Deep Learning
Timeline & Review of OpenAI's Robotic Hand Project
December 3, 2019
17 min read



An impossible scramble. This scramble is impossible to solve using any known Rubik's Cube algorithms without employing disassembly methods(let alone a robotic hand). Cube state rendered with MagicCube
Good robotics control is hard. Plain and simple as that. Don't let the periodic videos from Boston Dynamics fool you: pulling off untethered back-flips and parkour are very rare skills for robots. In fact, as was readily apparent at the 2015 DARPA Robotics Challenge, falls and failures are the standard operating mode for state-of-the-art robots in the (somewhat fake) real world.
The robot that finished in third place, CHIMP from Carnegie Mellon University, made use of a relatively safe forward fall and recovery strategy by design. These robots were the result of many months of work by clever professionals working out of some of the world's best robotics labs.
We might call the falls and failures experienced by robots in complex environments "teachable moments." However, there is little to no machine learning in classical robotics control (Boston Dynamics CEO Marc Raibert indicates their robots use no learning at all). Most robots attempting comparatively open-ended tasks like the DARPA challenge also have to fall back on remote (human) operation when things go sideways.

Reinforcement learning (RL) is famously hard as well. RL makes short work of a few basic toy environments and beats human performance at some video and board games, but in more complicated situations RL continues to suffer from combinatorial explosions arising from several sources.
Combined with the challenge of interpreting deep learning models, the combinatorial explosion of complex environments, and its effect on RL training accounts for why machine learning in autonomous automobiles isn't end-to-end. It is largely limited to computer vision tasks (although simplified end-to-end lane-keeping is viable).
You may be tempted to conclude that if robotics control in complex environments is hard and reinforcement learning outside of toy problems is hard, combining the two challenges would be doubly futile. However, OpenAI, and roughly 13,000 years of simulation time, would like to advocate a different perspective, exemplified by single-handedly solving the Rubik's cube puzzle with reinforcement learning.
Enabling generally capable robots has been one of OpenAI's core technical objectives since its first year of operation. If the cortical homunculus is any indication, fine motor control of general-purpose end effectors (aka hands) is a pretty big chunk of what's needed for general intelligence.
As a representative task of general learning for dexterous manipulation, OpenAI chose to focus on manipulating a Rubik's cube from scrambled to solved states and vice-versa. The pre-print publication and demonstration by OpenAI in October 2019 was the culmination of 2 years worth of work. The process incorporated incremental progress and techniques from several core lines of research pursued by the organization.
On the theoretical side of solving a Rubik's cube, Thomas Rokicki and Morley Davidson showed in 2014 that any scramble of a 3x3 Rubik's cube can be solved in 26 moves or less. As for the physical part of the problem, the unofficial record for fastest robot solve is the Rubik's Contraption by Ben Katz and Jared Di Carlo at ~0.38 seconds, slightly better than the record maintained by Guinness achieved by Albert Beer's Sub1 Reloaded (0.637 seconds). And funnily enough, Rubik's Contraption additionally makes a fairly efficient cube destroyer (shown in the video below).
If the Rubik's cube puzzle has essentially been solved computationally, and robots been built that can solve the cube faster than the mechanical limits of the cube itself, why is robotic hand Rubik's cube manipulation still an interesting problem? Most robotics applications are highly specialized for superhuman performance but only excel at one particular task.
These are the kind of robots that build rockets, perform high-throughput biological screening, sort pancakes, and in general fuel much of the fear and uncertainty in human-robot relations. But these special-purpose robots don't come close to the multi-purpose manipulation capabilities of a human hand. Giving a robotic hand the versatile problem-solving that humans pride themselves on requires general-purpose learning algorithms and effector mechanics, and it's the sort of capability we need if robotics is to make a positive impact in our lives outside of tightly controlled environments.
Rubik's Contraption may be able to solve cubes quickly, but you'd hardly want a robot that operates like that to perform care duties for ill loved ones. Robotics need general-purpose flexibility if they are to share living and working spaces with humans and to enable far-flung autonomy in roles that may help humans to explore the universe. Modern robotics up to this point are largely tools, but the future will see robots become tool-users.
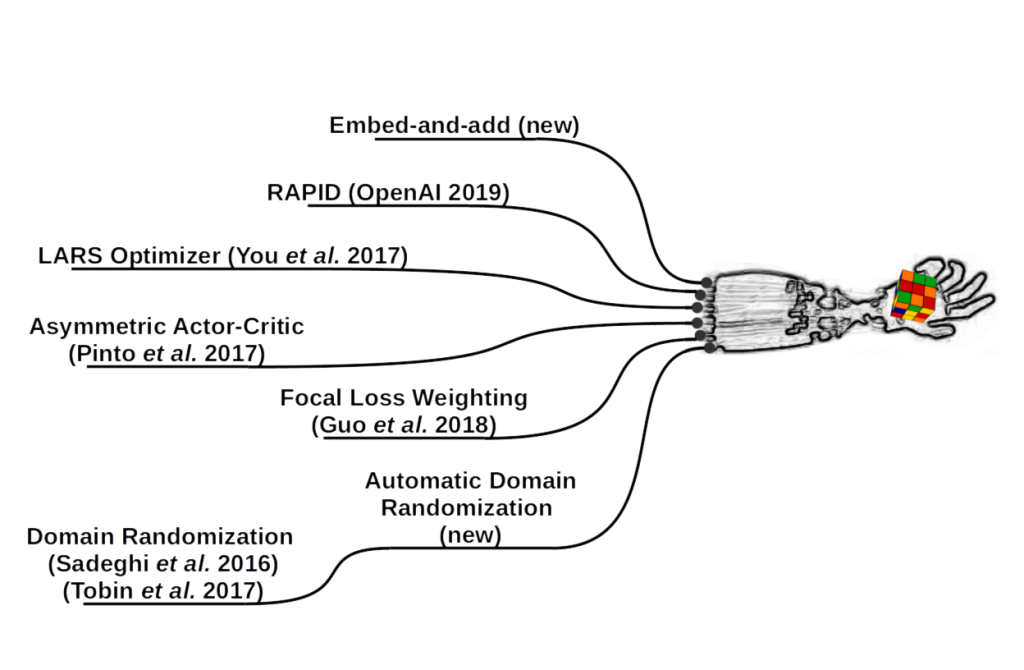
Elements of dexterous in-hand puzzle-solving leading up to the current work. This graphic was made in part using a photograph CC BY SA The Shadow Robotics company.
Let's get one thing out of the way: the dexterous in-hand manipulation project undertaken at OpenAI is not about solving the Rubik's cube puzzle in the sense of determining a sequence of movements to match up all the colors on each side. Rather the project focused on executing said movements with a customized version of the Shadow Robotics Hand while using Kociemba's algorithm to determine which moves to attempt.
This was misleadingly cited to be a major point of contention in some reports. Gary Marcus rephrased the point 3 times in a list of 7 criticisms. The use of Kociemba's algorithm is mentioned prominently in both the paper and the blog post by OpenAI, and the same language was used to describe similar work by another group with a 2x2 cube in simulation only. It doesn't seem that the language used was unusual or highly likely to be misunderstood by interested parties. All-in-all, this criticism is not very interesting (which is not to say there aren't legitimate critiques to be made), and in any case, deep reinforcement learning has also been used to tackle the problem of determining which moves to make to solve a scrambled cube.
It's widely accepted in the field of artificial intelligence that tasks requiring a high degree of logical or analytical reasoning (things that humans would generally classify as difficult) are actually much easier for machines whether by following explicit programming or through machine learning. Perception and mobility both remain more challenging. It's a plausible explanation for why Deep Blue managed to beat Gary Kasparov, the best chess player in the world at the time.
Machines still lag far behind humans in many tasks, including dexterous object manipulation, and especially tasks requiring generalization. The idea that perception and mobility are more difficult than reasoning was observed by prominent AI researchers in the 1980s, most notably Hans Moravec, Marvin Minsky, and Rodney Brooks. This is now known as Moravec's paradox.
The manipulation project at OpenAI started in 2017, and the most recent results relied on a number of clever tricks developed both internally by OpenAI and more broadly by the machine and reinforcement learning communities. In July 2018 they succeeded in the intermediate step of teaching a robotic hand to orient a simple block, but to learn the more complex movements needed to rotate the faces of a Rubik's cube they needed to develop a few new tricks.
Reportedly, it took about 13,000 simulated years of training to achieve sim2real transfer to the physical robotic hand, and anyone of the techniques mentioned called out in the graphic could be responsible for 3x or so of training efficiency. For example, in experiments from the paper, manual domain randomization was at least 3x slower than using automatic domain randomization (and setting the level of randomization poorly can make it even worse). With multiple facets affecting training synergistically, it's entirely possible that training could have taken years instead of months had they not been brought together effectively.
We'll focus on two key novel contributions discussed in the paper: automatic domain randomization and embed-and-add observations, but the other tricks and links to the original research are listed in Table 1 below. Finally, we'll discuss perhaps the most interesting result from the project: the emergence of meta-learning. This allowed the control policy to adapt to changing physics (in simulation) and perturbations like gloved manipulation (in the real world).
| Technique | Origin |
|---|---|
| (Automatic) Domain Randomization | Sadeghi et al. 2016, Tobin et al 2017, and (current paper 2019) |
| Embed-and-add observations vector | current paper 2019 |
| Focal loss weighting | Guo et al. 2018 |
| Rapid | OpenAI 2019 |
| LARS optimizer | You et al. 2017 |
| Asymmetric Actor-Critic Architecture | Pinto et al. 2017 |
| Visualization and interpretability | Olah et al. 2018 |
Table 1: non-exhaustive list of techniques incorporated into the cube manipulation project and their origins.
The application of machine learning to robotics has historically been limited by the physical constraints of robotics platforms. Robots tend to be expensive and slow compared to simulation, but unfortunately, training in simulated environments leads to overfitting and poor transfer to the real world. Domain randomization is one way to overcome these problems. Domain randomization has been a crucial part of learning image-based drone navigation and pinpointing blocks (and spam) for grasping.
Effective training in simulation is limited because it is difficult to get all the details to match reality closely. Even with high-fidelity simulations, the parameters will vary somewhat from one robot to the next and over time as physical parts wear out, temperature drifts, etc. To get around this problem while still taking advantage of the massive data availability from simulation training, domain randomization adds noise to the parameters of the simulated environment. These can be visual parameters like texture and color, physical variables like friction and joint hysteresis, or even departures from normal physics like the gravitational constant. In previous work, the level of domain randomization was set via the human guess-and-check method. Getting the level of randomization wrong can lead to
Automatic Domain Randomization, as the name suggests, makes this process adaptive. In each episode simulation, each parameter is sampled from a normal distribution of possible values, but the parameters of the distribution are automatically adjusted as performance increases. This results in training that is about 3 times faster than using manual domain randomization on the Rubik's cube task. The benefits of ADR versus manual DR at a poorly chosen level are much greater. A low level of randomization leads to policies that never transfer skills well, no matter how long they are trained. Set the DR level too high, on the other hand, and training may take forever.
The Rubik's cube manipulation segment of OpenAI's dexterous manipulation involved several months of continuous training, but researchers were constantly tweaking the parameters and conditions experienced by the simulated robots. Sometimes this entailed changing or adding observations available to the policy, which would normally necessitate changing the dimensions of the first layer to compensate, throwing off training significantly. To get around this they used a fixed size latent space in the shape of a 512 element vector, embedding various observations as needed. This strikes me as an interesting way to get around variable input/output dimensions and is worth investigating further.
If we're limited to only one aspect of the paper to take away, it's the emergent meta-learning observed by OpenAI. As discussed above, domain randomization is required for skills learned in simulation to transfer to real-world scenarios and from robot to robot. What is perhaps less obvious, is that using domain randomization (especially the adaptive variant discussed here) not only allows skill transfer but also enables skill adaptation. Presumably, when an agent is faced with environments that are too complex to memorize they learn relational rules instead, allowing the agent to calibrate its policy based on experience acquired during test time. I suspect this concept of "learning to learn" will become increasingly important in real-world AI tasks.
The most impressive results regarding meta-learning in the Rubik's cube manipulation task were shown in simulation: the authors showed that they were able to change the physics of the simulation mid-run and the policy was able to recover. Even a disabled finger joint did not stop the policy from adapting. Although manipulation efficiency after breaking a finger didn't recover to whole-handed levels, it was comparable to a broken-finger baseline. In the real world, the effect of meta-learning is translated to solving the task under a variety of perturbations. Some of the challenges (such as poking with a plush giraffe) may seem silly, but the implication is that a control policy learned in this way should be able to cope with mechanical drift and degradation as well as variable environments.
Earlier we mentioned that there were far more interesting critiques of OpenAI's paper than the fact that they used Kociemba's algorithm for planning. That's the premise of this section.
The performance wasn't that good, and they only reported a small number of trials on the physical robot. In physical tests, OpenAI only reports ten attempts each at completing a sequence of moves to solve a full or partial scramble. In the former case, only 2 of the 10 sequences were completed successfully without dropping, while the latter finished 6 times without fail. These results aren't great, but in light of the failure modes, they are pretty good.
Dropping the cube doesn't seem like it should be such a terminal event: learning to pick up the cube wouldn't be harder than learning to manipulate the cube (though it would entail hardware changes) and humans in competition regularly use the table surface as an assist during one-handed solves. The limited number of attempts is much more questionable, as 10 attempts under each condition are far too few to get a good idea of how capable the policy is. Another issue is that the physical solves were typically attempted in reverse (starting from unscrambled to scrambled) and followed a static sequence of moves, decreasing variety. I would have much rather seen the results include a variety of move sequences carried out over many more trials.
They almost managed to solve visual perception for the task but had to fall back on a Giiker cube with embedded position sensing. Part of the objective of this project was to use three RGB cameras and a set of vision networks to estimate cube pose and state. Unfortunately relying solely on vision dropped manipulation performance by more than half and the success rate on the partially scrambled solve task from 60% to 20% (the full scramble was not solvable using the vision model alone). It's unfortunate that solving vision and manipulation simultaneously proved to be too much. On the other hand, they did continue to use the vision models for inferring pose in all their physical tests, which is pretty dang good.
Proprioception, or sensing of the robotic hand position, would have made the manipulation feats that much more impressive. Instead, they used a very fancy motion tracking system from PhaseSpace that used LEDs blinking with encoded identification patterns as motion capture tags. The need for sophisticated point motion tracking be in large part due to limitations of the robotic hand instrumentation itself, but the gloved robotic hand manipulations would have been much more impressive had they managed it with the fingertips covered as well.
The hype cycle surrounding each new robotics breakthrough always seems to involve some cultivation of fear. This is often exaggerated to the point of parody (e.g. referencing our "our new robot overlords"), but the root of robot-related anxiety stems from the uncertainty and risk associated with a rapidly changing world. Robotics has and will continue to change the way we live and work.
It might not always be easy to adapt, but the flexible capabilities of human intelligence are not likely to become entirely obsolete any time soon. In case there is any doubt about remaining human relevance (at least for deftly solving Rubik's cubes) I'd like to sign off with the following performance by competitive cuber Feliks Zemdegs

An impossible scramble. This scramble is impossible to solve using any known Rubik's Cube algorithms without employing disassembly methods(let alone a robotic hand). Cube state rendered with MagicCube
Good robotics control is hard. Plain and simple as that. Don't let the periodic videos from Boston Dynamics fool you: pulling off untethered back-flips and parkour are very rare skills for robots. In fact, as was readily apparent at the 2015 DARPA Robotics Challenge, falls and failures are the standard operating mode for state-of-the-art robots in the (somewhat fake) real world.
The robot that finished in third place, CHIMP from Carnegie Mellon University, made use of a relatively safe forward fall and recovery strategy by design. These robots were the result of many months of work by clever professionals working out of some of the world's best robotics labs.
We might call the falls and failures experienced by robots in complex environments "teachable moments." However, there is little to no machine learning in classical robotics control (Boston Dynamics CEO Marc Raibert indicates their robots use no learning at all). Most robots attempting comparatively open-ended tasks like the DARPA challenge also have to fall back on remote (human) operation when things go sideways.
Reinforcement learning (RL) is famously hard as well. RL makes short work of a few basic toy environments and beats human performance at some video and board games, but in more complicated situations RL continues to suffer from combinatorial explosions arising from several sources.
Combined with the challenge of interpreting deep learning models, the combinatorial explosion of complex environments, and its effect on RL training accounts for why machine learning in autonomous automobiles isn't end-to-end. It is largely limited to computer vision tasks (although simplified end-to-end lane-keeping is viable).
You may be tempted to conclude that if robotics control in complex environments is hard and reinforcement learning outside of toy problems is hard, combining the two challenges would be doubly futile. However, OpenAI, and roughly 13,000 years of simulation time, would like to advocate a different perspective, exemplified by single-handedly solving the Rubik's cube puzzle with reinforcement learning.
Enabling generally capable robots has been one of OpenAI's core technical objectives since its first year of operation. If the cortical homunculus is any indication, fine motor control of general-purpose end effectors (aka hands) is a pretty big chunk of what's needed for general intelligence.
As a representative task of general learning for dexterous manipulation, OpenAI chose to focus on manipulating a Rubik's cube from scrambled to solved states and vice-versa. The pre-print publication and demonstration by OpenAI in October 2019 was the culmination of 2 years worth of work. The process incorporated incremental progress and techniques from several core lines of research pursued by the organization.
On the theoretical side of solving a Rubik's cube, Thomas Rokicki and Morley Davidson showed in 2014 that any scramble of a 3x3 Rubik's cube can be solved in 26 moves or less. As for the physical part of the problem, the unofficial record for fastest robot solve is the Rubik's Contraption by Ben Katz and Jared Di Carlo at ~0.38 seconds, slightly better than the record maintained by Guinness achieved by Albert Beer's Sub1 Reloaded (0.637 seconds). And funnily enough, Rubik's Contraption additionally makes a fairly efficient cube destroyer (shown in the video below).
If the Rubik's cube puzzle has essentially been solved computationally, and robots been built that can solve the cube faster than the mechanical limits of the cube itself, why is robotic hand Rubik's cube manipulation still an interesting problem? Most robotics applications are highly specialized for superhuman performance but only excel at one particular task.
These are the kind of robots that build rockets, perform high-throughput biological screening, sort pancakes, and in general fuel much of the fear and uncertainty in human-robot relations. But these special-purpose robots don't come close to the multi-purpose manipulation capabilities of a human hand. Giving a robotic hand the versatile problem-solving that humans pride themselves on requires general-purpose learning algorithms and effector mechanics, and it's the sort of capability we need if robotics is to make a positive impact in our lives outside of tightly controlled environments.
Rubik's Contraption may be able to solve cubes quickly, but you'd hardly want a robot that operates like that to perform care duties for ill loved ones. Robotics need general-purpose flexibility if they are to share living and working spaces with humans and to enable far-flung autonomy in roles that may help humans to explore the universe. Modern robotics up to this point are largely tools, but the future will see robots become tool-users.
Elements of dexterous in-hand puzzle-solving leading up to the current work. This graphic was made in part using a photograph CC BY SA The Shadow Robotics company.
Let's get one thing out of the way: the dexterous in-hand manipulation project undertaken at OpenAI is not about solving the Rubik's cube puzzle in the sense of determining a sequence of movements to match up all the colors on each side. Rather the project focused on executing said movements with a customized version of the Shadow Robotics Hand while using Kociemba's algorithm to determine which moves to attempt.
This was misleadingly cited to be a major point of contention in some reports. Gary Marcus rephrased the point 3 times in a list of 7 criticisms. The use of Kociemba's algorithm is mentioned prominently in both the paper and the blog post by OpenAI, and the same language was used to describe similar work by another group with a 2x2 cube in simulation only. It doesn't seem that the language used was unusual or highly likely to be misunderstood by interested parties. All-in-all, this criticism is not very interesting (which is not to say there aren't legitimate critiques to be made), and in any case, deep reinforcement learning has also been used to tackle the problem of determining which moves to make to solve a scrambled cube.
It's widely accepted in the field of artificial intelligence that tasks requiring a high degree of logical or analytical reasoning (things that humans would generally classify as difficult) are actually much easier for machines whether by following explicit programming or through machine learning. Perception and mobility both remain more challenging. It's a plausible explanation for why Deep Blue managed to beat Gary Kasparov, the best chess player in the world at the time.
Machines still lag far behind humans in many tasks, including dexterous object manipulation, and especially tasks requiring generalization. The idea that perception and mobility are more difficult than reasoning was observed by prominent AI researchers in the 1980s, most notably Hans Moravec, Marvin Minsky, and Rodney Brooks. This is now known as Moravec's paradox.
The manipulation project at OpenAI started in 2017, and the most recent results relied on a number of clever tricks developed both internally by OpenAI and more broadly by the machine and reinforcement learning communities. In July 2018 they succeeded in the intermediate step of teaching a robotic hand to orient a simple block, but to learn the more complex movements needed to rotate the faces of a Rubik's cube they needed to develop a few new tricks.
Reportedly, it took about 13,000 simulated years of training to achieve sim2real transfer to the physical robotic hand, and anyone of the techniques mentioned called out in the graphic could be responsible for 3x or so of training efficiency. For example, in experiments from the paper, manual domain randomization was at least 3x slower than using automatic domain randomization (and setting the level of randomization poorly can make it even worse). With multiple facets affecting training synergistically, it's entirely possible that training could have taken years instead of months had they not been brought together effectively.
We'll focus on two key novel contributions discussed in the paper: automatic domain randomization and embed-and-add observations, but the other tricks and links to the original research are listed in Table 1 below. Finally, we'll discuss perhaps the most interesting result from the project: the emergence of meta-learning. This allowed the control policy to adapt to changing physics (in simulation) and perturbations like gloved manipulation (in the real world).
| Technique | Origin |
|---|---|
| (Automatic) Domain Randomization | Sadeghi et al. 2016, Tobin et al 2017, and (current paper 2019) |
| Embed-and-add observations vector | current paper 2019 |
| Focal loss weighting | Guo et al. 2018 |
| Rapid | OpenAI 2019 |
| LARS optimizer | You et al. 2017 |
| Asymmetric Actor-Critic Architecture | Pinto et al. 2017 |
| Visualization and interpretability | Olah et al. 2018 |
Table 1: non-exhaustive list of techniques incorporated into the cube manipulation project and their origins.
The application of machine learning to robotics has historically been limited by the physical constraints of robotics platforms. Robots tend to be expensive and slow compared to simulation, but unfortunately, training in simulated environments leads to overfitting and poor transfer to the real world. Domain randomization is one way to overcome these problems. Domain randomization has been a crucial part of learning image-based drone navigation and pinpointing blocks (and spam) for grasping.
Effective training in simulation is limited because it is difficult to get all the details to match reality closely. Even with high-fidelity simulations, the parameters will vary somewhat from one robot to the next and over time as physical parts wear out, temperature drifts, etc. To get around this problem while still taking advantage of the massive data availability from simulation training, domain randomization adds noise to the parameters of the simulated environment. These can be visual parameters like texture and color, physical variables like friction and joint hysteresis, or even departures from normal physics like the gravitational constant. In previous work, the level of domain randomization was set via the human guess-and-check method. Getting the level of randomization wrong can lead to
Automatic Domain Randomization, as the name suggests, makes this process adaptive. In each episode simulation, each parameter is sampled from a normal distribution of possible values, but the parameters of the distribution are automatically adjusted as performance increases. This results in training that is about 3 times faster than using manual domain randomization on the Rubik's cube task. The benefits of ADR versus manual DR at a poorly chosen level are much greater. A low level of randomization leads to policies that never transfer skills well, no matter how long they are trained. Set the DR level too high, on the other hand, and training may take forever.
The Rubik's cube manipulation segment of OpenAI's dexterous manipulation involved several months of continuous training, but researchers were constantly tweaking the parameters and conditions experienced by the simulated robots. Sometimes this entailed changing or adding observations available to the policy, which would normally necessitate changing the dimensions of the first layer to compensate, throwing off training significantly. To get around this they used a fixed size latent space in the shape of a 512 element vector, embedding various observations as needed. This strikes me as an interesting way to get around variable input/output dimensions and is worth investigating further.
If we're limited to only one aspect of the paper to take away, it's the emergent meta-learning observed by OpenAI. As discussed above, domain randomization is required for skills learned in simulation to transfer to real-world scenarios and from robot to robot. What is perhaps less obvious, is that using domain randomization (especially the adaptive variant discussed here) not only allows skill transfer but also enables skill adaptation. Presumably, when an agent is faced with environments that are too complex to memorize they learn relational rules instead, allowing the agent to calibrate its policy based on experience acquired during test time. I suspect this concept of "learning to learn" will become increasingly important in real-world AI tasks.
The most impressive results regarding meta-learning in the Rubik's cube manipulation task were shown in simulation: the authors showed that they were able to change the physics of the simulation mid-run and the policy was able to recover. Even a disabled finger joint did not stop the policy from adapting. Although manipulation efficiency after breaking a finger didn't recover to whole-handed levels, it was comparable to a broken-finger baseline. In the real world, the effect of meta-learning is translated to solving the task under a variety of perturbations. Some of the challenges (such as poking with a plush giraffe) may seem silly, but the implication is that a control policy learned in this way should be able to cope with mechanical drift and degradation as well as variable environments.
Earlier we mentioned that there were far more interesting critiques of OpenAI's paper than the fact that they used Kociemba's algorithm for planning. That's the premise of this section.
The performance wasn't that good, and they only reported a small number of trials on the physical robot. In physical tests, OpenAI only reports ten attempts each at completing a sequence of moves to solve a full or partial scramble. In the former case, only 2 of the 10 sequences were completed successfully without dropping, while the latter finished 6 times without fail. These results aren't great, but in light of the failure modes, they are pretty good.
Dropping the cube doesn't seem like it should be such a terminal event: learning to pick up the cube wouldn't be harder than learning to manipulate the cube (though it would entail hardware changes) and humans in competition regularly use the table surface as an assist during one-handed solves. The limited number of attempts is much more questionable, as 10 attempts under each condition are far too few to get a good idea of how capable the policy is. Another issue is that the physical solves were typically attempted in reverse (starting from unscrambled to scrambled) and followed a static sequence of moves, decreasing variety. I would have much rather seen the results include a variety of move sequences carried out over many more trials.
They almost managed to solve visual perception for the task but had to fall back on a Giiker cube with embedded position sensing. Part of the objective of this project was to use three RGB cameras and a set of vision networks to estimate cube pose and state. Unfortunately relying solely on vision dropped manipulation performance by more than half and the success rate on the partially scrambled solve task from 60% to 20% (the full scramble was not solvable using the vision model alone). It's unfortunate that solving vision and manipulation simultaneously proved to be too much. On the other hand, they did continue to use the vision models for inferring pose in all their physical tests, which is pretty dang good.
Proprioception, or sensing of the robotic hand position, would have made the manipulation feats that much more impressive. Instead, they used a very fancy motion tracking system from PhaseSpace that used LEDs blinking with encoded identification patterns as motion capture tags. The need for sophisticated point motion tracking be in large part due to limitations of the robotic hand instrumentation itself, but the gloved robotic hand manipulations would have been much more impressive had they managed it with the fingertips covered as well.
The hype cycle surrounding each new robotics breakthrough always seems to involve some cultivation of fear. This is often exaggerated to the point of parody (e.g. referencing our "our new robot overlords"), but the root of robot-related anxiety stems from the uncertainty and risk associated with a rapidly changing world. Robotics has and will continue to change the way we live and work.
It might not always be easy to adapt, but the flexible capabilities of human intelligence are not likely to become entirely obsolete any time soon. In case there is any doubt about remaining human relevance (at least for deftly solving Rubik's cubes) I'd like to sign off with the following performance by competitive cuber Feliks Zemdegs

{kind=link}