Deep Learning
Disentangling AI, Machine Learning, and Deep Learning
April 5, 2021
17 min read


First, a little context...
Deep learning is a subset of machine learning, which in turn is a subset of artificial intelligence, but the origins of these names arose from an interesting history. In addition, there are fascinating technical characteristics that can differentiate deep learning from other types of machine learning...essential working knowledge for anyone with ML, DL, or AI in their skillset.
If you are looking to improve your skill set or steer business/research strategy in 2021, you may come across articles decrying a skills shortage in deep learning. A few years ago, you would have read the same about a shortage of professionals with machine learning skills, and just a few years before that the emphasis would have been on a shortage of data scientists skilled in “big data.”
Likewise, we’ve heard Andrew Ng telling us for years that “AI is the new electricity”, and the advent of AI in business and society is constantly suggested to have an impact similar to that of the industrial revolution. While warnings of skills shortages are arguably overblown, why do we seem to change our ideas about what skills are most in-demand faster than those roles can be filled in the first place?
More broadly, and with the benefit of 20/20 hindsight, why does AI research have so many different names and guises over the years?
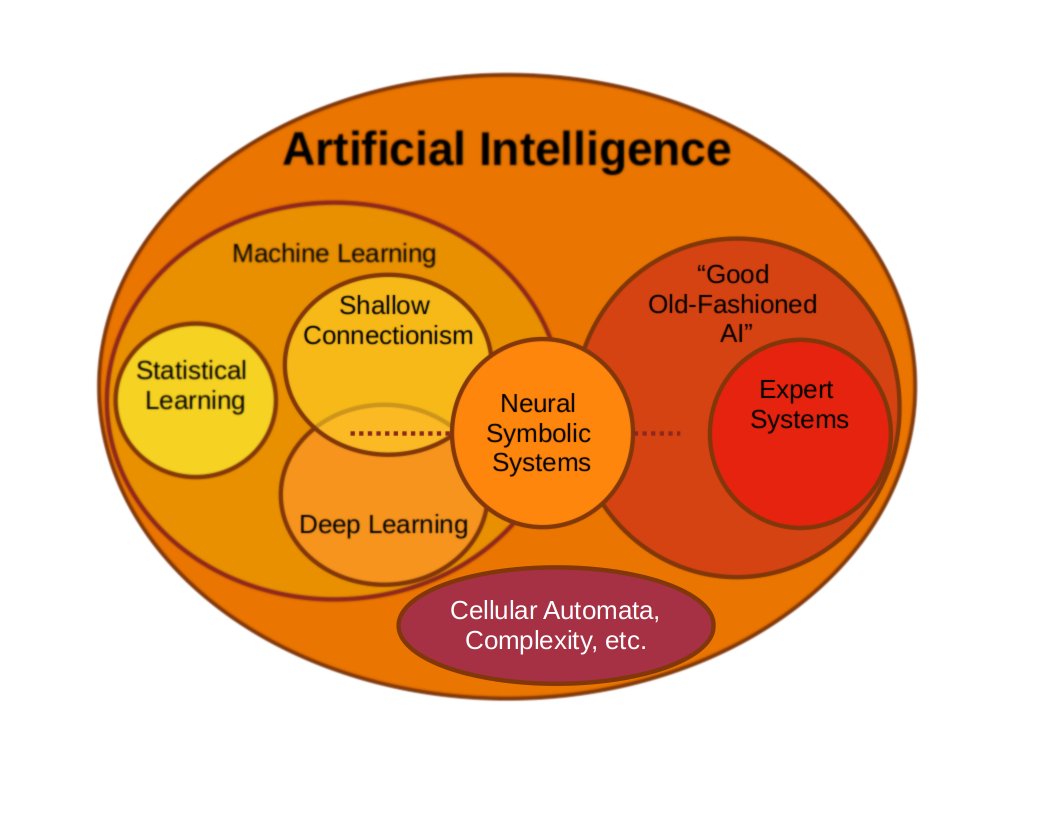
Cartoon overview of the various sub-fields within artificial intelligence. Image by the author.
Searching jobs site Indeed.com for “deep learning” yields about 49,000 hits as of this writing. That’s a bit funny, because deep learning is a subset of machine learning, which in turn is a field within artificial intelligence, and searches for ML and AI yielded ~40,000 and ~39,000 jobs, respectively.
If deep learning is a part of AI, why are there ~20% fewer jobs open for the latter? The answer is that the terms we use for these fields often have as much to do with trends and marketability as they do with any substantive differences. That’s not to say that we can’t differentiate the different categories based on technical characteristics, we’ll do that too!
In fact, there are several very interesting emergent characteristics separating deep learning from “classical” machine learning including shallow neural networks and statistical learning. Before we talk about those, let’s take a walk through the history of AI, where we’ll see that much of the popularity of various AI terms has to do with generating high expectations before later falling short and eventually re-branding to re-establish credibility when new ideas lead to new solutions to old problems.
Interested in an AI workstation that can handle machine learning and deep learning research?
View AI workstations starting at $3,700
Image of AI Pioneer and coiner of the term Artificial Intelligence. Modified from original CC BY SA Wikipedia/flickr user null0.
The Dartmouth workshop was an extended summer conference of a small number of prominent mathematicians and scientists in 1956.
The workshop is widely considered to be the founding of artificial intelligence as a field, and it brought together many different disciplines known under a variety of names (each with their own conceptual underpinnings) under the umbrella of AI. Before John McCarthy proposed the meeting in 1955, the idea of thinking machines was pursued under the disparate approaches of automata theory and cybernetics, among others. In attendance were such well known names as Claude Shannon, John Nash, and Marvin Minsky among a few others. The Dartmouth workshop not only tied together several independent threads of research pertaining to intelligent machines, it set ambitious expectations for the next decade of research.
Those ambitions, as it turned out, would ultimately end with disappointment and the first AI winter— a term used to describe the lulls in the waxing and waning fortunes of the AI hype cycle.
In 1973, Professor Sir James Lighthill of the UK wrote “Artificial Intelligence: A General Survey,” also known as the Lighthill Report. In his report, Lighthill describes three categories of AI research: A, B, and C. While he describes some missed expectations in categories A and C (advanced automation and computational neuroscience), Lighthill describes the field as falling short most noticeably in the very visible category B, aka robots. The Lighthill report, along with a treatise demonstrating some shortcomings of an early form of shallow neural network, Perceptrons by Marvin Minsky and Seymour Paypert, are to this day considered to be major harbingers of the AI winter that took hold in the 1970s.
“Students of all this work have generally concluded that it is unrealistic to expect highly generalized systems that can handle a large knowledge base effectively in a learning or self-organizing mode to be developed in the 20th century.” - James Lighthill, Artificial Intelligence: A General Survey
It wasn’t long before interest returned to AI and, in the 1980s, funding also began to creep back into the field. Although the field of neural networks and perceptrons had fallen distinctly out of favor the first time around (with many blaming Minsky and Paypert), this time they would play a major role. Perhaps in an effort to distance themselves from earlier disappointments, neural networks would re-enter legitimate research under the guise of a new moniker: connectionism.
In fact, many of the most recognizable names in the modern era of deep learning such as Jürgen Schmidhuber, Yann LeCun, Yoshua Bengio, and Geoffrey Hinton were doing foundational work on topics like backpropagation and the vanishing gradient problem in the 1980s and early 1990s. But the real headliner of AI research in the 1980s was the field of expert systems. Unlike the “grandiose claims” critiqued by Lighthill in his report, expert systems were actually providing quantifiable commercial benefits, such as XCON developed at Carnegie Mellon University.
XCON was an expert system that reportedly saved the Digital Equipment Corporation up to $40 million per year. With utility demonstrated by systems like XCON and several high-profile game-playing systems, funding returned to AI in both commercial R&D labs and government programs. It wouldn’t last, however.
The combinatorial explosion, in which the complexity of real world scenarios becomes intractable to enumerate, remained an unsolved challenge. Expert systems in particular were too brittle to deal with changing information, and updating them was expensive. Convincing and capable robots, again, were nowhere to be seen.
Roboticists such as Rodney Brooks and Hans Moravec began to emphasize that the manual work of painstakingly trying to distill human expert knowledge into computer programs was not sufficient to solve the most basic of human skills, such as navigating a busy sidewalk or locating a friend in a noisy crowd. It soon became apparent under what we now know as Moravec’s paradox that for AI, the easy things are hard while the hard things like calculating a large sum or playing expert checkers, are comparatively easy.
Expert systems were proving to be brittle and costly, setting the stage for disappointment, but at the same time learning-based AI was rising to prominence, and many researchers began to flock to this area. Their focus on machine learning included neural networks, as well as a wide variety of other algorithms and models like support vector machines, clustering algorithms, and regression models.
The turning over of the 1980s into the 1990s is regarded by some as the second AI winter, and indeed hundreds of AI companies and divisions shut down during this time. Many of these companies were engaged in building what was at the time high-performance computing (HPC), and their closing down was indicative of the important role Moore's law would play in AI progress.
Deep Blue, the chess champion system developed by IBM in the later 1990s, wasn’t powered by a better expert system, but rather a compute-enabled alpha-beta search. Why pay a premium for a specialized Lisp machine when you can get the same performance from a consumer desktop?
Although Moore’s law has essentially slowed to a crawl as transistors reach physical limits, engineering improvements continue to enable new breakthroughs in modern AI, with NVIDIA and AMD leading the way. And now, a turnkey AI workstation designed specifically with components that best support modern deep learning models can make a huge difference in iteration speed over what would have been state-of-the-art hardware just a few years ago.
In research and practical applications, however, the early 1990s were really more of a slow simmering. This was a time when future Turing award winners were doing seminal work, and neural networks would soon be used in the real-world application of optical character recognition used for tasks like sorting mail. LSTMs made headway against the vanishing gradient problem in 1997, and meaningful research continued to be done in neural networks and other machine learning methods.
The term machine learning continued to gain in popularity, again perhaps as an effort by serious researchers to distance themselves from over-ambitious claims (and science fiction stigma) associated with the term artificial intelligence. Steady progress and improved hardware continued to power useful AI advances into the new millennium, but it wasn’t until the adoption of highly parallel graphics processing units (GPUs) for the naturally parallelizable mathematical primitives of neural networks that we entered the modern era of deep learning.
When thinking about the beginning of the deep learning era of AI, many of us will point to the success of Alex Krizhevsky et al. and their GPU-trained model at the 2012 ImageNet Large Scale Visual Recognition Challenge. While the so-called AlexNet was modest in size by today’s standards, it decisively bested a competitive field of diverse approaches.
Succeeding winners of the challenge were built on similar principles of convolutional neural networks from then on, and it’s no surprise that many of the characteristics of convolutional networks and the kernel weights learned during training have analogues in animal vision systems.
AlexNet wasn’t a particularly deep convolutional neural network, stretching across 8 layers from tip to tail and only 3 layers deeper than LeNet-5, a convolutional network described more than 2 decades earlier. Instead, the major contribution of AlexNet was the demonstration that training on GPUs was both feasible and well worth it.
In a direct lineage from the development of AlexNet, we now have GPUs specifically engineered to support faster and more efficient training of deep neural networks.
The 2012 ILSVRC and performance of AlexNet in the competition was so iconic that it has become the archetype for AI breakthroughs of the last decade.
For better or worse, people talk about “ImageNet moments” for natural language processing, robotics, and gait analysis, to name a few. We’ve come a long way since then, with deep learning models demonstrating near-human performance or better in playing games, generating convincing text, and other categories that fall under the types of “easy is hard” tasks referred to under Moravec’s paradox mentioned earlier.
Deep learning has also contributed to basic scientific research, and in 2020 made an unequivocal contribution to the fundamental challenge in biology of protein structure prediction.
Hardware acceleration has made training deep and wide neural networks feasible, but that doesn’t explain why or even how larger models produce better results than smaller models. Geoffrey Hinton, widely credited as one of the progenitors of the modern deep learning era, suggested in his Neural Networks for Machine Learning MOOC that machine learning with neural networks becomes deep learning at 7 layers.
We don’t think that’s a bad rule of thumb for approximating the start of the deep learning paradigm, but we think we can draw the line more meaningfully by considering how deep learning models train differently than other forms of machine learning. It’s also worth noting that while deep learning most often refers to models made up of multiple layers of fully connected or convolutional neural layers, the term also encompasses models like neural ordinary differential equations or neural cellular automata.
It’s the computational complexity and depth of operations that make deep learning, and the layers don’t necessarily need to be made up of artificial neurons.
A subset of machine learning which hasn’t been mentioned yet in this article but which remains an important area of expertise for millions of data and basic research scientists is statistical learning.
One of the most important concepts in statistical learning and machine learning in general with smaller models and datasets is that of the bias-variance tradeoff. Bias corresponds to underfitting the training data, and is often a symptom of models that don’t have the fitting power to represent patterns in the dataset.
Variance, on the other hand, corresponds to models that are fitted too well to the training data so much so that generalization to held-out validation data is poor. Synonymous terminology that’s a little easier to keep in mind is under/over-fitting.
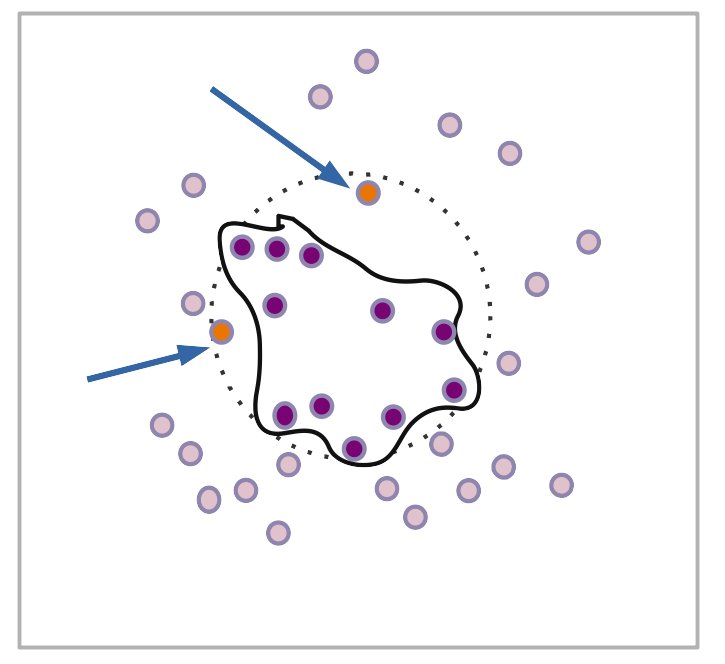
Cartoon example of overfitting in a simple classification problem. The dark purple spots represent the training data, which the black decision boundary has been overfitted to. The lighter purple dots have been correctly excluded outside the decision boundary, but two orange spots not in the training set (see arrows) have been misclassified as belonging to the out-group. The dotted line in the background represents the true classification boundary. Image by the author.
For statistical models and shallow neural networks, we can generally interpret under-fitting as a symptom of a model being too small, and overfitting a symptom of too large of a model. Of course there are numerous different strategies to regularize models so that they exhibit better generalization, but we’ll leave that discussion mostly for another time.
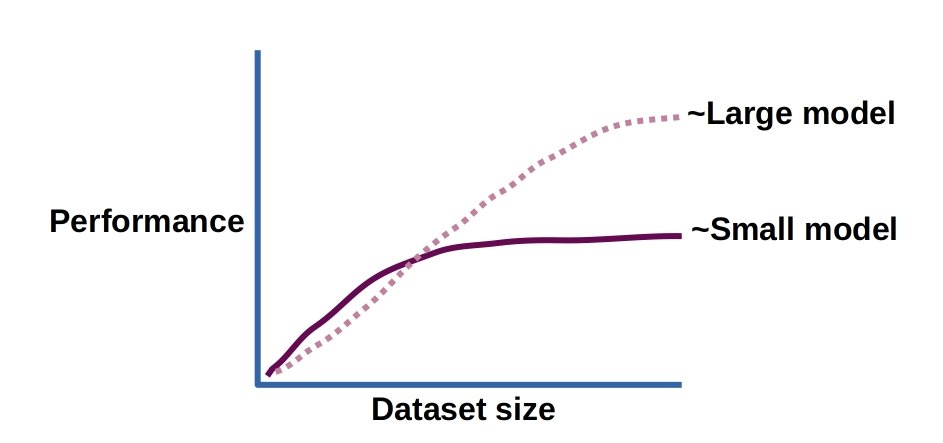
Larger models also tend to be better capable of taking advantage of larger datasets.
Cartoon representation of the ability of larger models to take advantage of larger datasets. Image by the author.
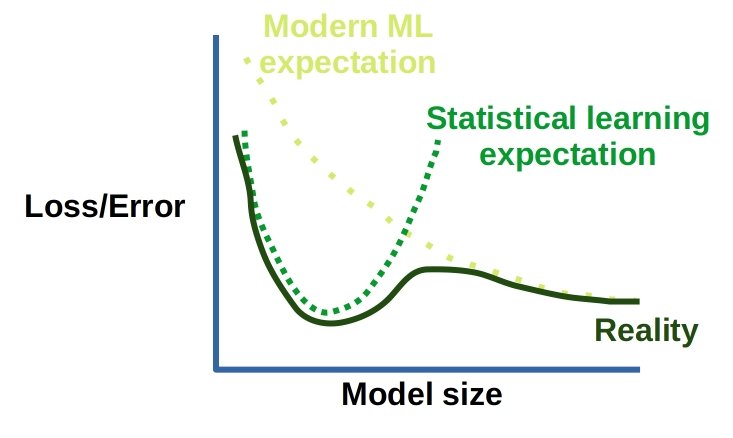
Overfitting is often seen in the difference between model performance on the training and validation datasets, and this deviation can get worse with more training/bigger models. However, an interesting phenomenon occurs when both the model and the dataset gets even larger. This fascinating emergent property of deep double descent refers to an initial period of improved performance, followed by decreasing performance due to overfitting, but finally superseded by even better performance. This occurs with increasing model depth, width, or training data, and might be most logical place to draw the distinguishing line between deep learning and shallower neural networks.
Cartoon representation of deep double descent. Image by the author.
Somewhat counter-intuitively, in the deep learning regime marked by deep double descent, models actually tend to generalize better and regularization techniques like dropout tend to yield better results. Other hallmarks of deep learning, like the lottery ticket hypothesis, are likely related.
This concludes our discussion of the history and rationale of a few sub-fields of AI, and what they’ve been called at different points in their history.
We also discussed an interesting identifying characteristic of deep learning models that allows them to continue to improve with increasing scale or data when we would intuitively expect them to massively overfit. Of course, if you are pitching a project to investors/managers/funders, or pitching yourself to a potential employer, you may want to consider your terminology from a marketing perspective instead.
In that case you may want to describe your work to the public as AI, to investors as deep learning, and to your colleagues and peers at conferences as machine learning.
Have any questions?
Contact Exxact Today
First, a little context...
Deep learning is a subset of machine learning, which in turn is a subset of artificial intelligence, but the origins of these names arose from an interesting history. In addition, there are fascinating technical characteristics that can differentiate deep learning from other types of machine learning...essential working knowledge for anyone with ML, DL, or AI in their skillset.
If you are looking to improve your skill set or steer business/research strategy in 2021, you may come across articles decrying a skills shortage in deep learning. A few years ago, you would have read the same about a shortage of professionals with machine learning skills, and just a few years before that the emphasis would have been on a shortage of data scientists skilled in “big data.”
Likewise, we’ve heard Andrew Ng telling us for years that “AI is the new electricity”, and the advent of AI in business and society is constantly suggested to have an impact similar to that of the industrial revolution. While warnings of skills shortages are arguably overblown, why do we seem to change our ideas about what skills are most in-demand faster than those roles can be filled in the first place?
More broadly, and with the benefit of 20/20 hindsight, why does AI research have so many different names and guises over the years?
Cartoon overview of the various sub-fields within artificial intelligence. Image by the author.
Searching jobs site Indeed.com for “deep learning” yields about 49,000 hits as of this writing. That’s a bit funny, because deep learning is a subset of machine learning, which in turn is a field within artificial intelligence, and searches for ML and AI yielded ~40,000 and ~39,000 jobs, respectively.
If deep learning is a part of AI, why are there ~20% fewer jobs open for the latter? The answer is that the terms we use for these fields often have as much to do with trends and marketability as they do with any substantive differences. That’s not to say that we can’t differentiate the different categories based on technical characteristics, we’ll do that too!
In fact, there are several very interesting emergent characteristics separating deep learning from “classical” machine learning including shallow neural networks and statistical learning. Before we talk about those, let’s take a walk through the history of AI, where we’ll see that much of the popularity of various AI terms has to do with generating high expectations before later falling short and eventually re-branding to re-establish credibility when new ideas lead to new solutions to old problems.
Interested in an AI workstation that can handle machine learning and deep learning research?
View AI workstations starting at $3,700
Image of AI Pioneer and coiner of the term Artificial Intelligence. Modified from original CC BY SA Wikipedia/flickr user null0.
The Dartmouth workshop was an extended summer conference of a small number of prominent mathematicians and scientists in 1956.
The workshop is widely considered to be the founding of artificial intelligence as a field, and it brought together many different disciplines known under a variety of names (each with their own conceptual underpinnings) under the umbrella of AI. Before John McCarthy proposed the meeting in 1955, the idea of thinking machines was pursued under the disparate approaches of automata theory and cybernetics, among others. In attendance were such well known names as Claude Shannon, John Nash, and Marvin Minsky among a few others. The Dartmouth workshop not only tied together several independent threads of research pertaining to intelligent machines, it set ambitious expectations for the next decade of research.
Those ambitions, as it turned out, would ultimately end with disappointment and the first AI winter— a term used to describe the lulls in the waxing and waning fortunes of the AI hype cycle.
In 1973, Professor Sir James Lighthill of the UK wrote “Artificial Intelligence: A General Survey,” also known as the Lighthill Report. In his report, Lighthill describes three categories of AI research: A, B, and C. While he describes some missed expectations in categories A and C (advanced automation and computational neuroscience), Lighthill describes the field as falling short most noticeably in the very visible category B, aka robots. The Lighthill report, along with a treatise demonstrating some shortcomings of an early form of shallow neural network, Perceptrons by Marvin Minsky and Seymour Paypert, are to this day considered to be major harbingers of the AI winter that took hold in the 1970s.
“Students of all this work have generally concluded that it is unrealistic to expect highly generalized systems that can handle a large knowledge base effectively in a learning or self-organizing mode to be developed in the 20th century.” - James Lighthill, Artificial Intelligence: A General Survey
It wasn’t long before interest returned to AI and, in the 1980s, funding also began to creep back into the field. Although the field of neural networks and perceptrons had fallen distinctly out of favor the first time around (with many blaming Minsky and Paypert), this time they would play a major role. Perhaps in an effort to distance themselves from earlier disappointments, neural networks would re-enter legitimate research under the guise of a new moniker: connectionism.
In fact, many of the most recognizable names in the modern era of deep learning such as Jürgen Schmidhuber, Yann LeCun, Yoshua Bengio, and Geoffrey Hinton were doing foundational work on topics like backpropagation and the vanishing gradient problem in the 1980s and early 1990s. But the real headliner of AI research in the 1980s was the field of expert systems. Unlike the “grandiose claims” critiqued by Lighthill in his report, expert systems were actually providing quantifiable commercial benefits, such as XCON developed at Carnegie Mellon University.
XCON was an expert system that reportedly saved the Digital Equipment Corporation up to $40 million per year. With utility demonstrated by systems like XCON and several high-profile game-playing systems, funding returned to AI in both commercial R&D labs and government programs. It wouldn’t last, however.
The combinatorial explosion, in which the complexity of real world scenarios becomes intractable to enumerate, remained an unsolved challenge. Expert systems in particular were too brittle to deal with changing information, and updating them was expensive. Convincing and capable robots, again, were nowhere to be seen.
Roboticists such as Rodney Brooks and Hans Moravec began to emphasize that the manual work of painstakingly trying to distill human expert knowledge into computer programs was not sufficient to solve the most basic of human skills, such as navigating a busy sidewalk or locating a friend in a noisy crowd. It soon became apparent under what we now know as Moravec’s paradox that for AI, the easy things are hard while the hard things like calculating a large sum or playing expert checkers, are comparatively easy.
Expert systems were proving to be brittle and costly, setting the stage for disappointment, but at the same time learning-based AI was rising to prominence, and many researchers began to flock to this area. Their focus on machine learning included neural networks, as well as a wide variety of other algorithms and models like support vector machines, clustering algorithms, and regression models.
The turning over of the 1980s into the 1990s is regarded by some as the second AI winter, and indeed hundreds of AI companies and divisions shut down during this time. Many of these companies were engaged in building what was at the time high-performance computing (HPC), and their closing down was indicative of the important role Moore's law would play in AI progress.
Deep Blue, the chess champion system developed by IBM in the later 1990s, wasn’t powered by a better expert system, but rather a compute-enabled alpha-beta search. Why pay a premium for a specialized Lisp machine when you can get the same performance from a consumer desktop?
Although Moore’s law has essentially slowed to a crawl as transistors reach physical limits, engineering improvements continue to enable new breakthroughs in modern AI, with NVIDIA and AMD leading the way. And now, a turnkey AI workstation designed specifically with components that best support modern deep learning models can make a huge difference in iteration speed over what would have been state-of-the-art hardware just a few years ago.
In research and practical applications, however, the early 1990s were really more of a slow simmering. This was a time when future Turing award winners were doing seminal work, and neural networks would soon be used in the real-world application of optical character recognition used for tasks like sorting mail. LSTMs made headway against the vanishing gradient problem in 1997, and meaningful research continued to be done in neural networks and other machine learning methods.
The term machine learning continued to gain in popularity, again perhaps as an effort by serious researchers to distance themselves from over-ambitious claims (and science fiction stigma) associated with the term artificial intelligence. Steady progress and improved hardware continued to power useful AI advances into the new millennium, but it wasn’t until the adoption of highly parallel graphics processing units (GPUs) for the naturally parallelizable mathematical primitives of neural networks that we entered the modern era of deep learning.
When thinking about the beginning of the deep learning era of AI, many of us will point to the success of Alex Krizhevsky et al. and their GPU-trained model at the 2012 ImageNet Large Scale Visual Recognition Challenge. While the so-called AlexNet was modest in size by today’s standards, it decisively bested a competitive field of diverse approaches.
Succeeding winners of the challenge were built on similar principles of convolutional neural networks from then on, and it’s no surprise that many of the characteristics of convolutional networks and the kernel weights learned during training have analogues in animal vision systems.
AlexNet wasn’t a particularly deep convolutional neural network, stretching across 8 layers from tip to tail and only 3 layers deeper than LeNet-5, a convolutional network described more than 2 decades earlier. Instead, the major contribution of AlexNet was the demonstration that training on GPUs was both feasible and well worth it.
In a direct lineage from the development of AlexNet, we now have GPUs specifically engineered to support faster and more efficient training of deep neural networks.
The 2012 ILSVRC and performance of AlexNet in the competition was so iconic that it has become the archetype for AI breakthroughs of the last decade.
For better or worse, people talk about “ImageNet moments” for natural language processing, robotics, and gait analysis, to name a few. We’ve come a long way since then, with deep learning models demonstrating near-human performance or better in playing games, generating convincing text, and other categories that fall under the types of “easy is hard” tasks referred to under Moravec’s paradox mentioned earlier.
Deep learning has also contributed to basic scientific research, and in 2020 made an unequivocal contribution to the fundamental challenge in biology of protein structure prediction.
Hardware acceleration has made training deep and wide neural networks feasible, but that doesn’t explain why or even how larger models produce better results than smaller models. Geoffrey Hinton, widely credited as one of the progenitors of the modern deep learning era, suggested in his Neural Networks for Machine Learning MOOC that machine learning with neural networks becomes deep learning at 7 layers.
We don’t think that’s a bad rule of thumb for approximating the start of the deep learning paradigm, but we think we can draw the line more meaningfully by considering how deep learning models train differently than other forms of machine learning. It’s also worth noting that while deep learning most often refers to models made up of multiple layers of fully connected or convolutional neural layers, the term also encompasses models like neural ordinary differential equations or neural cellular automata.
It’s the computational complexity and depth of operations that make deep learning, and the layers don’t necessarily need to be made up of artificial neurons.
A subset of machine learning which hasn’t been mentioned yet in this article but which remains an important area of expertise for millions of data and basic research scientists is statistical learning.
One of the most important concepts in statistical learning and machine learning in general with smaller models and datasets is that of the bias-variance tradeoff. Bias corresponds to underfitting the training data, and is often a symptom of models that don’t have the fitting power to represent patterns in the dataset.
Variance, on the other hand, corresponds to models that are fitted too well to the training data so much so that generalization to held-out validation data is poor. Synonymous terminology that’s a little easier to keep in mind is under/over-fitting.
Cartoon example of overfitting in a simple classification problem. The dark purple spots represent the training data, which the black decision boundary has been overfitted to. The lighter purple dots have been correctly excluded outside the decision boundary, but two orange spots not in the training set (see arrows) have been misclassified as belonging to the out-group. The dotted line in the background represents the true classification boundary. Image by the author.
For statistical models and shallow neural networks, we can generally interpret under-fitting as a symptom of a model being too small, and overfitting a symptom of too large of a model. Of course there are numerous different strategies to regularize models so that they exhibit better generalization, but we’ll leave that discussion mostly for another time.
Larger models also tend to be better capable of taking advantage of larger datasets.
Cartoon representation of the ability of larger models to take advantage of larger datasets. Image by the author.
Overfitting is often seen in the difference between model performance on the training and validation datasets, and this deviation can get worse with more training/bigger models. However, an interesting phenomenon occurs when both the model and the dataset gets even larger. This fascinating emergent property of deep double descent refers to an initial period of improved performance, followed by decreasing performance due to overfitting, but finally superseded by even better performance. This occurs with increasing model depth, width, or training data, and might be most logical place to draw the distinguishing line between deep learning and shallower neural networks.
Cartoon representation of deep double descent. Image by the author.
Somewhat counter-intuitively, in the deep learning regime marked by deep double descent, models actually tend to generalize better and regularization techniques like dropout tend to yield better results. Other hallmarks of deep learning, like the lottery ticket hypothesis, are likely related.
This concludes our discussion of the history and rationale of a few sub-fields of AI, and what they’ve been called at different points in their history.
We also discussed an interesting identifying characteristic of deep learning models that allows them to continue to improve with increasing scale or data when we would intuitively expect them to massively overfit. Of course, if you are pitching a project to investors/managers/funders, or pitching yourself to a potential employer, you may want to consider your terminology from a marketing perspective instead.
In that case you may want to describe your work to the public as AI, to investors as deep learning, and to your colleagues and peers at conferences as machine learning.
Have any questions?
Contact Exxact Today


{kind=link}