News
NVIDIA GTC March 2022 Keynote Highlights
March 22, 2022
17 min read


Keeping with tradition, Jensen Huang once again delivered an innovative vision of the future of AI at the GTC Keynote, along with a number of new announcements on the NVIDIA products and services that will get us there.
Kicking off NVIDIA’s GTC conference, Huang introduced new silicon, including the new Hopper GPU architecture and new H100 GPU, new AI and accelerated computing software and powerful new data-center-scale systems.
We captured some of the main highlights from the keynote below.
Omniverse was once again at the top of the keynote. NVIDIA began with a spectacular flythrough of their new campus, rendered in Omniverse, including labs working on advanced robotics projects.
Jensen shared how the company’s work with the broader ecosystem is saving lives by advancing healthcare and drug discovery, and even helping save our planet as their model for Earth-2 continues to improve with regional climate change simulations that can now predict atmospheric river conditions well in advance.
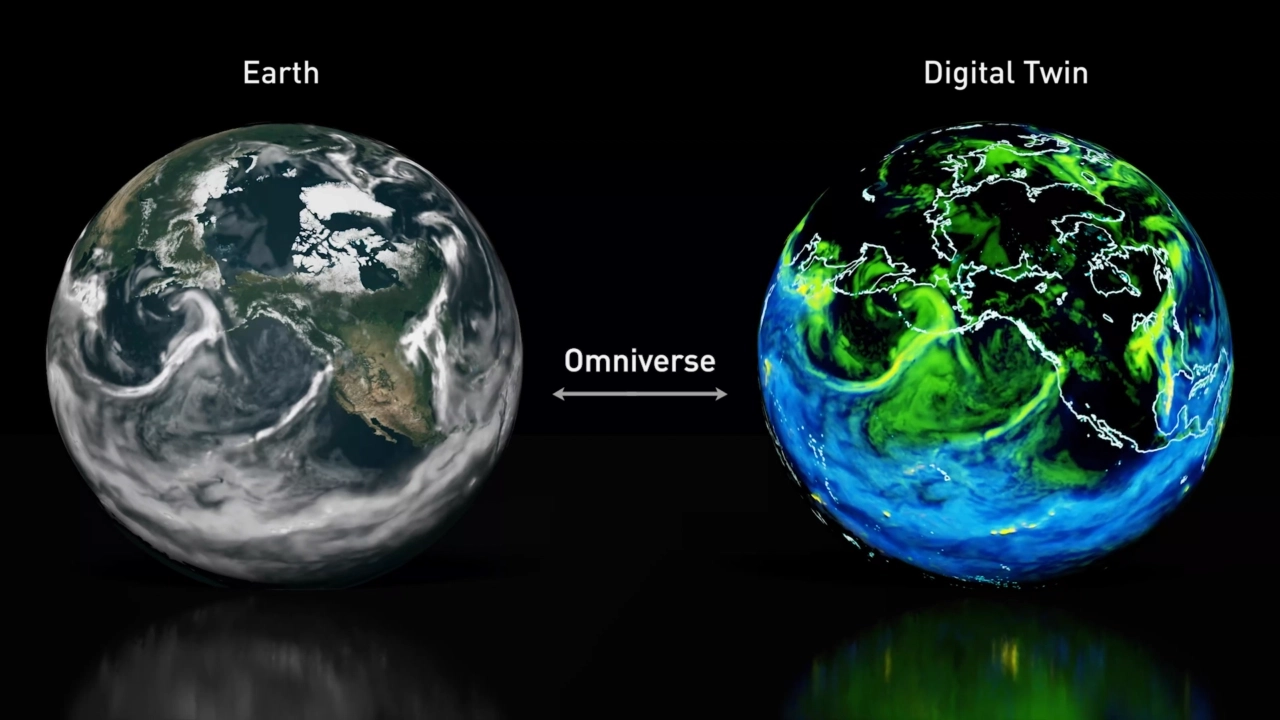
NVIDIA is also working on new data-center-scale NVIDIA OVX systems, will be integral for "action-oriented AI."
OVX will run Omniverse digital twins for large-scale simulations with multiple autonomous systems operating in the same space-time. The backbone of OVX is its networking fabric: NVIDIA Spectrum-4 high-performance data networking infrastructure platform. The world’s first 400Gbps end-to-end networking platform, NVIDIA Spectrum-4 consists of the Spectrum-4 switch family, NVIDIA ConnectX-7 SmartNIC, NVIDIA BlueField-3 DPU and NVIDIA DOCA data center infrastructure software.
Jensen Huang introduced the NVIDIA H100 built on the Hopper architecture, as the "new engine of the world's AI infrastructures."
AI applications like speech, conversation, customer service and recommenders are driving fundamental changes in data center design. AI data centers work 24/7 and process mountains of continuous data to train and refine AI models. Companies are manufacturing intelligence and operating giant AI factories built on massive amounts of data, and the new H100 is meant to help these factories move faster.
The H100 is a massive 80 billion transistor chip using TSMC's 4N process. It is the biggest generational leap ever with 9x at-scale training performance over A100 and 30x large-language-model inference throughput. It is now in production and should be ready by Q3 2022.

So, let's take a quick look at the Hopper architecture.
The NVIDIA Hopper GPU architecture unveiled today at GTC will accelerate dynamic programming — a problem-solving technique used in algorithms for genomics, quantum computing, route optimization and more — by up to 40x with new DPX instructions.
An instruction set built into NVIDIA H100 GPUs, DPX will help developers write code to achieve speedups on dynamic programming algorithms in multiple industries, boosting workflows for disease diagnosis, quantum simulation, graph analytics and routing optimizations.

What Is Dynamic Programming?
Developed in the 1950s, dynamic programming is a popular technique for solving complex problems with two key techniques: recursion and memoization.
Recursion involves breaking a problem down into simpler sub-problems, saving time and computational effort. In memoization, the answers to these sub-problems — which are reused several times when solving the main problem — are stored. Memoization increases efficiency, so sub-problems don’t need to be recomputed when needed later on in the main problem.
DPX instructions accelerate dynamic programming algorithms by up to 7x on an NVIDIA H100 GPU, compared with NVIDIA Ampere architecture-based GPUs. In a node with four NVIDIA H100 GPUs, that acceleration can be boosted even further.
Dynamic programming algorithms are used in healthcare, robotics, quantum computing, data science and more.
Jensen also announced new Hopper GPU-based AI supercomputers — DGX H100, H100 DGX POD and DGX SuperPOD.
To connect it all, NVIDIA’s new NVLink high-speed interconnect technology will be coming to all future NVIDIA chips — CPUs, GPUs, DPUs and SOCs.
He also announced NVIDIA will make NVLink available to customers and partners to build companion chips.
Remote work and hybrid workplaces are the new normal for professionals in many industries. Teams spread throughout the world are expected to create and collaborate while maintaining top productivity and performance.
Businesses use the NVIDIA RTX platform to enable their workers to keep up with the most demanding workloads, from anywhere. And today, NVIDIA is expanding its RTX offerings with seven new NVIDIA Ampere architecture GPUs for laptops and desktops.
The new NVIDIA RTX A500, RTX A1000, RTX A2000 8GB, RTX A3000 12GB, RTX A4500 and RTX A5500 laptop GPUs expand access to AI and ray-tracing technology, delivering breakthrough performance no matter where you work. The laptops include the latest RTX and Max-Q technology, giving professionals the ability to take their workflows to the next level.

NVIDIA also introduced its first discrete data center CPU for high-performance computing.
The Grace CPU Superchip comprises two CPU chips connected over a 900 gigabytes per second NVLink chip-to-chip interconnect to make a 144-core CPU with 1 terabyte per second of memory bandwidth. It doubles the performance and energy-efficiency of server chips.

Created to provide the highest performance, Grace CPU Superchip packs 144 Arm cores in a single socket, offering industry-leading estimated performance of 740 on the SPECrate®2017_int_base benchmark. This is more than 1.5x higher compared to the dual-CPU shipping with the DGX™ A100 today, as estimated in NVIDIA’s labs with the same class of compilers.
Grace CPU Superchip also provides industry-leading energy efficiency and memory bandwidth with its innovative memory subsystem consisting of LPDDR5x memory with Error Correction Code for the best balance of speed and power consumption. The LPDDR5x memory subsystem offers double the bandwidth of traditional DDR5 designs at 1 terabyte per second while consuming dramatically less power with the entire CPU including the memory consuming just 500 watts.
The Grace CPU Superchip is based on the latest data center architecture, Arm®v9. Combining the highest single-threaded core performance with support for Arm’s new generation of vector extensions, the Grace CPU Superchip will bring immediate benefits to many applications.
The Grace CPU Superchip will run all of NVIDIA’s computing software stacks, including NVIDIA RTX™, NVIDIA HPC, NVIDIA AI and Omniverse. The Grace CPU Superchip along with NVIDIA ConnectX®-7 NICs offer the flexibility to be configured into servers as standalone CPU-only systems or as GPU-accelerated servers with one, two, four or eight Hopper-based GPUs, allowing customers to optimize performance for their specific workloads while maintaining a single software stack.
Designed for AI, HPC, Cloud and Hyperscale Applications
The Grace CPU Superchip will excel at the most demanding HPC, AI, data analytics, scientific computing and hyperscale computing applications with its highest performance, memory bandwidth, energy efficiency and configurability.
The Grace CPU Superchip’s 144 cores and 1TB/s of memory bandwidth will provide unprecedented performance for CPU-based high performance computing applications. HPC applications are compute-intensive, demanding the highest performing cores, highest memory bandwidth and the right memory capacity per core to speed outcomes.
NVIDIA is working with leading HPC, supercomputing, hyperscale and cloud customers for the Grace CPU Superchip. Both it and the Grace Hopper Superchip are expected to be available in the first half of 2023.
NVIDIA also unveiled more than 60 updates to its CUDA-X™ collection of libraries, tools and technologies across a broad range of disciplines, which dramatically improve performance of the CUDA® software computing platform.
Dozens of updates are available today, reinforcing CUDA’s position as the industry’s most comprehensive platform for developers to build accelerated applications to address challenges across high performance computing fields such as research in 6G, quantum computing, genomics, drug discovery and logistics optimization, as well as advanced work in robotics, cybersecurity, data analytics and more.
These updates make the NVIDIA systems that developers already use across science, AI and data processing even faster. Highlights include:
Among other libraries being updated are MONAI, for medical imaging; NVIDIA FLARE™, for federated learning, with nearly 300,000 downloads; Maxine, for reinventing communications; Riva, for speech AI; Merlin, for recommender systems; and Isaac™, for robotics.
During the Keynote, Jensen announced DRIVE Hyperion 9: the next generation of the open platform for automated and autonomous vehicles. The programmable architecture, slated for 2026 production vehicles, is built on multiple DRIVE Atlan computers to achieve intelligent driving and in-cabin functionality.
DRIVE Hyperion is designed to be compatible across generations, with the same computer form factor and NVIDIA DriveWorks APIs. Partners can leverage current investments in the DRIVE Orin platform and seamlessly migrate to NVIDIA DRIVE Atlan and beyond.
The platform includes the computer architecture, sensor set and full NVIDIA DRIVE Chauffeur and Concierge applications. It is designed to be open and modular, so customers can select what they need. Current-generation systems scale from NCAP to level 3 driving and level 4 parking with advanced AI cockpit capabilities.
Heightened Sensing
With DRIVE Atlan’s compute performance, DRIVE Hyperion 9 can process even more sensor data as the car drives, improving redundancy and diversity.
This upgraded sensor suite includes surround imaging radar, enhanced cameras with higher frame rates, two additional side lidar and improved undercarriage sensing with better camera and ultrasonic placement.
In total, the DRIVE Hyperion 9 architecture includes 14 cameras, nine radars, three lidars and 20 ultrasonics for automated and autonomous driving, as well as three cameras and one radar for interior occupant sensing.
By incorporating a rich sensor set and high-performance compute, the entire system is architected to the highest levels of functional safety and cybersecurity.
DRIVE Hyperion 9 will begin production in 2026, giving the industry continuous access to the cutting edge in AI technology as it begins to roll out more intelligent transportation.
To help robots navigate indoor spaces, like factories and warehouses, NVIDIA announced Isaac Nova Orin, built on Jetson AGX Orin, a state-of-the-art compute and sensor reference platform to accelerate autonomous mobile robot development and deployment.
Nova Orin comes with all of the compute and sensor hardware needed to design, build and test autonomy in AMRs.
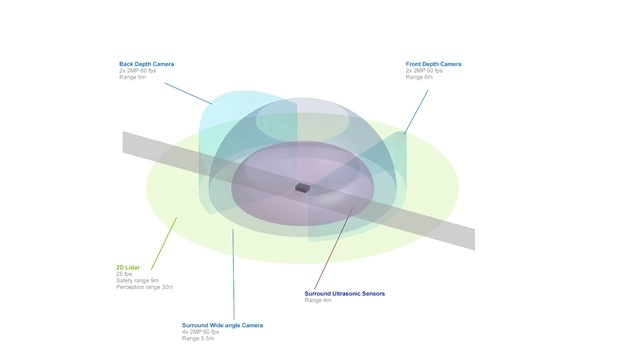
Its two Jetson AGX Orin units provide up to 550 TOPS of AI compute for perception, navigation and human-machine interaction. These modules process data in real time from the AMR’s central nervous system — essentially the sensor suite comprising up to six cameras, three lidars and eight ultrasonic sensors.
Nova Orin includes tools necessary to simulate the robot in Isaac Sim on Omniverse, as well as support for numerous ROS software modules designed to accelerate perception and navigation tasks. Tools are also provided for accurately mapping the robots’ environment using NVIDIA DeepMap.
The entire platform is calibrated and tested to work out of the box and give developers valuable time to innovate on new features and capabilities.
Jensen ended his Keynote by tying all the technologies, product announcements and demos back into a vision of how NVIDIA will drive forward the next generation of computing.
NVIDIA announced new products across its four-layer stack: hardware, system software and libraries, software platforms NVIDIA HPC, NVIDIA AI, and NVIDIA Omniverse; and AI and robotics application frameworks.

He also went through the five dynamics shaping the industry: million-X computing speedups, transformers turbocharging AI, data centers becoming AI factories, which is exponentially increasing demand for robotics systems, and digital twins for the next era of AI.
There were many other announcements throughout the Keynote, so make sure to watch the full video below.
Click here to watch every announcement during the full NVIDIA keynote for GTC's March 2022 event.
Have questions about how to get started with NVIDIA, or upgrading your current infrastructure?
Contact Exxact today
Keeping with tradition, Jensen Huang once again delivered an innovative vision of the future of AI at the GTC Keynote, along with a number of new announcements on the NVIDIA products and services that will get us there.
Kicking off NVIDIA’s GTC conference, Huang introduced new silicon, including the new Hopper GPU architecture and new H100 GPU, new AI and accelerated computing software and powerful new data-center-scale systems.
We captured some of the main highlights from the keynote below.
Omniverse was once again at the top of the keynote. NVIDIA began with a spectacular flythrough of their new campus, rendered in Omniverse, including labs working on advanced robotics projects.
Jensen shared how the company’s work with the broader ecosystem is saving lives by advancing healthcare and drug discovery, and even helping save our planet as their model for Earth-2 continues to improve with regional climate change simulations that can now predict atmospheric river conditions well in advance.
NVIDIA is also working on new data-center-scale NVIDIA OVX systems, will be integral for "action-oriented AI."
OVX will run Omniverse digital twins for large-scale simulations with multiple autonomous systems operating in the same space-time. The backbone of OVX is its networking fabric: NVIDIA Spectrum-4 high-performance data networking infrastructure platform. The world’s first 400Gbps end-to-end networking platform, NVIDIA Spectrum-4 consists of the Spectrum-4 switch family, NVIDIA ConnectX-7 SmartNIC, NVIDIA BlueField-3 DPU and NVIDIA DOCA data center infrastructure software.
Jensen Huang introduced the NVIDIA H100 built on the Hopper architecture, as the "new engine of the world's AI infrastructures."
AI applications like speech, conversation, customer service and recommenders are driving fundamental changes in data center design. AI data centers work 24/7 and process mountains of continuous data to train and refine AI models. Companies are manufacturing intelligence and operating giant AI factories built on massive amounts of data, and the new H100 is meant to help these factories move faster.
The H100 is a massive 80 billion transistor chip using TSMC's 4N process. It is the biggest generational leap ever with 9x at-scale training performance over A100 and 30x large-language-model inference throughput. It is now in production and should be ready by Q3 2022.
So, let's take a quick look at the Hopper architecture.
The NVIDIA Hopper GPU architecture unveiled today at GTC will accelerate dynamic programming — a problem-solving technique used in algorithms for genomics, quantum computing, route optimization and more — by up to 40x with new DPX instructions.
An instruction set built into NVIDIA H100 GPUs, DPX will help developers write code to achieve speedups on dynamic programming algorithms in multiple industries, boosting workflows for disease diagnosis, quantum simulation, graph analytics and routing optimizations.
What Is Dynamic Programming?
Developed in the 1950s, dynamic programming is a popular technique for solving complex problems with two key techniques: recursion and memoization.
Recursion involves breaking a problem down into simpler sub-problems, saving time and computational effort. In memoization, the answers to these sub-problems — which are reused several times when solving the main problem — are stored. Memoization increases efficiency, so sub-problems don’t need to be recomputed when needed later on in the main problem.
DPX instructions accelerate dynamic programming algorithms by up to 7x on an NVIDIA H100 GPU, compared with NVIDIA Ampere architecture-based GPUs. In a node with four NVIDIA H100 GPUs, that acceleration can be boosted even further.
Dynamic programming algorithms are used in healthcare, robotics, quantum computing, data science and more.
Jensen also announced new Hopper GPU-based AI supercomputers — DGX H100, H100 DGX POD and DGX SuperPOD.
To connect it all, NVIDIA’s new NVLink high-speed interconnect technology will be coming to all future NVIDIA chips — CPUs, GPUs, DPUs and SOCs.
He also announced NVIDIA will make NVLink available to customers and partners to build companion chips.
Remote work and hybrid workplaces are the new normal for professionals in many industries. Teams spread throughout the world are expected to create and collaborate while maintaining top productivity and performance.
Businesses use the NVIDIA RTX platform to enable their workers to keep up with the most demanding workloads, from anywhere. And today, NVIDIA is expanding its RTX offerings with seven new NVIDIA Ampere architecture GPUs for laptops and desktops.
The new NVIDIA RTX A500, RTX A1000, RTX A2000 8GB, RTX A3000 12GB, RTX A4500 and RTX A5500 laptop GPUs expand access to AI and ray-tracing technology, delivering breakthrough performance no matter where you work. The laptops include the latest RTX and Max-Q technology, giving professionals the ability to take their workflows to the next level.
NVIDIA also introduced its first discrete data center CPU for high-performance computing.
The Grace CPU Superchip comprises two CPU chips connected over a 900 gigabytes per second NVLink chip-to-chip interconnect to make a 144-core CPU with 1 terabyte per second of memory bandwidth. It doubles the performance and energy-efficiency of server chips.
Created to provide the highest performance, Grace CPU Superchip packs 144 Arm cores in a single socket, offering industry-leading estimated performance of 740 on the SPECrate®2017_int_base benchmark. This is more than 1.5x higher compared to the dual-CPU shipping with the DGX™ A100 today, as estimated in NVIDIA’s labs with the same class of compilers.
Grace CPU Superchip also provides industry-leading energy efficiency and memory bandwidth with its innovative memory subsystem consisting of LPDDR5x memory with Error Correction Code for the best balance of speed and power consumption. The LPDDR5x memory subsystem offers double the bandwidth of traditional DDR5 designs at 1 terabyte per second while consuming dramatically less power with the entire CPU including the memory consuming just 500 watts.
The Grace CPU Superchip is based on the latest data center architecture, Arm®v9. Combining the highest single-threaded core performance with support for Arm’s new generation of vector extensions, the Grace CPU Superchip will bring immediate benefits to many applications.
The Grace CPU Superchip will run all of NVIDIA’s computing software stacks, including NVIDIA RTX™, NVIDIA HPC, NVIDIA AI and Omniverse. The Grace CPU Superchip along with NVIDIA ConnectX®-7 NICs offer the flexibility to be configured into servers as standalone CPU-only systems or as GPU-accelerated servers with one, two, four or eight Hopper-based GPUs, allowing customers to optimize performance for their specific workloads while maintaining a single software stack.
Designed for AI, HPC, Cloud and Hyperscale Applications
The Grace CPU Superchip will excel at the most demanding HPC, AI, data analytics, scientific computing and hyperscale computing applications with its highest performance, memory bandwidth, energy efficiency and configurability.
The Grace CPU Superchip’s 144 cores and 1TB/s of memory bandwidth will provide unprecedented performance for CPU-based high performance computing applications. HPC applications are compute-intensive, demanding the highest performing cores, highest memory bandwidth and the right memory capacity per core to speed outcomes.
NVIDIA is working with leading HPC, supercomputing, hyperscale and cloud customers for the Grace CPU Superchip. Both it and the Grace Hopper Superchip are expected to be available in the first half of 2023.
NVIDIA also unveiled more than 60 updates to its CUDA-X™ collection of libraries, tools and technologies across a broad range of disciplines, which dramatically improve performance of the CUDA® software computing platform.
Dozens of updates are available today, reinforcing CUDA’s position as the industry’s most comprehensive platform for developers to build accelerated applications to address challenges across high performance computing fields such as research in 6G, quantum computing, genomics, drug discovery and logistics optimization, as well as advanced work in robotics, cybersecurity, data analytics and more.
These updates make the NVIDIA systems that developers already use across science, AI and data processing even faster. Highlights include:
Among other libraries being updated are MONAI, for medical imaging; NVIDIA FLARE™, for federated learning, with nearly 300,000 downloads; Maxine, for reinventing communications; Riva, for speech AI; Merlin, for recommender systems; and Isaac™, for robotics.
During the Keynote, Jensen announced DRIVE Hyperion 9: the next generation of the open platform for automated and autonomous vehicles. The programmable architecture, slated for 2026 production vehicles, is built on multiple DRIVE Atlan computers to achieve intelligent driving and in-cabin functionality.
DRIVE Hyperion is designed to be compatible across generations, with the same computer form factor and NVIDIA DriveWorks APIs. Partners can leverage current investments in the DRIVE Orin platform and seamlessly migrate to NVIDIA DRIVE Atlan and beyond.
The platform includes the computer architecture, sensor set and full NVIDIA DRIVE Chauffeur and Concierge applications. It is designed to be open and modular, so customers can select what they need. Current-generation systems scale from NCAP to level 3 driving and level 4 parking with advanced AI cockpit capabilities.
Heightened Sensing
With DRIVE Atlan’s compute performance, DRIVE Hyperion 9 can process even more sensor data as the car drives, improving redundancy and diversity.
This upgraded sensor suite includes surround imaging radar, enhanced cameras with higher frame rates, two additional side lidar and improved undercarriage sensing with better camera and ultrasonic placement.
In total, the DRIVE Hyperion 9 architecture includes 14 cameras, nine radars, three lidars and 20 ultrasonics for automated and autonomous driving, as well as three cameras and one radar for interior occupant sensing.
By incorporating a rich sensor set and high-performance compute, the entire system is architected to the highest levels of functional safety and cybersecurity.
DRIVE Hyperion 9 will begin production in 2026, giving the industry continuous access to the cutting edge in AI technology as it begins to roll out more intelligent transportation.
To help robots navigate indoor spaces, like factories and warehouses, NVIDIA announced Isaac Nova Orin, built on Jetson AGX Orin, a state-of-the-art compute and sensor reference platform to accelerate autonomous mobile robot development and deployment.
Nova Orin comes with all of the compute and sensor hardware needed to design, build and test autonomy in AMRs.
Its two Jetson AGX Orin units provide up to 550 TOPS of AI compute for perception, navigation and human-machine interaction. These modules process data in real time from the AMR’s central nervous system — essentially the sensor suite comprising up to six cameras, three lidars and eight ultrasonic sensors.
Nova Orin includes tools necessary to simulate the robot in Isaac Sim on Omniverse, as well as support for numerous ROS software modules designed to accelerate perception and navigation tasks. Tools are also provided for accurately mapping the robots’ environment using NVIDIA DeepMap.
The entire platform is calibrated and tested to work out of the box and give developers valuable time to innovate on new features and capabilities.
Jensen ended his Keynote by tying all the technologies, product announcements and demos back into a vision of how NVIDIA will drive forward the next generation of computing.
NVIDIA announced new products across its four-layer stack: hardware, system software and libraries, software platforms NVIDIA HPC, NVIDIA AI, and NVIDIA Omniverse; and AI and robotics application frameworks.
He also went through the five dynamics shaping the industry: million-X computing speedups, transformers turbocharging AI, data centers becoming AI factories, which is exponentially increasing demand for robotics systems, and digital twins for the next era of AI.
There were many other announcements throughout the Keynote, so make sure to watch the full video below.
Click here to watch every announcement during the full NVIDIA keynote for GTC's March 2022 event.
Have questions about how to get started with NVIDIA, or upgrading your current infrastructure?
Contact Exxact today



