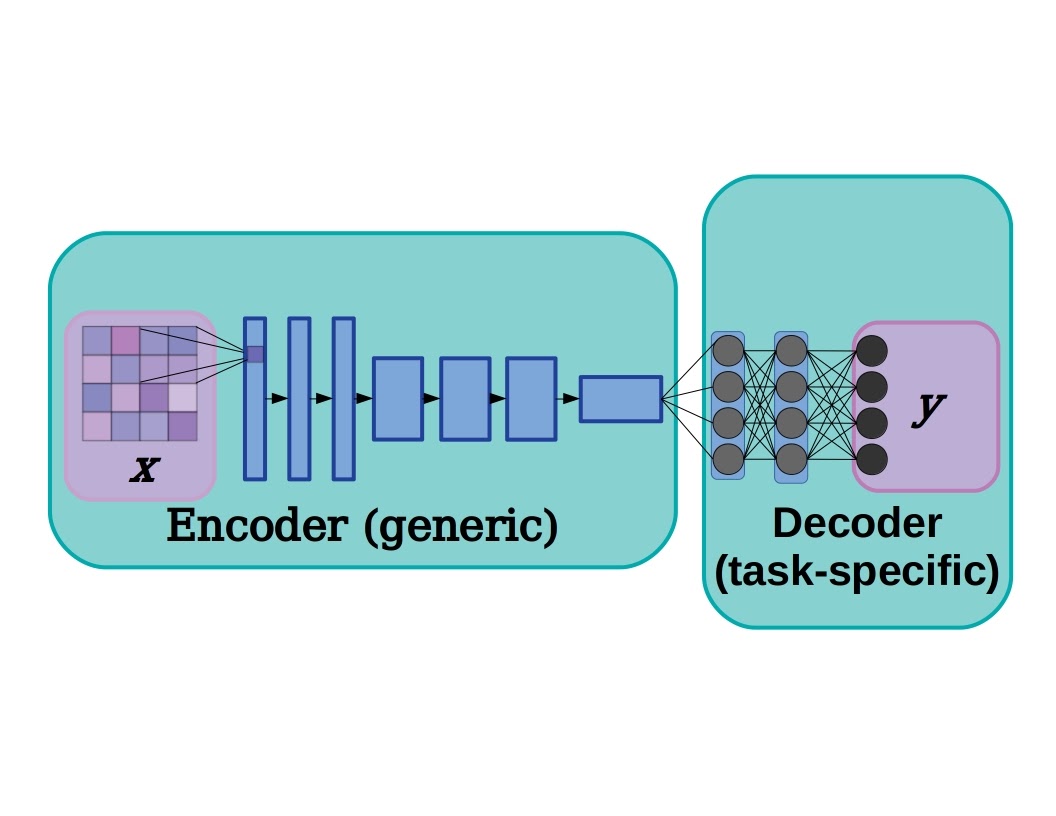 A deep neural network can typically be separated into two sections: an encoder, or feature extractor, that learns to recognize low-level features, and a decoder which transforms those features to a desired output. This cartoon example is based on a simplified network for processing images, with the encoder made up of convolutional layers and the decoder consisting of a few fully connected layers, but the same concept can easily be applied to natural language processing as well.
A deep neural network can typically be separated into two sections: an encoder, or feature extractor, that learns to recognize low-level features, and a decoder which transforms those features to a desired output. This cartoon example is based on a simplified network for processing images, with the encoder made up of convolutional layers and the decoder consisting of a few fully connected layers, but the same concept can easily be applied to natural language processing as well.
In deep learning models there is often a distinction between the encoder, a stack of layers that mainly learns to extract low-level features, and the decoder, the portion of the model that transforms the feature output from the encoder into classifications, pixel segmentations, next-time-step predictions, and so on. Taking a pre-trained model and initializing and re-training a new decoder can achieve state-of-the-art performance in far less training time. This is because lower-level layers tend to learn the most generic features, characteristics like edges, points, and ripples in images (i.e. Gabor filters in image models). In practice, choosing the cutoff between encoder and decoder is more art than science, but see Yosinki et al. 2014 where researchers quantified the transferability of features at different layers.
The same phenomenon can be applied to NLP. A well-trained NLP model trained on a general language modeling task (predicting the next word or character given preceding text) can be fine-tuned to a number of more specific tasks. This saves on the substantial energy and economic costs of training one of these models from scratch, and it’s the reason we have such masterpieces as “AI-generated recipes” by Janelle Shane (top recipes include “chocolate chicken chicken cake”) or a generative text-based dungeon game.
Both of those examples are built on top of OpenAI’s GPT-2, and these and most other generative NLP projects fall squarely into the realm of comedy more than anywhere else. But transfer learning with general-purpose NLP transformers like GPT-2 is quickly sliding down the slope of silliness to the uncanny valley. After that happens, we’ll be on the verge of believability where text generated by machine-learning models can serve as a stand-in for human-written copy. It’s anyone’s guess how close we are to making those leaps, but it’s likely that doesn’t matter as much as one might think. NLP models don’t have to be Shakespeare to generate text that is good enough, some of the time, for some applications. A human operator can cherry-pick or edit the output to achieve desired quality of output.
Natural Language Processing (NLP) progress over the last decade has been substantial. Along the way there have been a number of different approaches to improving performance on tasks like sentiment analysis and the BLEU machine translation benchmark. A number of different architectures have been tried, some of which may be more appropriate for a given task or hardware constraint. In the next few segments, we’ll take a look at the family tree of deep learning NLP models used for language modeling.
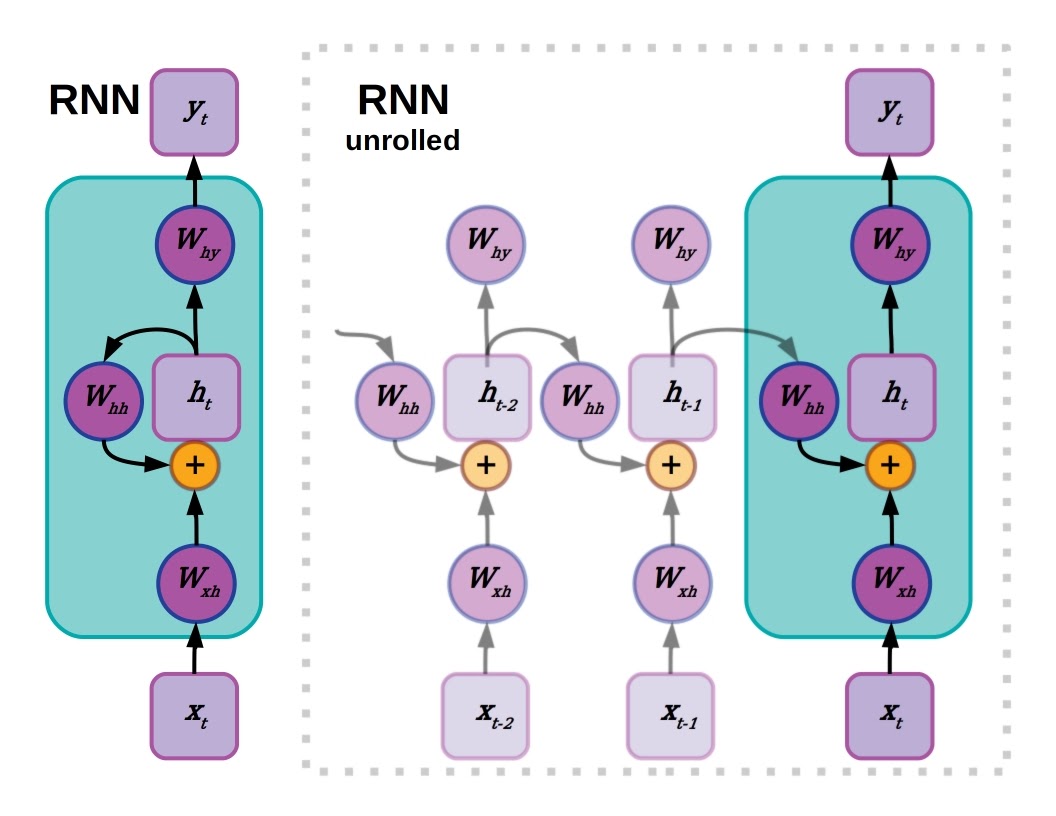 One or more hidden layers in a recurrent neural network has connections to previous hidden layer activations. The key to the graphics in this and other diagrams in this article is below:
One or more hidden layers in a recurrent neural network has connections to previous hidden layer activations. The key to the graphics in this and other diagrams in this article is below:
Language is a type of sequence data. Unlike images, it’s parsed one chunk at a time in a predetermined direction. Text at the beginning of a sentence may have an important relationship to elements later on, and concepts from much earlier in a piece of writing may need to be remembered to make sense of information later on. It makes sense that machine learning models for language should have some sort of memory, and Recurrent Neural Networks (RNNs) implement memory with connections to previous states. The activations in a hidden layer at a given time state depend on the activations from one step earlier, which in turn depend on their preceding values and so on until the beginning of a language sequence.
As the dependency between input/output data can reach far back to the beginning of a sequence, the network is effectively very deep. This can be visualized by “unrolling” the network out to its sequence depth, revealing the chain of operations leading to a given output. This makes for a very pronounced version of the vanishing gradient problem. Because the gradients used to assign credit for mistakes are multiplied by numbers less than 1.0 over each preceding time step, the training signal is continuously attenuated and the training signal for early weights becomes very small. One work-around to the difficulty of training long-term time dependencies in RNNs is to just not.
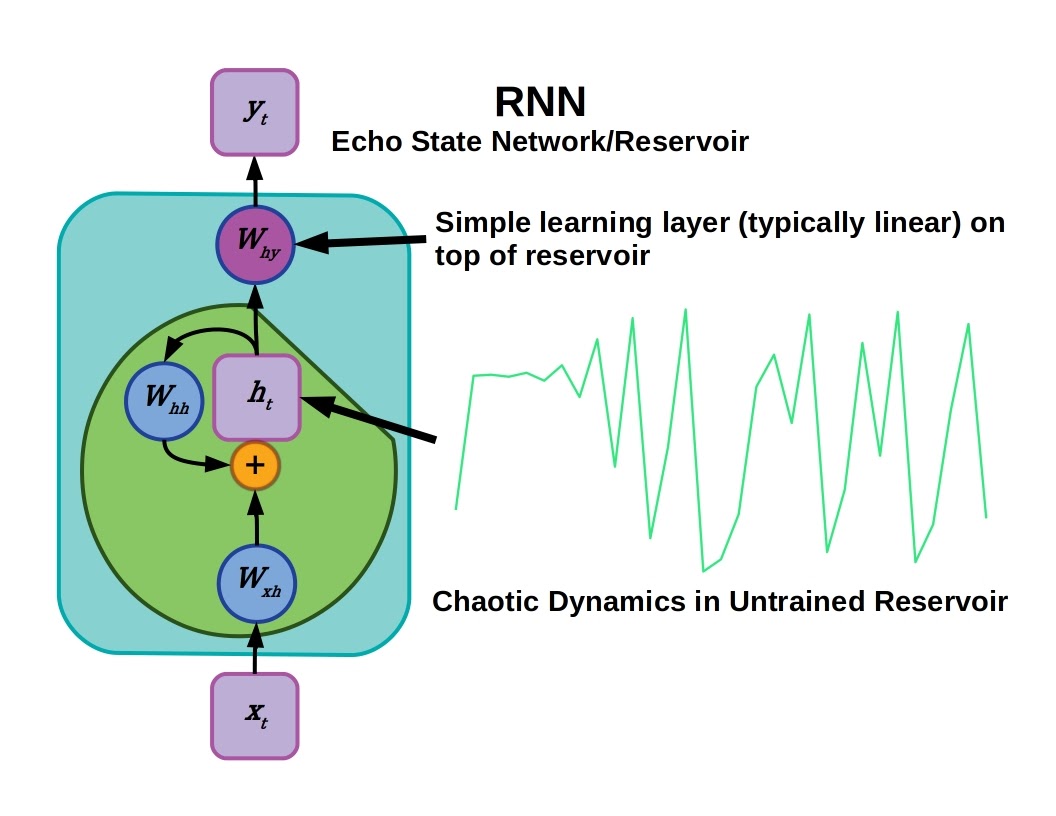
An echo state network is like an RNN but with recurrent connections that use fixed, untrained weights. This fixed part of the network is generally termed a reservoir.
Echo state networks are a sub-class of RNNs that have fixed recurrent connections. Using static recurrent connections avoids the difficulty of training them with vanishing gradients, and in many early applications of RNNs echo state networks outperformed RNNs trained with back-propagation. A simple learning layer, often a fully-connected linear one, parses the dynamic output from the reservoir. This makes training the network easier and it is essential to initialize the reservoir to have complex and sustained, but bounded, output.
Echo state networks have chaotic characteristics in that an early input can have long-lasting effects on the state of the reservoir later on. Therefore the efficacy of echo state networks are due to the “kernel trick” (inputs are transformed non-linearly to a high-dimensional feature space where they can be linearly separated) and chaos. Practically this can be achieved by defining a sparse recurrent connection layer with random weights.
Echo state networks and reservoir computing have largely been superseded by other methods, but their avoidance of the vanishing gradient problem proved useful in several language modeling tasks such as learning grammar or speech recognition. Reservoir computing never made much of an impact in the generalized language modeling that has made NLP transfer learning possible, however.

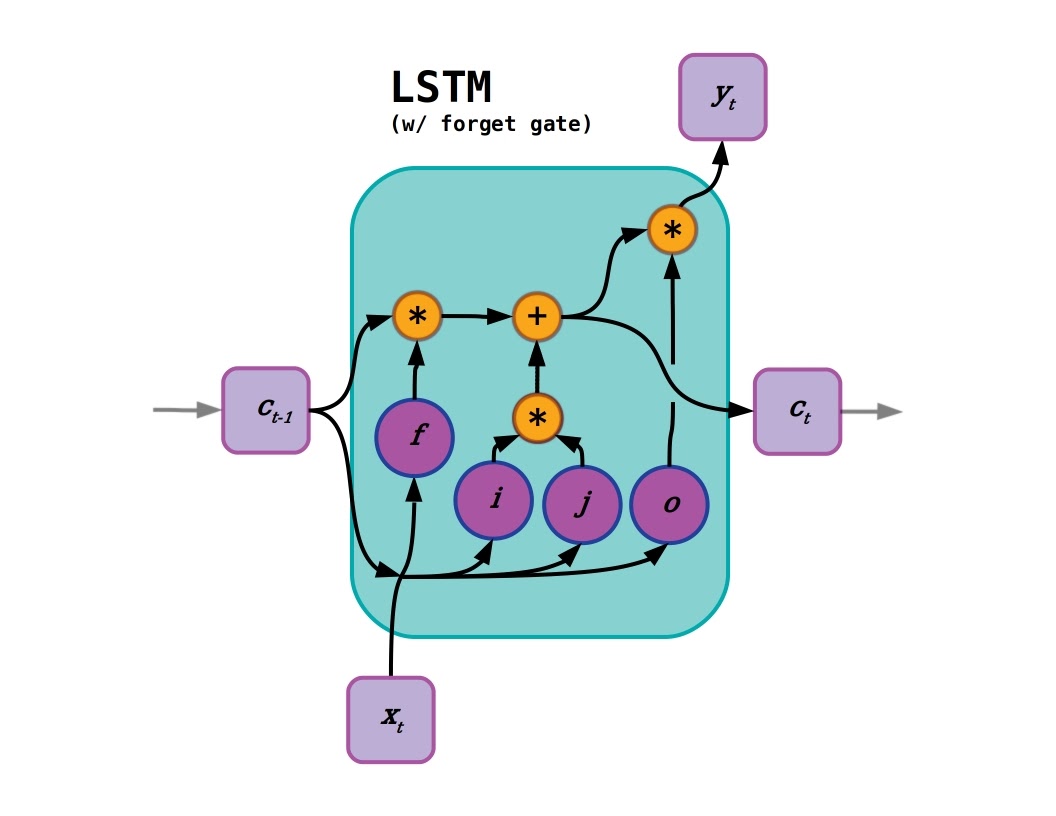
Long short term memory introduced gates to selectively persist activations in so-called cell states.
LSTMs were invented in 1997 by Sepp Hochreiter and Jürgen Schmidhuber [pdf] to address the vanishing gradient problem using a “constant error carousel,” or CEC. The CEC is a persistent gated cell state surrounded by non-linear neural layers that open and close “gates” (values squashed between 0 and 1 using something like a sigmoid activation function). These nonlinear layers choose what information should be incorporated into the cell state activations and determine what to pass to output layers. The cell state layer itself has no activation function, so when its values are passed from time-step to time-step with a gate value of nearly 1.0, gradients can flow backward intact across very long distances in the input sequence. There have been many developments and new versions of LSTMs adapted to improve training, simplify parameter count, and for application to new domains. One of the most useful of these improvements was the forget gate developed by Gers et al. in 2000 (shown in the figure), so much so that the LSTM with forget gate is typically considered the “standard” LSTM.
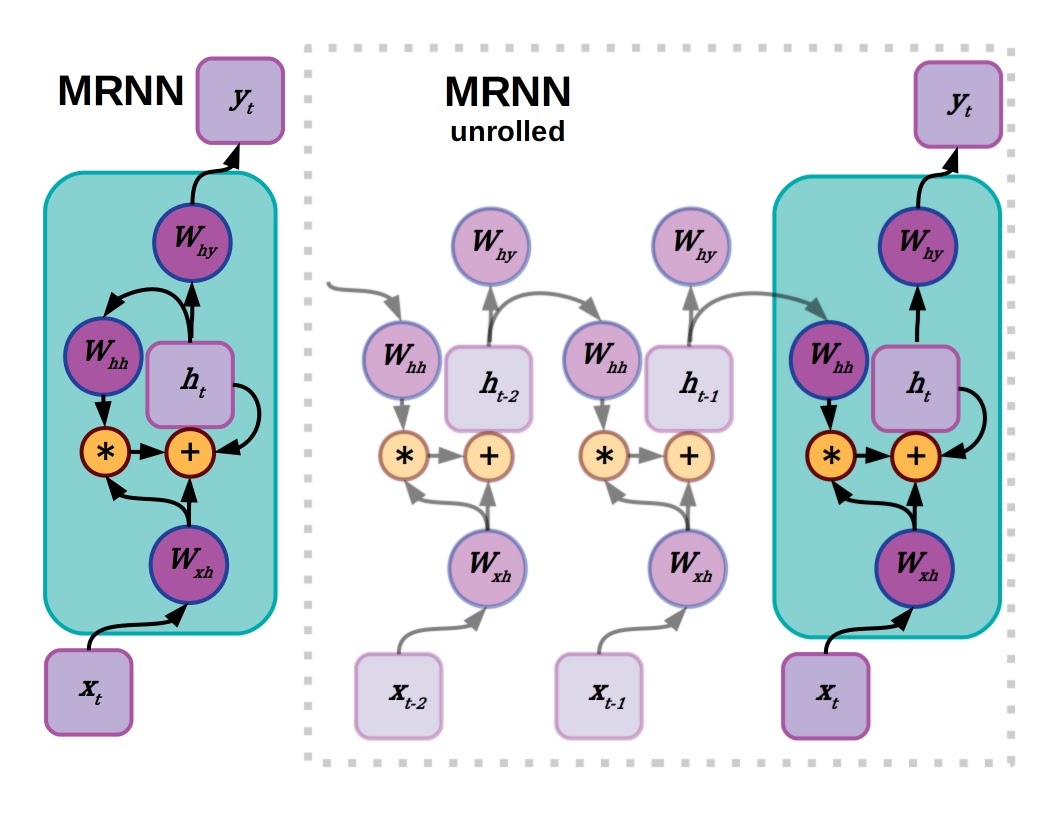
A gated or multiplicative RNN uses an element-wise multiply operation on the output from the last hidden state to determine what will be incorporated into the new hidden state at the current time step.
A gated or multiplicative RNN (MRNN) is a very similar construct to an LSTM, albeit less complicated. Like the LSTM, the MRNN uses a multiplicative operation to gate the last hidden states of the network, and the gate values are determined by a neural layer receiving data from the input. MRNNs were introduced for character-level language modeling in 2011 by Sutskever et al. [pdf] and expanded to gating across depth in deeper MRNNs (gated feedback RNNs) by Chung et al. in 2015. Perhaps because they are a bit simpler, MRNNs and gated feedback RNNs can outperform LSTMs on some language modeling scenarios, depending on who is handling them.
LSTMs with forget gates have been the basis for a wide variety of high-profile natural language processing models, including OpenAI’s “Unsupervised Sentiment Neuron” (paper) and a big jump in performance in Google’s Neural Machine Translation model in 2016. Following on the demonstration of transfer learning from the Unsupervised Sentiment Neuron model. Sebastian Ruder and Jeremy Howard developed Unsupervised Language Model Fine-tuning for Text Classification (ULM-FiT), which leveraged pre-training to attain state-of-the-art performance on six specific text classification datasets.
Although absent from ULM-FiT and Unsupervised Sentiment Neuron, a key component of the improvements in Google’s LSTM-based translation network was the liberal application of attention, and not just engineering attention but the specific machine learning concept of learning to attend to specific parts of input data. Attention applied to NLP models was such a powerful idea that it led to the next generation of language models, and it is arguably responsible for the current efficacy of transfer learning in NLP.
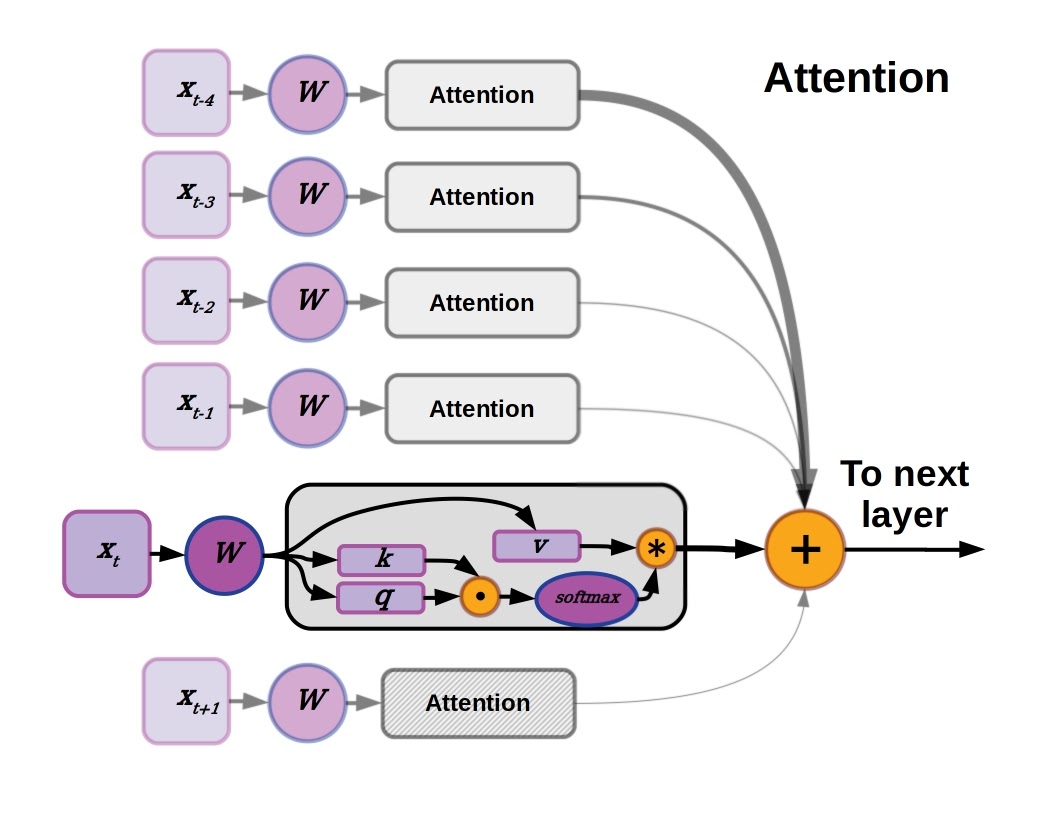
Graphic description of the attention mechanism concept used in the transformer model from “Attention is all you Need.” At a given point in a sequence and for each data vector, a weight matrix generates key, query, and value tensors. The attention mechanism uses the key and query vectors to weight the value vector, which will be subjected to a softmax activation along with all the other key, query, value sets and summed to produce the input to the next layer.
The attention mechanism used in language models like Google’s 2016 NMT network worked well enough, and at a time when machine learning hardware accelerators had become powerful enough, to lead developers to the question “What if we just use attention on its own?” As we now know the answer is that attention is all you need to achieve state-of-the-art NLP models (which is the name of the paper introducing the attention only model architecture).
These models are known as transformers,and unlike LSTMs and other RNNs, transformers consider an entire sequence at the same time. They learn to use attention to weight the influence of each point in the input text sequence. A simple explanation of the attention mechanism used by the original Transformer model accompanies the figure above, but more in-depth explanation can be had from the paper or this blog post by Jay Alammar.
Considering the entire sequence at the same time might seem like it limits the model to parsing sequences of the same fixed length that it was trained on, unlike models with recurrent connection. However, transformers make use of a positional encoding (in the original Transformer, it is based on a sinusoidal embedding vector) that can facilitate forward passes with variable input sequence lengths. The all-at-once approach of transformer architectures does incur a stiff memory requirement, but it’s efficient to train on high-end modern hardware and streamlining the memory and computational requirements of transformers is at the forefront of current and recent developments in the space.
Deep NLP has certainly come into its own in the last two to three years, and it’s starting to spread effectively into applications beyond the highly-visible niches of machine translation and silly text generation. NLP development continues to follow in the figurative footsteps of computer vision, and unfortunately that includes many of the same mis-steps, trips, and stumbles as we’ve seen before.
One of the most pressing challenges is the “Clever Hans Effect,” named after a famous performing horse of the early 20th century. In short, Hans was a German horse that was exhibited to the public as an arithmetically gifted equine, able to answer questions involving dates and counting. In fact he was instead an expert in interpreting subconscious cues given by his trainer, Wilhelm von Osten. In machine learning, the Clever Hans effect refers to models achieving impressive, but ultimately useless, performance by learning spurious correlations in the training dataset.
Examples include classifying pneumonia in x-rays based on recognizing the type of machine used at hospitals with sicker patients, answering questions about people described in a text by just repeating the last mentioned name, and modern phrenology. While most NLP projects produce only a comedy of errors when they don’t work properly (e.g. the recipe and dungeon generators mentioned above), a lack of understanding of how NLP and other machine learning models break down paves the way for justifications of modern pseudoscience and correspondingly bad policy. It’s also bad for business. Imagine spending thousands or millions of dollars on developing NLP-enabled search for a clothing store that returns search queries for stripeless shirts results like those in the Shirt without Stripes Github repo.
It’s clear that, while recent advances have made deep NLP more effective and accessible, the field has a long way to go before demonstrating anything close to human understanding or synthesis. Despite its shortcomings (no Cortana, nobody wants you to route every utterance into an internet search on Edge browser), NLP is the basis of many products and tools in wide use today. Directly in line with the shortcomings of NLP, the need for systematic rigor in evaluating language models has never been clearer. There’s clearly important work to be done not just in improving models and datasets, but also in breaking those models in informative ways.

Humans have a lot of senses, and yet our sensory experiences are typically dominated by vision. With that in mind, perhaps it is unsurprising that the vanguard of modern machine learning has been led by computer vision tasks. Likewise, when humans want to communicate or receive information, the most ubiquitous and natural avenue they use is language. Language can be conveyed by spoken and written words, gestures, or some combination of modalities, but for the purposes of this article we’ll focus on the written word (although many of the lessons here overlap with verbal speech as well).
Over the years we’ve seen the field of natural language processing (aka NLP, not to be confused with that NLP) with deep neural networks follow closely on the heels of progress in deep learning for computer vision. With the advent of pre-trained generalized language models, we now have methods for transfer learning to new tasks with massive pre-trained models like GPT-2, BERT, and ELMO. These and similar models are doing real work in the world, both as a matter of everyday course (translation, transcription, etc.), and discovery at the frontiers of scientific knowledge (e.g. predicting advances in material science from publication text [pdf]).
Mastery of language both foreign and native has long been considered an indicator of learned individuals; an exceptional writer or a person that understands multiple languages with good fluency is held in high-esteem, and is expected to be intelligent in other areas as well. Mastering any language to native-level fluency is difficult, imparting an elegant style and/or exceptional clarity even more so. But even typical human proficiency demonstrates an impressive ability to parse complex messages while deciphering substantial coding variations across context, slang, dialects, and the unshakeable confounders of language understanding: sarcasm and satire.
Understanding language remains a hard problem, and despite widespread use in many areas, the challenge of language understanding with machines still presents plenty of unsolved problems. Consider the following ambiguous and strange word or phrase pairs. Ostensibly the members of each pair have the same meaning, but undoubtedly convey distinct nuance. For many of us the only nuance may be a disregard for precision of grammar and language, but refusing to acknowledge common use meanings mostly makes a language model look foolish.
| Couldn’t care less | = (?) | Could care less |
| Irregardless | = (?) | Regardless |
| Literally | = (?) | Figuratively |
| Dynamical | = (?) | Dynamic |
Much of the modern success of deep learning has been due to the utility of transfer learning. Transfer learning allows practitioners to leverage a model’s previous training experience to more quickly learn a novel task. With the raw parameter counts and computational requirements of training state of the art deep networks, transfer learning is essential for the accessibility and efficiency of deep learning in practice. If you are already familiar with the concept of transfer learning, skip ahead to the next section to have a look at the succession of deep NLP models over time.
Transfer learning is a process of fine-tuning: rather than training an entire model from scratch, re-training only those parts of the model which are task-specific can save time and energy of both computational and engineering resources. This is the “don’t be a hero” mentality espoused by Andrej Karpathy, Jeremy Howard, and many others in the deep learning community.
Fundamentally, transfer learning involves retaining the low-level, generic components of a model while only re-training those parts of the model that are specialized. It’s also sometimes advantageous to train the entire pre-trained model after only re-initializing a few task-specific layers.
A deep neural network can typically be separated into two sections: an encoder, or feature extractor, that learns to recognize low-level features, and a decoder which transforms those features to a desired output. This cartoon example is based on a simplified network for processing images, with the encoder made up of convolutional layers and the decoder consisting of a few fully connected layers, but the same concept can easily be applied to natural language processing as well.
In deep learning models there is often a distinction between the encoder, a stack of layers that mainly learns to extract low-level features, and the decoder, the portion of the model that transforms the feature output from the encoder into classifications, pixel segmentations, next-time-step predictions, and so on. Taking a pre-trained model and initializing and re-training a new decoder can achieve state-of-the-art performance in far less training time. This is because lower-level layers tend to learn the most generic features, characteristics like edges, points, and ripples in images (i.e. Gabor filters in image models). In practice, choosing the cutoff between encoder and decoder is more art than science, but see Yosinki et al. 2014 where researchers quantified the transferability of features at different layers.
The same phenomenon can be applied to NLP. A well-trained NLP model trained on a general language modeling task (predicting the next word or character given preceding text) can be fine-tuned to a number of more specific tasks. This saves on the substantial energy and economic costs of training one of these models from scratch, and it’s the reason we have such masterpieces as “AI-generated recipes” by Janelle Shane (top recipes include “chocolate chicken chicken cake”) or a generative text-based dungeon game.
Both of those examples are built on top of OpenAI’s GPT-2, and these and most other generative NLP projects fall squarely into the realm of comedy more than anywhere else. But transfer learning with general-purpose NLP transformers like GPT-2 is quickly sliding down the slope of silliness to the uncanny valley. After that happens, we’ll be on the verge of believability where text generated by machine-learning models can serve as a stand-in for human-written copy. It’s anyone’s guess how close we are to making those leaps, but it’s likely that doesn’t matter as much as one might think. NLP models don’t have to be Shakespeare to generate text that is good enough, some of the time, for some applications. A human operator can cherry-pick or edit the output to achieve desired quality of output.
Natural Language Processing (NLP) progress over the last decade has been substantial. Along the way there have been a number of different approaches to improving performance on tasks like sentiment analysis and the BLEU machine translation benchmark. A number of different architectures have been tried, some of which may be more appropriate for a given task or hardware constraint. In the next few segments, we’ll take a look at the family tree of deep learning NLP models used for language modeling.
One or more hidden layers in a recurrent neural network has connections to previous hidden layer activations. The key to the graphics in this and other diagrams in this article is below:
Language is a type of sequence data. Unlike images, it’s parsed one chunk at a time in a predetermined direction. Text at the beginning of a sentence may have an important relationship to elements later on, and concepts from much earlier in a piece of writing may need to be remembered to make sense of information later on. It makes sense that machine learning models for language should have some sort of memory, and Recurrent Neural Networks (RNNs) implement memory with connections to previous states. The activations in a hidden layer at a given time state depend on the activations from one step earlier, which in turn depend on their preceding values and so on until the beginning of a language sequence.
As the dependency between input/output data can reach far back to the beginning of a sequence, the network is effectively very deep. This can be visualized by “unrolling” the network out to its sequence depth, revealing the chain of operations leading to a given output. This makes for a very pronounced version of the vanishing gradient problem. Because the gradients used to assign credit for mistakes are multiplied by numbers less than 1.0 over each preceding time step, the training signal is continuously attenuated and the training signal for early weights becomes very small. One work-around to the difficulty of training long-term time dependencies in RNNs is to just not.
An echo state network is like an RNN but with recurrent connections that use fixed, untrained weights. This fixed part of the network is generally termed a reservoir.
Echo state networks are a sub-class of RNNs that have fixed recurrent connections. Using static recurrent connections avoids the difficulty of training them with vanishing gradients, and in many early applications of RNNs echo state networks outperformed RNNs trained with back-propagation. A simple learning layer, often a fully-connected linear one, parses the dynamic output from the reservoir. This makes training the network easier and it is essential to initialize the reservoir to have complex and sustained, but bounded, output.
Echo state networks have chaotic characteristics in that an early input can have long-lasting effects on the state of the reservoir later on. Therefore the efficacy of echo state networks are due to the “kernel trick” (inputs are transformed non-linearly to a high-dimensional feature space where they can be linearly separated) and chaos. Practically this can be achieved by defining a sparse recurrent connection layer with random weights.
Echo state networks and reservoir computing have largely been superseded by other methods, but their avoidance of the vanishing gradient problem proved useful in several language modeling tasks such as learning grammar or speech recognition. Reservoir computing never made much of an impact in the generalized language modeling that has made NLP transfer learning possible, however.
Long short term memory introduced gates to selectively persist activations in so-called cell states.
LSTMs were invented in 1997 by Sepp Hochreiter and Jürgen Schmidhuber [pdf] to address the vanishing gradient problem using a “constant error carousel,” or CEC. The CEC is a persistent gated cell state surrounded by non-linear neural layers that open and close “gates” (values squashed between 0 and 1 using something like a sigmoid activation function). These nonlinear layers choose what information should be incorporated into the cell state activations and determine what to pass to output layers. The cell state layer itself has no activation function, so when its values are passed from time-step to time-step with a gate value of nearly 1.0, gradients can flow backward intact across very long distances in the input sequence. There have been many developments and new versions of LSTMs adapted to improve training, simplify parameter count, and for application to new domains. One of the most useful of these improvements was the forget gate developed by Gers et al. in 2000 (shown in the figure), so much so that the LSTM with forget gate is typically considered the “standard” LSTM.
A gated or multiplicative RNN uses an element-wise multiply operation on the output from the last hidden state to determine what will be incorporated into the new hidden state at the current time step.
A gated or multiplicative RNN (MRNN) is a very similar construct to an LSTM, albeit less complicated. Like the LSTM, the MRNN uses a multiplicative operation to gate the last hidden states of the network, and the gate values are determined by a neural layer receiving data from the input. MRNNs were introduced for character-level language modeling in 2011 by Sutskever et al. [pdf] and expanded to gating across depth in deeper MRNNs (gated feedback RNNs) by Chung et al. in 2015. Perhaps because they are a bit simpler, MRNNs and gated feedback RNNs can outperform LSTMs on some language modeling scenarios, depending on who is handling them.
LSTMs with forget gates have been the basis for a wide variety of high-profile natural language processing models, including OpenAI’s “Unsupervised Sentiment Neuron” (paper) and a big jump in performance in Google’s Neural Machine Translation model in 2016. Following on the demonstration of transfer learning from the Unsupervised Sentiment Neuron model. Sebastian Ruder and Jeremy Howard developed Unsupervised Language Model Fine-tuning for Text Classification (ULM-FiT), which leveraged pre-training to attain state-of-the-art performance on six specific text classification datasets.
Although absent from ULM-FiT and Unsupervised Sentiment Neuron, a key component of the improvements in Google’s LSTM-based translation network was the liberal application of attention, and not just engineering attention but the specific machine learning concept of learning to attend to specific parts of input data. Attention applied to NLP models was such a powerful idea that it led to the next generation of language models, and it is arguably responsible for the current efficacy of transfer learning in NLP.
Graphic description of the attention mechanism concept used in the transformer model from “Attention is all you Need.” At a given point in a sequence and for each data vector, a weight matrix generates key, query, and value tensors. The attention mechanism uses the key and query vectors to weight the value vector, which will be subjected to a softmax activation along with all the other key, query, value sets and summed to produce the input to the next layer.
The attention mechanism used in language models like Google’s 2016 NMT network worked well enough, and at a time when machine learning hardware accelerators had become powerful enough, to lead developers to the question “What if we just use attention on its own?” As we now know the answer is that attention is all you need to achieve state-of-the-art NLP models (which is the name of the paper introducing the attention only model architecture).
These models are known as transformers,and unlike LSTMs and other RNNs, transformers consider an entire sequence at the same time. They learn to use attention to weight the influence of each point in the input text sequence. A simple explanation of the attention mechanism used by the original Transformer model accompanies the figure above, but more in-depth explanation can be had from the paper or this blog post by Jay Alammar.
Considering the entire sequence at the same time might seem like it limits the model to parsing sequences of the same fixed length that it was trained on, unlike models with recurrent connection. However, transformers make use of a positional encoding (in the original Transformer, it is based on a sinusoidal embedding vector) that can facilitate forward passes with variable input sequence lengths. The all-at-once approach of transformer architectures does incur a stiff memory requirement, but it’s efficient to train on high-end modern hardware and streamlining the memory and computational requirements of transformers is at the forefront of current and recent developments in the space.
Deep NLP has certainly come into its own in the last two to three years, and it’s starting to spread effectively into applications beyond the highly-visible niches of machine translation and silly text generation. NLP development continues to follow in the figurative footsteps of computer vision, and unfortunately that includes many of the same mis-steps, trips, and stumbles as we’ve seen before.
One of the most pressing challenges is the “Clever Hans Effect,” named after a famous performing horse of the early 20th century. In short, Hans was a German horse that was exhibited to the public as an arithmetically gifted equine, able to answer questions involving dates and counting. In fact he was instead an expert in interpreting subconscious cues given by his trainer, Wilhelm von Osten. In machine learning, the Clever Hans effect refers to models achieving impressive, but ultimately useless, performance by learning spurious correlations in the training dataset.
Examples include classifying pneumonia in x-rays based on recognizing the type of machine used at hospitals with sicker patients, answering questions about people described in a text by just repeating the last mentioned name, and modern phrenology. While most NLP projects produce only a comedy of errors when they don’t work properly (e.g. the recipe and dungeon generators mentioned above), a lack of understanding of how NLP and other machine learning models break down paves the way for justifications of modern pseudoscience and correspondingly bad policy. It’s also bad for business. Imagine spending thousands or millions of dollars on developing NLP-enabled search for a clothing store that returns search queries for stripeless shirts results like those in the Shirt without Stripes Github repo.
It’s clear that, while recent advances have made deep NLP more effective and accessible, the field has a long way to go before demonstrating anything close to human understanding or synthesis. Despite its shortcomings (no Cortana, nobody wants you to route every utterance into an internet search on Edge browser), NLP is the basis of many products and tools in wide use today. Directly in line with the shortcomings of NLP, the need for systematic rigor in evaluating language models has never been clearer. There’s clearly important work to be done not just in improving models and datasets, but also in breaking those models in informative ways.



