Deep Learning
Access Open Source LLMs Anywhere - Mobile LLMs with Ollama
April 24, 2024
12 min read


As artificial intelligence continues to advance, the accessibility of powerful tools to harness this technology becomes increasingly crucial for developers, researchers, and tech enthusiasts alike.
Large Language Models (LLMs) like ChatGPT, Gemini, and open-source alternatives such as Llama and Mistral, have revolutionized our interaction with machine learning. These models serve as the backbone for a wide range of applications, from simple chatbots to sophisticated decision-making systems. Managing these powerful tools, however, often requires considerable expertise, posing a significant challenge for many users.
We will guide you through how to access these open-source models remotely, highlighting the use of Ollama for managing your models, and the Ollama Web UI for an enhanced interactive experience as well as how you can employ ngrok to remote access the local environment we created for our Ollama model.
Ollama is a user-friendly platform that simplifies the management and operation of LLMs, making cutting-edge AI accessible even to those with only a modest technical background. Designed to simplify the management and deployment of LLMs, Ollama acts not just as a tool, but as a bridge to a broader understanding of AI’s potential. Whether you're working with advanced proprietary models or exploring the possibilities of accessible open-source models, Ollama provides a user-friendly platform to harness the capabilities of these transformative technologies.
Ngrok is a powerful reverse proxy tool that facilitates secure and reliable remote access to local server setups. We will use ngrok to create a tunnel to your Ollama environment, allowing you to manage and interact with your LLM from any location.
Ngrok is crucial for developers who want to access their models on the go without needing to carry the compute everywhere. It provides a stable and secure connection to your AI tools regardless of physical location.
We will focus primarily on two models: Llama 3: 70b those with robust computational resources, and Mistral 7B, perfect for beginners or those with limited resources. Whether you are a seasoned developer or a curious novice, this guide will walk you through setting up, running, and optimizing LLMs using Ollama and ngrok for remote access.
Here are links to:
https://ollama.com/library/llama3
https://ollama.com/library/mixtral
https://ollama.com/library/mistral
Getting started with Ollama is straightforward, especially if you're using a Linux environment. Below, we detail the steps for Linux users and provide resources for those on other platforms.
1. Download and Install: Begin by opening your terminal and entering the following command. This script automates the installation of GitHuba, ensuring a smooth setup process:
curl -fsSL https://ollama.com/install.sh | sh
This command retrieves the installation script directly from Ollama's website and runs it, setting up Ollama on your Linux system and preparing you for the exciting journey ahead.
2. Launch the Web UI: Once Ollama is installed, you can start the web-based user interface using Docker, which facilitates running Ollama in an isolated environment:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
This command runs the Ollama Web UI in a Docker container, mapping the container's port 8080 to port 3000 on your host machine. The --restart always option ensures that the Docker container restarts automatically if it crashes or if you reboot your system. Review Ollama’s Github for WebUI here.
For those using macOS, Windows, or who prefer a Docker-based installation even on Linux, Ollama supports several other installation methods including an installation exe file on the Ollama download site or refer to the official Ollama GitHub repository for detailed instructions tailored to each platform. This repository includes comprehensive guides and troubleshooting tips to help you set up Ollama on a variety of environments.
The Ollama Web UI is a key feature that provides a simple, intuitive interface, allowing you to interact seamlessly with your Large Language Models (LLMs). Designed for user-friendliness, the Web UI makes managing LLMs accessible to users of all technical levels, from beginners to advanced practitioners.
To begin exploring the capabilities of Ollama, open your web browser and navigate to: http://localhost:3000
This address will direct you to the login page of the Ollama Web UI, hosted locally on your machine.
Upon reaching the login page, you will need to create an account. Since this environment is local, all user data remains securely stored within your Docker container. Feel free to use any preferred username, email, and password as this information does not need to be tied to any external accounts:
Once logged in, the main interface will be displayed, where you can select an LLM to interact with. The user-friendly dashboard allows you to easily start conversations and explore different functionalities of each model.
If you wish to expand your selection of models:
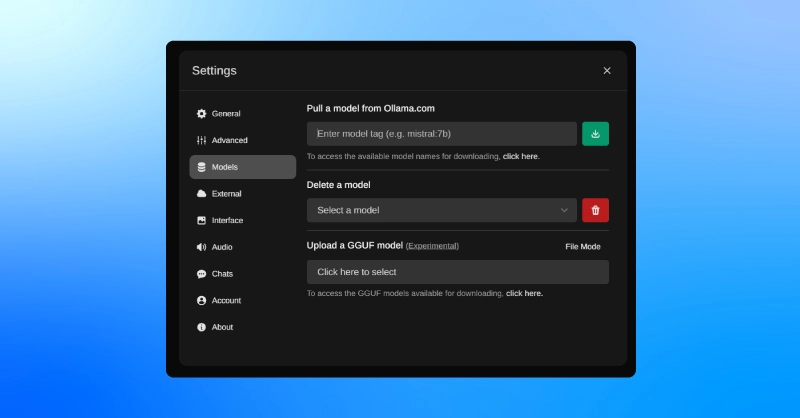
The Ollama Web UI is designed to provide a robust yet straightforward environment for working with and learning about LLMs, enhancing your experience and making it easier to manage these complex models effectively.
When it comes to selecting the right Large Language Model, the decision largely depends on your specific needs and resources. Here are some considerations to keep in mind when choosing from Ollama's library:

With the latest CPUs and most powerful GPUs available, accelerate your deep learning and AI project optimized to your deployment, budget, and desired performance!
Configure NowLet’s consider a scenario where you want to interact with your LLM about a general topic. Here’s a simple way to do this:
This use case demonstrates a basic yet effective way to engage with an LLM using Ollama. Whether you are simply exploring AI capabilities or seeking specific information, the simplicity of Ollama’s interface allows for quick adjustments and interactive learning. Feel free to experiment with different questions and settings to discover the full potential of your LLM.
Providing remote access to your LLM setup can greatly enhance its usability, especially if you want to manage or interact with your model from different locations or devices. Ngrok is an invaluable tool for this purpose, as it creates a secure tunnel to your local server.
Here’s a detailed guide on how to set it up:
1. Install ngrok:
2. Authenticate ngrok:
ngrok config add-authtoken [Your_Auth_Token]
3. Connect to Ollama:
ngrok http http://localhost:3000
By following these steps, you can set up ngrok to provide secure and convenient remote access to your Ollama Web UI, greatly enhancing the flexibility and accessibility of your LLM management.
While ngrok is a powerful tool for remote access, it also introduces some security considerations that you must address:
By adhering to these best practices, you can minimize risks and ensure that your use of Ollama and ngrok remains secure and private.
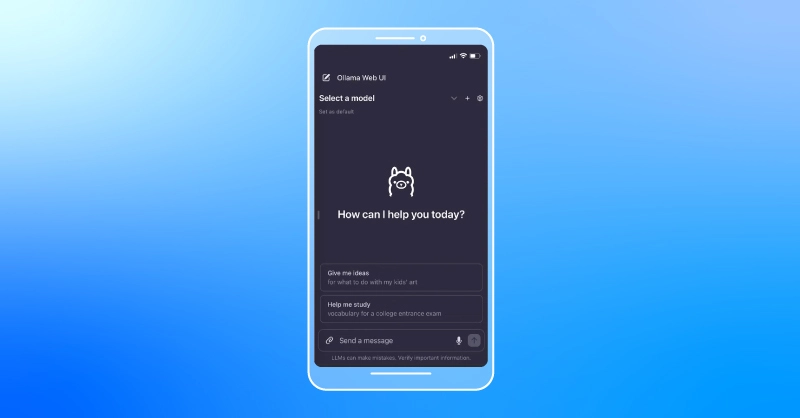
The ultimate convenience comes when you can interact with your LLM setups directly from your mobile device. Following the ngrok setup outlined previously, accessing your Ollama instance on mobile is straightforward. Here’s how to do it:
This capability not only increases the flexibility of where and how you can work with LLMs but also ensures you can demonstrate or share your projects with others more conveniently, whether in meetings, classrooms, or casual discussions.
Congratulations on beginning your journey with Large Language Models through Ollama! We encourage you to explore the ever-evolving capabilities of open-source projects like Ollama, Mistral, and Lama. These platforms not only push the boundaries of what's possible in generative AI but also make cutting-edge technology more accessible. As the state of the art continues to advance, it opens the door for more people to engage with and benefit from these powerful tools.
The ability to run these models on a local GPU-equipped PC is not just empowering—it's transformative. It gives you complete control over the tools, allowing for a deeper understanding and customization of the technology. As advancements in AI continue, models are becoming smaller and more efficient, promising a future where anyone can use high-level AI tools right from their own home.
At Exxact, we provide the essential hardware to make this future a reality today. Configure your very own deep learning workstation, server, or even a full rack to fuel your AI development. With our powerful, ready-to-deploy systems, you have everything you need to start training, developing, and deploying your own LLMs. Dive into the world of AI with Exxact, where we deliver the compute and storage to unleash your creativity.
With access to the highest performing hardware, at Exxact, we can offer the platform optimized for your deployment, budget, and desired performance so you can make an impact with your research!
Talk to an Engineer TodayAs artificial intelligence continues to advance, the accessibility of powerful tools to harness this technology becomes increasingly crucial for developers, researchers, and tech enthusiasts alike.
Large Language Models (LLMs) like ChatGPT, Gemini, and open-source alternatives such as Llama and Mistral, have revolutionized our interaction with machine learning. These models serve as the backbone for a wide range of applications, from simple chatbots to sophisticated decision-making systems. Managing these powerful tools, however, often requires considerable expertise, posing a significant challenge for many users.
We will guide you through how to access these open-source models remotely, highlighting the use of Ollama for managing your models, and the Ollama Web UI for an enhanced interactive experience as well as how you can employ ngrok to remote access the local environment we created for our Ollama model.
Ollama is a user-friendly platform that simplifies the management and operation of LLMs, making cutting-edge AI accessible even to those with only a modest technical background. Designed to simplify the management and deployment of LLMs, Ollama acts not just as a tool, but as a bridge to a broader understanding of AI’s potential. Whether you're working with advanced proprietary models or exploring the possibilities of accessible open-source models, Ollama provides a user-friendly platform to harness the capabilities of these transformative technologies.
Ngrok is a powerful reverse proxy tool that facilitates secure and reliable remote access to local server setups. We will use ngrok to create a tunnel to your Ollama environment, allowing you to manage and interact with your LLM from any location.
Ngrok is crucial for developers who want to access their models on the go without needing to carry the compute everywhere. It provides a stable and secure connection to your AI tools regardless of physical location.
We will focus primarily on two models: Llama 3: 70b those with robust computational resources, and Mistral 7B, perfect for beginners or those with limited resources. Whether you are a seasoned developer or a curious novice, this guide will walk you through setting up, running, and optimizing LLMs using Ollama and ngrok for remote access.
Here are links to:
https://ollama.com/library/llama3
https://ollama.com/library/mixtral
https://ollama.com/library/mistral
Getting started with Ollama is straightforward, especially if you're using a Linux environment. Below, we detail the steps for Linux users and provide resources for those on other platforms.
1. Download and Install: Begin by opening your terminal and entering the following command. This script automates the installation of GitHuba, ensuring a smooth setup process:
curl -fsSL https://ollama.com/install.sh | sh
This command retrieves the installation script directly from Ollama's website and runs it, setting up Ollama on your Linux system and preparing you for the exciting journey ahead.
2. Launch the Web UI: Once Ollama is installed, you can start the web-based user interface using Docker, which facilitates running Ollama in an isolated environment:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
This command runs the Ollama Web UI in a Docker container, mapping the container's port 8080 to port 3000 on your host machine. The --restart always option ensures that the Docker container restarts automatically if it crashes or if you reboot your system. Review Ollama’s Github for WebUI here.
For those using macOS, Windows, or who prefer a Docker-based installation even on Linux, Ollama supports several other installation methods including an installation exe file on the Ollama download site or refer to the official Ollama GitHub repository for detailed instructions tailored to each platform. This repository includes comprehensive guides and troubleshooting tips to help you set up Ollama on a variety of environments.
The Ollama Web UI is a key feature that provides a simple, intuitive interface, allowing you to interact seamlessly with your Large Language Models (LLMs). Designed for user-friendliness, the Web UI makes managing LLMs accessible to users of all technical levels, from beginners to advanced practitioners.
To begin exploring the capabilities of Ollama, open your web browser and navigate to: http://localhost:3000
This address will direct you to the login page of the Ollama Web UI, hosted locally on your machine.
Upon reaching the login page, you will need to create an account. Since this environment is local, all user data remains securely stored within your Docker container. Feel free to use any preferred username, email, and password as this information does not need to be tied to any external accounts:
Once logged in, the main interface will be displayed, where you can select an LLM to interact with. The user-friendly dashboard allows you to easily start conversations and explore different functionalities of each model.
If you wish to expand your selection of models:
The Ollama Web UI is designed to provide a robust yet straightforward environment for working with and learning about LLMs, enhancing your experience and making it easier to manage these complex models effectively.
When it comes to selecting the right Large Language Model, the decision largely depends on your specific needs and resources. Here are some considerations to keep in mind when choosing from Ollama's library:
With the latest CPUs and most powerful GPUs available, accelerate your deep learning and AI project optimized to your deployment, budget, and desired performance!
Configure NowLet’s consider a scenario where you want to interact with your LLM about a general topic. Here’s a simple way to do this:
This use case demonstrates a basic yet effective way to engage with an LLM using Ollama. Whether you are simply exploring AI capabilities or seeking specific information, the simplicity of Ollama’s interface allows for quick adjustments and interactive learning. Feel free to experiment with different questions and settings to discover the full potential of your LLM.
Providing remote access to your LLM setup can greatly enhance its usability, especially if you want to manage or interact with your model from different locations or devices. Ngrok is an invaluable tool for this purpose, as it creates a secure tunnel to your local server.
Here’s a detailed guide on how to set it up:
1. Install ngrok:
2. Authenticate ngrok:
ngrok config add-authtoken [Your_Auth_Token]
3. Connect to Ollama:
ngrok http http://localhost:3000
By following these steps, you can set up ngrok to provide secure and convenient remote access to your Ollama Web UI, greatly enhancing the flexibility and accessibility of your LLM management.
While ngrok is a powerful tool for remote access, it also introduces some security considerations that you must address:
By adhering to these best practices, you can minimize risks and ensure that your use of Ollama and ngrok remains secure and private.
The ultimate convenience comes when you can interact with your LLM setups directly from your mobile device. Following the ngrok setup outlined previously, accessing your Ollama instance on mobile is straightforward. Here’s how to do it:
This capability not only increases the flexibility of where and how you can work with LLMs but also ensures you can demonstrate or share your projects with others more conveniently, whether in meetings, classrooms, or casual discussions.
Congratulations on beginning your journey with Large Language Models through Ollama! We encourage you to explore the ever-evolving capabilities of open-source projects like Ollama, Mistral, and Lama. These platforms not only push the boundaries of what's possible in generative AI but also make cutting-edge technology more accessible. As the state of the art continues to advance, it opens the door for more people to engage with and benefit from these powerful tools.
The ability to run these models on a local GPU-equipped PC is not just empowering—it's transformative. It gives you complete control over the tools, allowing for a deeper understanding and customization of the technology. As advancements in AI continue, models are becoming smaller and more efficient, promising a future where anyone can use high-level AI tools right from their own home.
At Exxact, we provide the essential hardware to make this future a reality today. Configure your very own deep learning workstation, server, or even a full rack to fuel your AI development. With our powerful, ready-to-deploy systems, you have everything you need to start training, developing, and deploying your own LLMs. Dive into the world of AI with Exxact, where we deliver the compute and storage to unleash your creativity.
With access to the highest performing hardware, at Exxact, we can offer the platform optimized for your deployment, budget, and desired performance so you can make an impact with your research!
Talk to an Engineer Today


