Benchmarks
NVIDIA RTX A4500 Performance Benchmarks for RELION Cryo-EM
February 23, 2022
5 min read


As a value-added supplier of scientific workstations and servers, Exxact regularly provides reference benchmarks in various GPU configurations to guide Cryogenic electron microscopy (cryo-EM) scientists looking to procure systems optimized for their research. In this blog we benchmark the RTX A4500 performance using RELION Cryo-EM, comparing GPU runtime to Total Runtime performance.
RELION (REgularised LIkelihood OptimisatioN) has revolutionized the cryo–EM field since 2012. Developed by Scheres Lab at the MRC Laboratory of Molecular Biology, this stand-alone computer program uses a Bayesian approach to refine macromolecular structures by single-particle analysis of electron cryo-microscopy data.
The development of RELION is supported through long-term funding by the UK Medical Research Council, and is distributed under a GPLv2 license. This means that anyone (including commercial users) can download, use and modify RELION without having to pay anything. They just request that if RELION is useful in your work, that you cite their papers
With advancements in automation, compute power, and visual technology, the scope and complexity of datasets used in cryo-EM have grown substantially. GPU support and acceleration are essential for the flexibility of resource management, prevention of memory limitations, and to address the most computationally intensive processes of cryo-EM such as image classification, and high-resolution refinement.
Exxact RTX A4500 Workstation System Specs:
| Nodes | 1 |
| Processor / Count | 2x AMD EPYC 7552 |
| Total Logical Cores | 48 |
| Memory | DDR4 512GB |
| Storage | NVMe 3.84TB |
| OS | Ubuntu 18.04 |
| CUDA Version | 11.4 |
| RELION Version | 3.1 |
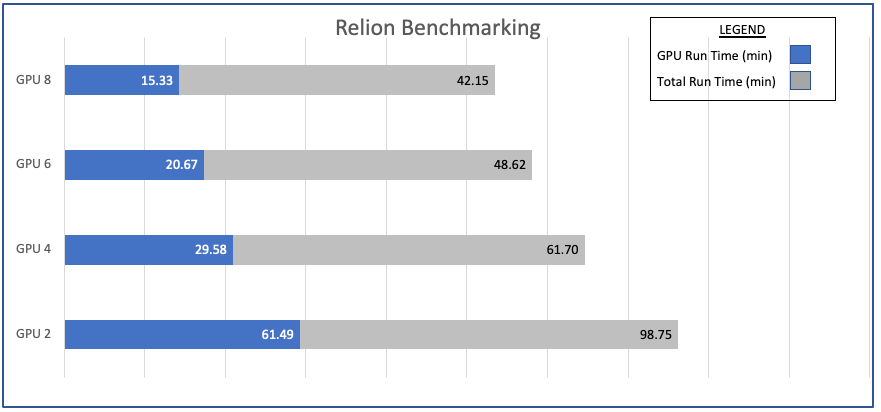
Benchmarks below are 3D classifications performed using the Plasmodium ribosome dataset
Although a minimum of 64GB of RAM is recommended to run RELION with small image sizes (eg. 200×200) on either the original or accelerated versions of RELION, 360×360 problems run best on systems with more than 128GB of RAM. Systems with 256GB or more RAM are recommended for the CPU-accelerated kernels on larger image sizes. Insufficient memory causes individual MPI ranks to be killed, leading to zombie RELION jobs.
Where some users may want to run more than one MPI rank per GPU, sufficient GPU memory is needed. Each MPI-slave that shares a GPU increases the use of memory. In this case, however, it’s recommended running a single MPI-slave per GPU for good performance and stable execution.
Note that 3D auto-refinement always needs to be run with at least 3 MPI processes (a master, and one slave for each half-set). Therefore, machines with at least two GPU cards would be preferable for refinement using GPUs. If you need to (or want to) run multiple mpi-ranks on each GPU, RELION will attempt to do so in an efficient way if you simply specify more ranks than there are GPUs.
You can run multiple threads just as with previous versions of RELION, using the --j <x> option. Each MPI process will launch the specified number of threads. This may speed up calculations, without costing much extra memory either on the CPU (RAM) or on the GPU.
For example: On a 4-GPU development machine with 16 visible cores, you would run run classifications or refinements using:
mpirun -n 5 ‘which relion_refine_mpi‘ --j 4 --gpu |
Which produces 4 working (slave) mpi-ranks, each with 4 threads. This produces a single rank per card, but allows multiple CPU-cores to use each GPU, maximizing overall hardware utilization.
Each mpi-rank requires it’s own copy of large object in CPU and GPU memory, but if it can fit into memory it may in fact be faster to run 2 or more MPI processes on each GPU, as the MPI processes may become asynchronized so that one MPI process is busy doing calculations, while the other one for example is reading images from disk.
The GPUs tested were Ampere-based. As a result, it is more beneficial to scale out than scale up. Another thing to note is the diminishing returns in scaling once you pass 4 GPUs.
Have any questions about RELION or other applications for molecular dynamics?
Contact Exxact Today
As a value-added supplier of scientific workstations and servers, Exxact regularly provides reference benchmarks in various GPU configurations to guide Cryogenic electron microscopy (cryo-EM) scientists looking to procure systems optimized for their research. In this blog we benchmark the RTX A4500 performance using RELION Cryo-EM, comparing GPU runtime to Total Runtime performance.
RELION (REgularised LIkelihood OptimisatioN) has revolutionized the cryo–EM field since 2012. Developed by Scheres Lab at the MRC Laboratory of Molecular Biology, this stand-alone computer program uses a Bayesian approach to refine macromolecular structures by single-particle analysis of electron cryo-microscopy data.
The development of RELION is supported through long-term funding by the UK Medical Research Council, and is distributed under a GPLv2 license. This means that anyone (including commercial users) can download, use and modify RELION without having to pay anything. They just request that if RELION is useful in your work, that you cite their papers
With advancements in automation, compute power, and visual technology, the scope and complexity of datasets used in cryo-EM have grown substantially. GPU support and acceleration are essential for the flexibility of resource management, prevention of memory limitations, and to address the most computationally intensive processes of cryo-EM such as image classification, and high-resolution refinement.
Exxact RTX A4500 Workstation System Specs:
| Nodes | 1 |
| Processor / Count | 2x AMD EPYC 7552 |
| Total Logical Cores | 48 |
| Memory | DDR4 512GB |
| Storage | NVMe 3.84TB |
| OS | Ubuntu 18.04 |
| CUDA Version | 11.4 |
| RELION Version | 3.1 |
Benchmarks below are 3D classifications performed using the Plasmodium ribosome dataset
Although a minimum of 64GB of RAM is recommended to run RELION with small image sizes (eg. 200×200) on either the original or accelerated versions of RELION, 360×360 problems run best on systems with more than 128GB of RAM. Systems with 256GB or more RAM are recommended for the CPU-accelerated kernels on larger image sizes. Insufficient memory causes individual MPI ranks to be killed, leading to zombie RELION jobs.
Where some users may want to run more than one MPI rank per GPU, sufficient GPU memory is needed. Each MPI-slave that shares a GPU increases the use of memory. In this case, however, it’s recommended running a single MPI-slave per GPU for good performance and stable execution.
Note that 3D auto-refinement always needs to be run with at least 3 MPI processes (a master, and one slave for each half-set). Therefore, machines with at least two GPU cards would be preferable for refinement using GPUs. If you need to (or want to) run multiple mpi-ranks on each GPU, RELION will attempt to do so in an efficient way if you simply specify more ranks than there are GPUs.
You can run multiple threads just as with previous versions of RELION, using the --j <x> option. Each MPI process will launch the specified number of threads. This may speed up calculations, without costing much extra memory either on the CPU (RAM) or on the GPU.
For example: On a 4-GPU development machine with 16 visible cores, you would run run classifications or refinements using:
mpirun -n 5 ‘which relion_refine_mpi‘ --j 4 --gpu |
Which produces 4 working (slave) mpi-ranks, each with 4 threads. This produces a single rank per card, but allows multiple CPU-cores to use each GPU, maximizing overall hardware utilization.
Each mpi-rank requires it’s own copy of large object in CPU and GPU memory, but if it can fit into memory it may in fact be faster to run 2 or more MPI processes on each GPU, as the MPI processes may become asynchronized so that one MPI process is busy doing calculations, while the other one for example is reading images from disk.
The GPUs tested were Ampere-based. As a result, it is more beneficial to scale out than scale up. Another thing to note is the diminishing returns in scaling once you pass 4 GPUs.
Have any questions about RELION or other applications for molecular dynamics?
Contact Exxact Today