HPC
Digging Deep Into AMD’s New Radeon Instinct GPUs and the MIOpen GPU-Accelerated Library
December 22, 2016
8 min read

.jpg?format=webp)
At AMD's recent AMD Tech Summit, they announced the new Radeon Instinct Initiative, their latest hardware and software package designed specifically for high-performance machine learning. A trio of Radeon Instinct add-in cards were unveiled under AMD's strategy to accelerate the machine intelligence era in server computing. AMD also announced MIOpen, a free, open-source library for GPU accelerators intended to enable high-performance machine intelligence implementations and is said to be tuned to exploit the abilites of the new Instinct line. Through a new suite of hardware and open-source offerings designed to dramatically increase performance, efficiency, and ease of implementation for deep learning workloads, AMD anticipates to provide an effective ecosystem for the future of machine intelligence.

AMD revealed three Radeon Instinct accelerators, slated for 2017 release, designed to address a wide-range of machine intelligence applications:
A variety of open source solutions are fueling Radeon Instinct hardware:
"Radeon Instinct is set to dramatically advance the pace of machine intelligence through an approach built on high-performance GPU accelerators, and free, open-source software in MIOpen and ROCm," said AMD President and CEO, Dr. Lisa Su. "With the combination of our high-performance compute and graphics capabilities and the strength of our multi-generational roadmap, we are the only company with the GPU and x86 silicon expertise to address the broad needs of the datacenter and help advance the proliferation of machine intelligence."
AMD's new software library, MIOpen, is specifically catered towards the Instinct line of GPUs. AMD has revealed initial MIOpen benchmark results generated by Baidu Research's DeepBench tool. The DeepBench Tool tests training performance using 32-bit floating-point arithmetic and while AMD is only reporting one of the test's operations (GEMM), readers should be aware that the results are strategically chosen and display early benchmarking data for the hardware.

AMD used the GeForce GTX Titan X Maxwell as its baseline for performance and compared it to the NVIDIA Titan X Pascal, Instinct MI8, and Instinct MI25. The Titan X Maxwell reached a peak FP32 rate of 6.14 TFLOPS as a base frequency. The Titan X Pascal reached up to 10.2 TFLOPS mainly due to a significantly higher GPU clock rate. Utilizing the MIOpen library, AMD displayed the Radeon Instinct MI8 with 8.2 TFLOPS, beating the Titan X Maxwell by 33%. Meanwhile, the MI25 shows to be 50% faster than NVIDIA's Titan X Pascal and 90% faster than its Maxwell counterpart. Based on the minimal information available for the new Vega technology mixed precision handling, we can only speculate that the MI25 has an FP32 rate around 12 TFLOPS.

AMD's MIOpen library is just one part of their software strategy. It lays above the open-source ROCm platform's support for HCC, HIP, OpenCL, and Python. ROCm also supports NCCL, a library of collective communication routines for multi-GPU topologies, including all the significant math libraries (BLAS, FFT, and RNG) and the C++ standard template library. The ROCm platform seems to be AMD's answer to NVIDIA's CUDA as it aims to assist developers in coding compute-oriented software for AMD GPUs.

AMD also introduced a handful of system integrators at their summit to showcase their server configuration plans for their cards. A Supermicro SuperServer 1028GQ-TFT 1U chassis was featured using 4x MI25 GPUs resulting in100 TFLOPS of FP16 performance. Inventec featured their K888 2U server configuration using 4x MI25 cards providing 100 TFLOPS of compute performance and their Falconwitch PS1816 4U chassis featuring 16x MI25 modules, yielding up to 400 TFLOPS of compute performance.

When fully populating a 42U server rack with six Falconwitch 4U servers and six K888 2U servers, compute performance presumably reached up to 3 petaflops by utilizing a total of 120x MI25 GPUs. AMD's Senior Vice President and Chief Architect, Raja Koduri, claimed "And the whole rack will cost less than a single DGX-1 server." Assuming this to be true, we are talking about twelve servers, RAM, and 120x MI25 GPUs for around the $129,000 price range. While the potential compute performance, hardware, and software by AMD sound exciting, it is still too early to tell how well it will all perform in the machine learning field.
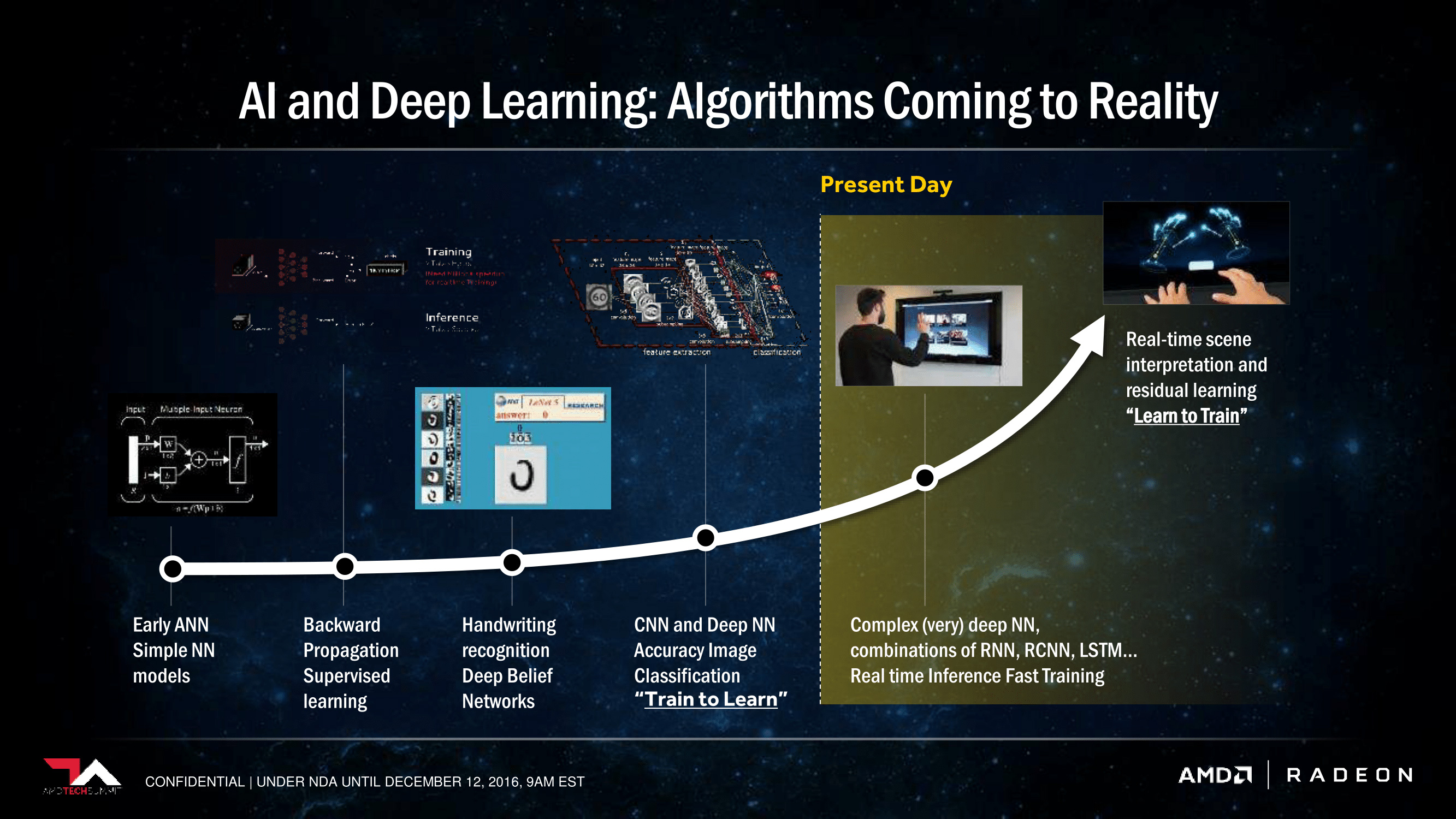
Currently, the market for deep learning is still young and we are only scratching the surface of what neural networks are capable of. As the software around it matures, users will be able to efficiently apply neural networks to analyze large amounts of data to capitalize on a wide variety of benefits. Whether it be video speech recognition or photo facial/object recognition, deep learning software and GPUs have recently made great strides in creating neural networks density powerful enough to achieve meaningful work. The major advancements in GPU technology have even been gaining notice from industry juggernauts, including Google and Amazon. These technology leaders have started to research and make use of deep learning technologies while smaller players are finding other creative ways to utilize neural networks.
AMD is clearly looking to dive into this space with their introduction of the Radeon Instinct initiative and are looking to take on rival NVIDIA, a competitor already heavily vested in the market with their premier Tesla P100 card at the forefront. The good news is the HPC market is vast and the deep learning market is rather new. AMD has laid out a solid groundwork with the improved Radeon Open Compute Platform and Instinct GPUs, so they still have the ability to capture an extensive portion of the market within the coming years.

At AMD's recent AMD Tech Summit, they announced the new Radeon Instinct Initiative, their latest hardware and software package designed specifically for high-performance machine learning. A trio of Radeon Instinct add-in cards were unveiled under AMD's strategy to accelerate the machine intelligence era in server computing. AMD also announced MIOpen, a free, open-source library for GPU accelerators intended to enable high-performance machine intelligence implementations and is said to be tuned to exploit the abilites of the new Instinct line. Through a new suite of hardware and open-source offerings designed to dramatically increase performance, efficiency, and ease of implementation for deep learning workloads, AMD anticipates to provide an effective ecosystem for the future of machine intelligence.
AMD revealed three Radeon Instinct accelerators, slated for 2017 release, designed to address a wide-range of machine intelligence applications:
A variety of open source solutions are fueling Radeon Instinct hardware:
"Radeon Instinct is set to dramatically advance the pace of machine intelligence through an approach built on high-performance GPU accelerators, and free, open-source software in MIOpen and ROCm," said AMD President and CEO, Dr. Lisa Su. "With the combination of our high-performance compute and graphics capabilities and the strength of our multi-generational roadmap, we are the only company with the GPU and x86 silicon expertise to address the broad needs of the datacenter and help advance the proliferation of machine intelligence."
AMD's new software library, MIOpen, is specifically catered towards the Instinct line of GPUs. AMD has revealed initial MIOpen benchmark results generated by Baidu Research's DeepBench tool. The DeepBench Tool tests training performance using 32-bit floating-point arithmetic and while AMD is only reporting one of the test's operations (GEMM), readers should be aware that the results are strategically chosen and display early benchmarking data for the hardware.
AMD used the GeForce GTX Titan X Maxwell as its baseline for performance and compared it to the NVIDIA Titan X Pascal, Instinct MI8, and Instinct MI25. The Titan X Maxwell reached a peak FP32 rate of 6.14 TFLOPS as a base frequency. The Titan X Pascal reached up to 10.2 TFLOPS mainly due to a significantly higher GPU clock rate. Utilizing the MIOpen library, AMD displayed the Radeon Instinct MI8 with 8.2 TFLOPS, beating the Titan X Maxwell by 33%. Meanwhile, the MI25 shows to be 50% faster than NVIDIA's Titan X Pascal and 90% faster than its Maxwell counterpart. Based on the minimal information available for the new Vega technology mixed precision handling, we can only speculate that the MI25 has an FP32 rate around 12 TFLOPS.
AMD's MIOpen library is just one part of their software strategy. It lays above the open-source ROCm platform's support for HCC, HIP, OpenCL, and Python. ROCm also supports NCCL, a library of collective communication routines for multi-GPU topologies, including all the significant math libraries (BLAS, FFT, and RNG) and the C++ standard template library. The ROCm platform seems to be AMD's answer to NVIDIA's CUDA as it aims to assist developers in coding compute-oriented software for AMD GPUs.
AMD also introduced a handful of system integrators at their summit to showcase their server configuration plans for their cards. A Supermicro SuperServer 1028GQ-TFT 1U chassis was featured using 4x MI25 GPUs resulting in100 TFLOPS of FP16 performance. Inventec featured their K888 2U server configuration using 4x MI25 cards providing 100 TFLOPS of compute performance and their Falconwitch PS1816 4U chassis featuring 16x MI25 modules, yielding up to 400 TFLOPS of compute performance.
When fully populating a 42U server rack with six Falconwitch 4U servers and six K888 2U servers, compute performance presumably reached up to 3 petaflops by utilizing a total of 120x MI25 GPUs. AMD's Senior Vice President and Chief Architect, Raja Koduri, claimed "And the whole rack will cost less than a single DGX-1 server." Assuming this to be true, we are talking about twelve servers, RAM, and 120x MI25 GPUs for around the $129,000 price range. While the potential compute performance, hardware, and software by AMD sound exciting, it is still too early to tell how well it will all perform in the machine learning field.
Currently, the market for deep learning is still young and we are only scratching the surface of what neural networks are capable of. As the software around it matures, users will be able to efficiently apply neural networks to analyze large amounts of data to capitalize on a wide variety of benefits. Whether it be video speech recognition or photo facial/object recognition, deep learning software and GPUs have recently made great strides in creating neural networks density powerful enough to achieve meaningful work. The major advancements in GPU technology have even been gaining notice from industry juggernauts, including Google and Amazon. These technology leaders have started to research and make use of deep learning technologies while smaller players are finding other creative ways to utilize neural networks.
AMD is clearly looking to dive into this space with their introduction of the Radeon Instinct initiative and are looking to take on rival NVIDIA, a competitor already heavily vested in the market with their premier Tesla P100 card at the forefront. The good news is the HPC market is vast and the deep learning market is rather new. AMD has laid out a solid groundwork with the improved Radeon Open Compute Platform and Instinct GPUs, so they still have the ability to capture an extensive portion of the market within the coming years.



