Deep Learning
Maximizing AI Efficiency - Hyperparameter Tuning and Regulation
December 19, 2024
8 min read


Hyperparameter tuning is essential for optimizing AI model performance. You can achieve better accuracy, efficiency, and resource utilization by carefully adjusting hyperparameters. Adjusting these factors within a model ensures it can generalize to new data and continue to provide value in your workload.
Alongside hyperparameter tuning, we can employ various regularization techniques and data augmentation strategies to refine model performance further to reduce overfitting or constraining a model’s complexity.
To decide on picking the right algorithm or model, read our last part of the Maximizing AI Efficiency series - Selecting the Right Model.
Hyperparameters are configuration settings external to the model that cannot be learned from the data, such as learning rates, batch sizes, and regularization coefficients. Tuning these parameters is critical for enhancing model accuracy and efficiency.
However, it's a challenging task due to high computational costs, risks of overfitting, and diminishing returns. Effective hyperparameter tuning bridges the gap between a suboptimal model and one that performs at its peak.
This brute-force approach evaluates every possible combination of hyperparameter values from a predefined grid. While simple and thorough, it becomes computationally expensive as the number of parameters increases, making it suitable for smaller models or datasets.
Unlike grid search, random search samples hyperparameters randomly from specified distributions. This method often finds optimal configurations faster and is more efficient in higher-dimensional spaces. However, there is a chance it may miss the true optimal configuration.
This probabilistic method builds a model of the objective function and uses it to choose the most promising hyperparameters iteratively.
Inspired by natural selection, genetic algorithms employ operations like selection, mutation, and crossover to explore the hyperparameter space. This method excels in non-linear or multimodal spaces but can be time-consuming.
AutoML automates hyperparameter tuning and other processes like feature engineering and model selection. Frameworks like Google AutoML, H2O.ai, and Auto-sklearn enable users to achieve high performance with minimal manual intervention, making it ideal for those with limited expertise.
Regularization is a set of techniques designed to reduce overfitting by constraining the model's complexity. Here are the most common regularization methods:
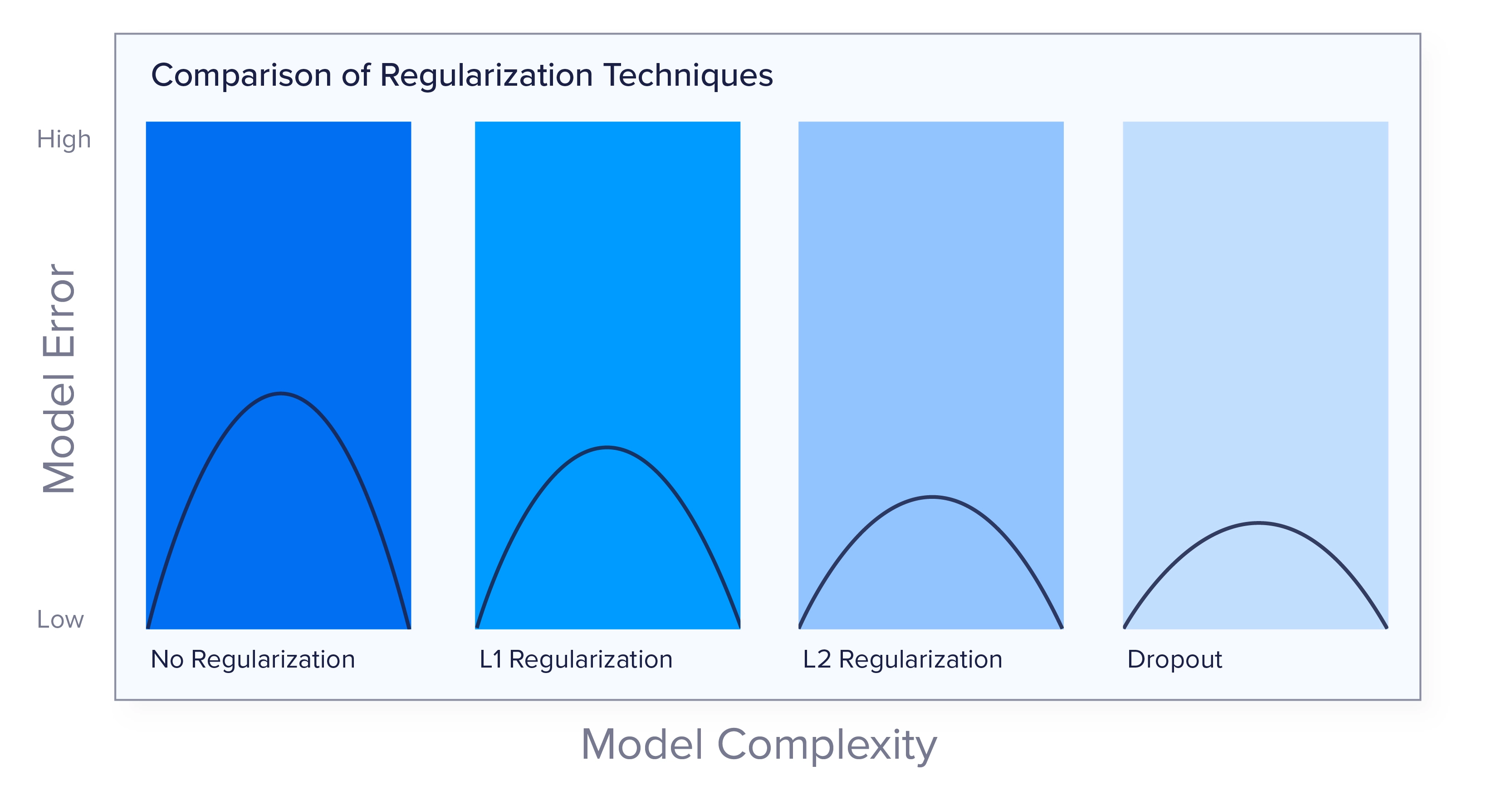
L1 regularization penalizes the absolute values of weights, promoting sparsity by driving some weights to zero. This results in sparse models through feature selection, making it ideal when interpretability and feature selection are critical. By reducing the number of active features, L1 regularization can simplify the model, making it easier to understand and potentially improving performance on high-dimensional data.
“L2 regularization adds a penalty proportional to the square of the weights, encouraging smaller weight magnitudes without eliminating them. This reduces the impact of less significant features and helps the model generalize better. L2 regularization is ideal for achieving smooth, non-sparse solutions. Distributing the error among all weights ensures that no single feature dominates, leading to more stable and robust models.
Dropout prevents overfitting by randomly ‘dropping’ neurons during training, forcing the network to learn redundant representations. This technique is particularly useful in deep architectures, such as neural networks with many parameters. By ensuring that the network does not rely too heavily on any single neuron, dropout improves generalization and reduces overfitting. This leads to more robust models that perform better on unseen data.
Early stopping monitors validation performance to halt training when improvements plateau, preventing overfitting and saving computational resources. It’s effective when combined with proper validation strategies. These early stopping mechanisms are user-defined and can ultimately add a layer of complexity to the training.
Data-centric hyperparameter tuning focuses on optimizing hyperparameters by considering the characteristics and quality of the data used to train the model. Unlike traditional model-centric approaches that primarily adjust the model’s architecture and parameters, data-centric tuning emphasizes the importance of data preprocessing, augmentation, and selection. Improving the data aims to enhance the model’s performance and generalization capabilities, leading to more robust and reliable outcomes.
By generating variations of the training data through techniques such as cropping, flipping, rotation, and synthetic augmentation, you can significantly enhance model robustness. These methods help the model generalize better by exposing it to a wider range of scenarios. However, careful application is necessary to avoid introducing noise that could destabilize training. Ensuring that augmented data represents real-world conditions is crucial for maintaining model accuracy.
Batch size plays a critical role in influencing optimization stability and computational efficiency. Smaller batch sizes can lead to more stable updates but may require more iterations, while larger batch sizes can speed up training but might cause instability. Learning rate scheduling techniques, such as step decay and cosine annealing, help the model converge smoothly by adjusting the learning rate over time. These schedules can prevent the model from getting stuck in local minima and improve overall training efficiency.
Selecting or transforming features can drastically impact model performance. Effective feature selection reduces dimensionality, removes irrelevant data, and highlights the most informative attributes. Automated tools like Principal Component Analysis (PCA) and Recursive Feature Elimination (RFE) can streamline this process by identifying and retaining the most significant features. Additionally, feature engineering, which involves creating new features from existing data, can uncover hidden patterns and relationships, further enhancing model accuracy and interpretability.
Hyperparameter tuning is a vital step in maximizing the efficiency and performance of AI models. From traditional methods like grid and random search to advanced techniques like Bayesian optimization and AutoML, there are numerous strategies to explore. Coupled with regularization techniques, data augmentation, and practical tips, these methods ensure your models achieve peak performance while minimizing resource consumption. Experimentation is key—tailor these approaches to suit your specific AI workload and goals.
By combining hyperparameter tuning and regularization techniques along with picking the ideal training algorithm, you can achieve optimal model performance while ensuring the model remains robust and effectively generalize to new data.
Looking to expand your high-performance computing infrastructure? Exxact is a leading HPC solutions provider that can deliver fleets of custom-built workstations, servers, and clusters. Contact us today for more information!

Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research.
Configure NowHyperparameter tuning is essential for optimizing AI model performance. You can achieve better accuracy, efficiency, and resource utilization by carefully adjusting hyperparameters. Adjusting these factors within a model ensures it can generalize to new data and continue to provide value in your workload.
Alongside hyperparameter tuning, we can employ various regularization techniques and data augmentation strategies to refine model performance further to reduce overfitting or constraining a model’s complexity.
To decide on picking the right algorithm or model, read our last part of the Maximizing AI Efficiency series - Selecting the Right Model.
Hyperparameters are configuration settings external to the model that cannot be learned from the data, such as learning rates, batch sizes, and regularization coefficients. Tuning these parameters is critical for enhancing model accuracy and efficiency.
However, it's a challenging task due to high computational costs, risks of overfitting, and diminishing returns. Effective hyperparameter tuning bridges the gap between a suboptimal model and one that performs at its peak.
This brute-force approach evaluates every possible combination of hyperparameter values from a predefined grid. While simple and thorough, it becomes computationally expensive as the number of parameters increases, making it suitable for smaller models or datasets.
Unlike grid search, random search samples hyperparameters randomly from specified distributions. This method often finds optimal configurations faster and is more efficient in higher-dimensional spaces. However, there is a chance it may miss the true optimal configuration.
This probabilistic method builds a model of the objective function and uses it to choose the most promising hyperparameters iteratively.
Inspired by natural selection, genetic algorithms employ operations like selection, mutation, and crossover to explore the hyperparameter space. This method excels in non-linear or multimodal spaces but can be time-consuming.
AutoML automates hyperparameter tuning and other processes like feature engineering and model selection. Frameworks like Google AutoML, H2O.ai, and Auto-sklearn enable users to achieve high performance with minimal manual intervention, making it ideal for those with limited expertise.
Regularization is a set of techniques designed to reduce overfitting by constraining the model's complexity. Here are the most common regularization methods:
L1 regularization penalizes the absolute values of weights, promoting sparsity by driving some weights to zero. This results in sparse models through feature selection, making it ideal when interpretability and feature selection are critical. By reducing the number of active features, L1 regularization can simplify the model, making it easier to understand and potentially improving performance on high-dimensional data.
“L2 regularization adds a penalty proportional to the square of the weights, encouraging smaller weight magnitudes without eliminating them. This reduces the impact of less significant features and helps the model generalize better. L2 regularization is ideal for achieving smooth, non-sparse solutions. Distributing the error among all weights ensures that no single feature dominates, leading to more stable and robust models.
Dropout prevents overfitting by randomly ‘dropping’ neurons during training, forcing the network to learn redundant representations. This technique is particularly useful in deep architectures, such as neural networks with many parameters. By ensuring that the network does not rely too heavily on any single neuron, dropout improves generalization and reduces overfitting. This leads to more robust models that perform better on unseen data.
Early stopping monitors validation performance to halt training when improvements plateau, preventing overfitting and saving computational resources. It’s effective when combined with proper validation strategies. These early stopping mechanisms are user-defined and can ultimately add a layer of complexity to the training.
Data-centric hyperparameter tuning focuses on optimizing hyperparameters by considering the characteristics and quality of the data used to train the model. Unlike traditional model-centric approaches that primarily adjust the model’s architecture and parameters, data-centric tuning emphasizes the importance of data preprocessing, augmentation, and selection. Improving the data aims to enhance the model’s performance and generalization capabilities, leading to more robust and reliable outcomes.
By generating variations of the training data through techniques such as cropping, flipping, rotation, and synthetic augmentation, you can significantly enhance model robustness. These methods help the model generalize better by exposing it to a wider range of scenarios. However, careful application is necessary to avoid introducing noise that could destabilize training. Ensuring that augmented data represents real-world conditions is crucial for maintaining model accuracy.
Batch size plays a critical role in influencing optimization stability and computational efficiency. Smaller batch sizes can lead to more stable updates but may require more iterations, while larger batch sizes can speed up training but might cause instability. Learning rate scheduling techniques, such as step decay and cosine annealing, help the model converge smoothly by adjusting the learning rate over time. These schedules can prevent the model from getting stuck in local minima and improve overall training efficiency.
Selecting or transforming features can drastically impact model performance. Effective feature selection reduces dimensionality, removes irrelevant data, and highlights the most informative attributes. Automated tools like Principal Component Analysis (PCA) and Recursive Feature Elimination (RFE) can streamline this process by identifying and retaining the most significant features. Additionally, feature engineering, which involves creating new features from existing data, can uncover hidden patterns and relationships, further enhancing model accuracy and interpretability.
Hyperparameter tuning is a vital step in maximizing the efficiency and performance of AI models. From traditional methods like grid and random search to advanced techniques like Bayesian optimization and AutoML, there are numerous strategies to explore. Coupled with regularization techniques, data augmentation, and practical tips, these methods ensure your models achieve peak performance while minimizing resource consumption. Experimentation is key—tailor these approaches to suit your specific AI workload and goals.
By combining hyperparameter tuning and regularization techniques along with picking the ideal training algorithm, you can achieve optimal model performance while ensuring the model remains robust and effectively generalize to new data.
Looking to expand your high-performance computing infrastructure? Exxact is a leading HPC solutions provider that can deliver fleets of custom-built workstations, servers, and clusters. Contact us today for more information!
Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research.
Configure Now