Deep Learning
Deep Learning in Natural Language Processing: History and Achievements
August 12, 2020
13 min read


As we grow, we learn how to use language to communicate with people around us. First, we master our native language: listen to how family members and other children speak and repeat after them; memorize words as they relate to every object and phenomenon; learn sentence structure, punctuation, and other rules of written language. We may repeat a similar path when learning a foreign language. And this lifelong learning and practice come naturally to us, although not without some effort.
Unlike humans, early computers were unable to understand speech or the written word and could only react to a specific set of commands. It was like that for decades. The situation changed several years ago, and now conversational agents like Siri and a large number of chatbots can “understand” our requests and “answer” questions with a high level of quality.
In this article, we’ll give a brief overview of the history of natural language research and discuss three achievements that are widely used in the discipline today.
Natural language processing focuses on interactions between computers and humans in their natural language. It intersects with such disciplines as computational linguistics, information engineering, computer science, and artificial intelligence.
NLP has a pretty long history, dating back to the 1950’s. And from its very beginning, the field of study has focused on tasks like machine translation, question answering, information retrieval, summarization, information extraction, topic modeling and, more recently, sentiment analysis.
Software for solving language-related tasks was developing as new approaches and techniques for making sense of textual data were introduced. First, systems used handwritten rules based on expert knowledge and could only solve specific, narrowly defined problems. For example, a system used in the 1954 Georgetown-IBM experiment relied on six grammar rules and 250 lexical items to translate over 60 sentences from Russian to English.
Another example is ELIZA, a chatbot coded by Joseph Weizenbaum in 1966. ELIZA simulated conversation by detecting keywords in user messages and matching them to canned answers. The program relied on scripts that dictated how to interact. A famous script, DOCTOR, imitated a chat with a Rogerian psychologist, who typically mirrors back user replies when asking new questions.
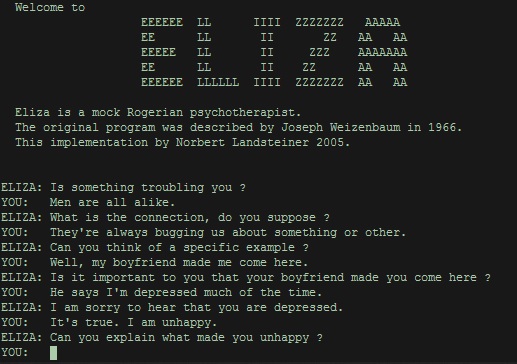
An example of a conversation with a chatbot. Source: Wikipedia Commons
You can talk with ELIZA about everything that bothers you here.
The machine learning (ML) era began in the late 1980’s with a growing volume of machine-readable data and computing resources contributing to the shift. The whole principle of language processing had changed. Instead of creating rules to tell software how to understand and process text, researchers started using ML algorithms that can learn this by analyzing training data. An algorithm processes a large corpus of annotated texts – texts with mapped target answers, AKA features to be able to find these attributes in new data.
Among commonly used ML algorithms, like decision trees or linear support vector machines, were neural networks – a family of ML models that mimic the functioning of the human brain and whose architecture is also inspired by its structure.
Machine learning requires scientists to design features for words. The problem is languages have hundreds of thousands of words. The number of word combinations that could form certain meanings and the number of all possible sentences are impossible to count. How many features do researchers consider to prepare a training set that would fully describe a given language? A LOT. “…even with a huge example set we are very likely to observe events that never occurred in the example set and that are very different from all the examples that did occur in it,” notes Yoav Goldberg in Neural Network Methods for Natural Language Processing.
So, in processing language data with ML, one faces a data sparsity problem. Sparsity of language data comes with another issue that data scientists call a curse of dimensionality. The more features (dimensions) in a dataset, the larger the amount of data must be generalized. Which means more load on a machine learning algorithm. Since ML models can’t effectively process data with so many attributes, specialists needed to find another method.
The new method used was Deep learning – a branch of machine learning that focuses on training deep neural networks. Deep neural networks are called this because they have multiple hidden layers, and their performance grows with their number.
One of the wonderful things about deep learning is that it allows researchers to do less manual feature engineering because neural networks can learn features from training data.
There were unsuccessful attempts to train deep neural nets from scratch in the 1990’s, but the breakthrough happened in 2006. Geoffrey Hinton, Simon Osindero, and Yee-Whye Teh developed an algorithm to train a network with three hidden layers.
“Once scientists learned how to train deep neural networks, they created a revolution in computer vision and audio processing and then – in NLP. Introduction of novel neural network architectures like Transformers [more on it later] allowed for making a huge leap in processing texts,” notes AltexSoft data science competence leader Alexander Konduforov.
Besides algorithms for training and new architectures, other conditions required to propel deep learning in NLP include sufficient computing resources (the right hardware) and a constantly growing volume of digital data (datasets) that can be used to train large neural networks.

With that understanding, let’s get to some of the achievements that fueled the progress in natural language.
Humans can easily read a sentence, understanding the concepts behind written words. To make it possible for language models to “see” and understand text, every word in a dataset must be numerically represented. Ideally, such a representation must refer to a word’s linguistic meaning and semantic interconnections with other words.
The most common approach to do so now is to use distributed representations of words in a vector space called word embeddings. These representations rely on word usage, so that words with similar meanings have a similar representation.
.png)
Word embeddings showing the semantic relationship of the concept of sentiment between word pairs. Image by Garrett Hoffman. Source: O’Reilly
Word embeddings are dense, low-dimensional vector representations that preserve contextual word similarity. So, using them helps specialists to develop models with better performance, Konduforov says, “Word embedding is a real-valued vector with just hundreds or tens of dimensions. Previously, much larger sparse vectors with thousands and even millions of dimensions were used (think about bag-of-words or one-hot encoding). Such large vectors didn’t work well for neural networks.”
On the contrary, word embeddings have at least two advantages, Alexander adds, “Besides being better suited for neural networks, they capture some word semantics and relationships between words. Therefore, the accuracy of the models and their predictions is usually much higher.”
Like neural networks themselves, the attention mechanism is another invention inspired by the way humans think and reason, particularly, how they perceive visual information. Researchers Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio first introduced the attention mechanism in 2015 as an extension to an encoder-decoder model.
An encoder-decoder model organizes two recurrent neural networks, and it’s typically used for neural machine translation. The first network encodes a source sequence; while the second one decodes this source sequence into the target sequence.
The problem scientists wanted to solve was that a model struggled to translate the whole sentence at once, encoding the full source sentence into a fixed-length vector. And the longer the sentence was, the worse a model performed.
With the attention mechanism, a model focuses on parts of a source sentence (a word or phrase) where the most relevant information is concentrated. Then it predicts a target word based on the context of surrounding words.
Here is how a model distributes its attention to translate sentences from English to French, defining the correct word order. Words at which a model pays the most attention are painted in white:
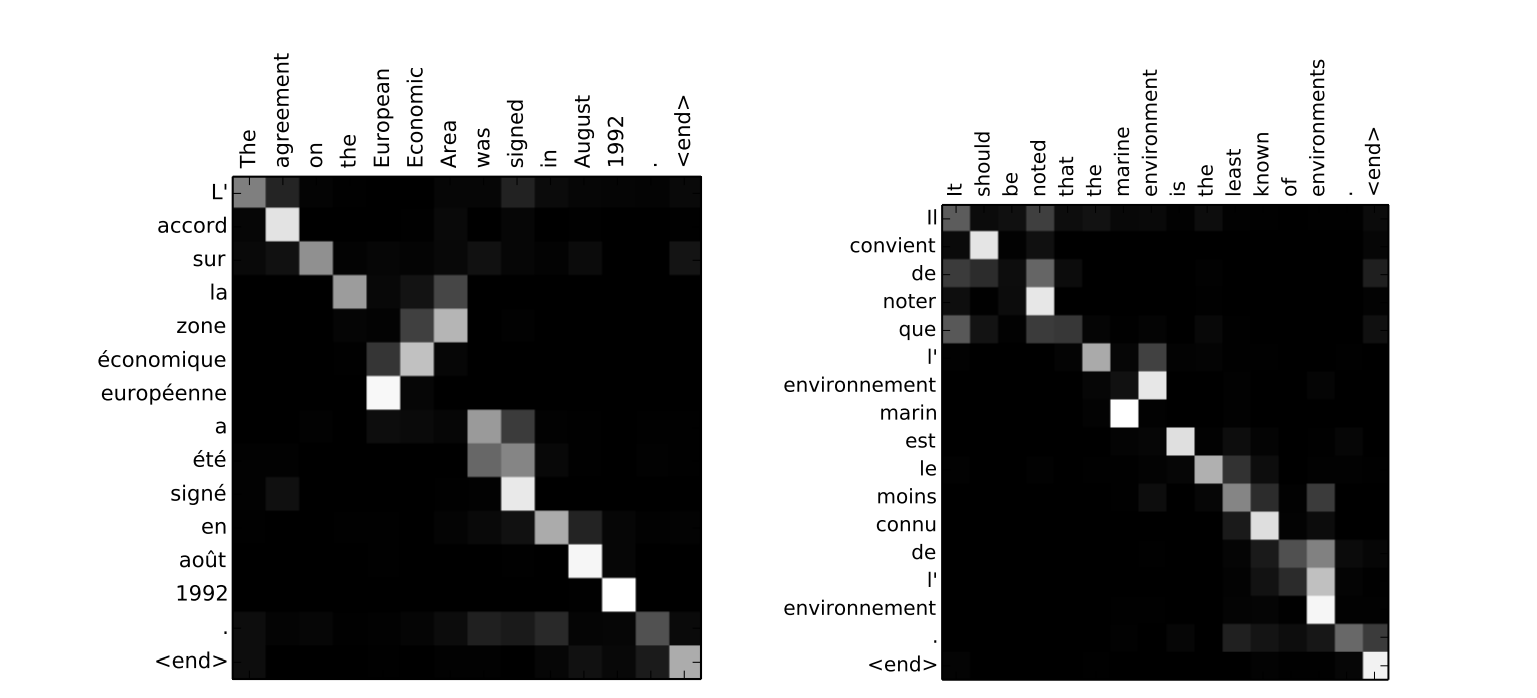
The attention mechanism in practice. Source: Neural Machine Translation by Jointly Learning to Align and Translate
Translation isn’t the only use case for the attention mechanism. In 2019, scientists from Johns Hopkins University and Amazon described how they trained a deep learning system that can help Alexa better focus on utterances by those who use the wake word (Alexa) and pay less attention to background speech. One of the proposed models showed a 15 percent improvement in performance.
A Transformer is a neural network architecture introduced in 2017 by Google AI researchers to more effectively process ordered sequences of text for tasks like translation and summarization. The novelty of Transformer-based models is that they use the self-attention mechanism.
Before Transformers, recurrent neural networks (RNNs) were common tools for solving NLP tasks. RNNs were taking multiple steps to define a target word when scanning sentences left-to-right or right-to-left and analyzing surrounding words. For instance, to define the meaning of the word “bank” in the sentence “I arrived at the bank after crossing the river,” RNNs needed to read each word between “bank” and “river” step by step.
A Transformer, however, takes fewer steps because it understands relationships between all words in a sentence, no matter where they are located. “It can learn to immediately attend to the word ‘river’ and make this decision in a single step,” the researchers note.
In 2018, Google open-sourced the BERT (Bidirectional Encoder Representations from Transformers) language representation model that is based on the Transformer architecture (Well, its title already hints at that.) As a pre-training technique, BERT is intended to deal with the shortage of training data.
Of course, way more developments made it to the NLP Hall of Fame. Listing them all is beyond this article’s scope. These three achievements demonstrate the shift from simple approaches like keyword spotting and reliance on handcrafted rules. Modern software can understand the meaning of words or phrases based on context and take fewer steps to define “where to look” to complete an NLP task faster.
How about looking at a bigger picture on how NLP research is evolving?
Alexander Konduforov highlights an almost complete shift from recurrent and convolutional architectures for deep learning models to transformer-based ones: “Transfer learning and language models are predominant approaches nowadays, and for most of the NLP tasks, they show a drastic victory over non-deep learning models and classic RNN/CNN networks.”
Transformers, which entered the game in 2017, will be pushing model performance boundaries: “Transformer-based language models rely on a huge corpus of texts, and recent papers show that simply scaling up the size of a BERT-like architecture and feeding it more data allows us to increase the performance even more, so the capacity is yet to be reached,” adds Alexander.
On the other hand, there are also trends for the minimization of NLP models. Knowledge distillation is one of the approaches for computer vision that was recently adopted in NLP. In April 2020, researchers from Google Brain and Carnegie Mellon University introduced a thin version of BERT – MobileBERT – that can be deployed on (guess what?) mobile devices.
What future techniques and approaches will the NLP community invent in the next year? We’ll have to wait and see.
Contributor
Thanks to AltexSoft, our contributor for this post.
AltexSoft is a technology consulting firm that helps businesses build custom software and handle transformational products in the travel and other industries. Their data science unit covers both machine learning and data engineering. You can visit the AltexSoft blog for more useful content.

As we grow, we learn how to use language to communicate with people around us. First, we master our native language: listen to how family members and other children speak and repeat after them; memorize words as they relate to every object and phenomenon; learn sentence structure, punctuation, and other rules of written language. We may repeat a similar path when learning a foreign language. And this lifelong learning and practice come naturally to us, although not without some effort.
Unlike humans, early computers were unable to understand speech or the written word and could only react to a specific set of commands. It was like that for decades. The situation changed several years ago, and now conversational agents like Siri and a large number of chatbots can “understand” our requests and “answer” questions with a high level of quality.
In this article, we’ll give a brief overview of the history of natural language research and discuss three achievements that are widely used in the discipline today.
Natural language processing focuses on interactions between computers and humans in their natural language. It intersects with such disciplines as computational linguistics, information engineering, computer science, and artificial intelligence.
NLP has a pretty long history, dating back to the 1950’s. And from its very beginning, the field of study has focused on tasks like machine translation, question answering, information retrieval, summarization, information extraction, topic modeling and, more recently, sentiment analysis.
Software for solving language-related tasks was developing as new approaches and techniques for making sense of textual data were introduced. First, systems used handwritten rules based on expert knowledge and could only solve specific, narrowly defined problems. For example, a system used in the 1954 Georgetown-IBM experiment relied on six grammar rules and 250 lexical items to translate over 60 sentences from Russian to English.
Another example is ELIZA, a chatbot coded by Joseph Weizenbaum in 1966. ELIZA simulated conversation by detecting keywords in user messages and matching them to canned answers. The program relied on scripts that dictated how to interact. A famous script, DOCTOR, imitated a chat with a Rogerian psychologist, who typically mirrors back user replies when asking new questions.
An example of a conversation with a chatbot. Source: Wikipedia Commons
You can talk with ELIZA about everything that bothers you here.
The machine learning (ML) era began in the late 1980’s with a growing volume of machine-readable data and computing resources contributing to the shift. The whole principle of language processing had changed. Instead of creating rules to tell software how to understand and process text, researchers started using ML algorithms that can learn this by analyzing training data. An algorithm processes a large corpus of annotated texts – texts with mapped target answers, AKA features to be able to find these attributes in new data.
Among commonly used ML algorithms, like decision trees or linear support vector machines, were neural networks – a family of ML models that mimic the functioning of the human brain and whose architecture is also inspired by its structure.
Machine learning requires scientists to design features for words. The problem is languages have hundreds of thousands of words. The number of word combinations that could form certain meanings and the number of all possible sentences are impossible to count. How many features do researchers consider to prepare a training set that would fully describe a given language? A LOT. “…even with a huge example set we are very likely to observe events that never occurred in the example set and that are very different from all the examples that did occur in it,” notes Yoav Goldberg in Neural Network Methods for Natural Language Processing.
So, in processing language data with ML, one faces a data sparsity problem. Sparsity of language data comes with another issue that data scientists call a curse of dimensionality. The more features (dimensions) in a dataset, the larger the amount of data must be generalized. Which means more load on a machine learning algorithm. Since ML models can’t effectively process data with so many attributes, specialists needed to find another method.
The new method used was Deep learning – a branch of machine learning that focuses on training deep neural networks. Deep neural networks are called this because they have multiple hidden layers, and their performance grows with their number.
One of the wonderful things about deep learning is that it allows researchers to do less manual feature engineering because neural networks can learn features from training data.
There were unsuccessful attempts to train deep neural nets from scratch in the 1990’s, but the breakthrough happened in 2006. Geoffrey Hinton, Simon Osindero, and Yee-Whye Teh developed an algorithm to train a network with three hidden layers.
“Once scientists learned how to train deep neural networks, they created a revolution in computer vision and audio processing and then – in NLP. Introduction of novel neural network architectures like Transformers [more on it later] allowed for making a huge leap in processing texts,” notes AltexSoft data science competence leader Alexander Konduforov.
Besides algorithms for training and new architectures, other conditions required to propel deep learning in NLP include sufficient computing resources (the right hardware) and a constantly growing volume of digital data (datasets) that can be used to train large neural networks.
With that understanding, let’s get to some of the achievements that fueled the progress in natural language.
Humans can easily read a sentence, understanding the concepts behind written words. To make it possible for language models to “see” and understand text, every word in a dataset must be numerically represented. Ideally, such a representation must refer to a word’s linguistic meaning and semantic interconnections with other words.
The most common approach to do so now is to use distributed representations of words in a vector space called word embeddings. These representations rely on word usage, so that words with similar meanings have a similar representation.
Word embeddings showing the semantic relationship of the concept of sentiment between word pairs. Image by Garrett Hoffman. Source: O’Reilly
Word embeddings are dense, low-dimensional vector representations that preserve contextual word similarity. So, using them helps specialists to develop models with better performance, Konduforov says, “Word embedding is a real-valued vector with just hundreds or tens of dimensions. Previously, much larger sparse vectors with thousands and even millions of dimensions were used (think about bag-of-words or one-hot encoding). Such large vectors didn’t work well for neural networks.”
On the contrary, word embeddings have at least two advantages, Alexander adds, “Besides being better suited for neural networks, they capture some word semantics and relationships between words. Therefore, the accuracy of the models and their predictions is usually much higher.”
Like neural networks themselves, the attention mechanism is another invention inspired by the way humans think and reason, particularly, how they perceive visual information. Researchers Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio first introduced the attention mechanism in 2015 as an extension to an encoder-decoder model.
An encoder-decoder model organizes two recurrent neural networks, and it’s typically used for neural machine translation. The first network encodes a source sequence; while the second one decodes this source sequence into the target sequence.
The problem scientists wanted to solve was that a model struggled to translate the whole sentence at once, encoding the full source sentence into a fixed-length vector. And the longer the sentence was, the worse a model performed.
With the attention mechanism, a model focuses on parts of a source sentence (a word or phrase) where the most relevant information is concentrated. Then it predicts a target word based on the context of surrounding words.
Here is how a model distributes its attention to translate sentences from English to French, defining the correct word order. Words at which a model pays the most attention are painted in white:
The attention mechanism in practice. Source: Neural Machine Translation by Jointly Learning to Align and Translate
Translation isn’t the only use case for the attention mechanism. In 2019, scientists from Johns Hopkins University and Amazon described how they trained a deep learning system that can help Alexa better focus on utterances by those who use the wake word (Alexa) and pay less attention to background speech. One of the proposed models showed a 15 percent improvement in performance.
A Transformer is a neural network architecture introduced in 2017 by Google AI researchers to more effectively process ordered sequences of text for tasks like translation and summarization. The novelty of Transformer-based models is that they use the self-attention mechanism.
Before Transformers, recurrent neural networks (RNNs) were common tools for solving NLP tasks. RNNs were taking multiple steps to define a target word when scanning sentences left-to-right or right-to-left and analyzing surrounding words. For instance, to define the meaning of the word “bank” in the sentence “I arrived at the bank after crossing the river,” RNNs needed to read each word between “bank” and “river” step by step.
A Transformer, however, takes fewer steps because it understands relationships between all words in a sentence, no matter where they are located. “It can learn to immediately attend to the word ‘river’ and make this decision in a single step,” the researchers note.
In 2018, Google open-sourced the BERT (Bidirectional Encoder Representations from Transformers) language representation model that is based on the Transformer architecture (Well, its title already hints at that.) As a pre-training technique, BERT is intended to deal with the shortage of training data.
Of course, way more developments made it to the NLP Hall of Fame. Listing them all is beyond this article’s scope. These three achievements demonstrate the shift from simple approaches like keyword spotting and reliance on handcrafted rules. Modern software can understand the meaning of words or phrases based on context and take fewer steps to define “where to look” to complete an NLP task faster.
How about looking at a bigger picture on how NLP research is evolving?
Alexander Konduforov highlights an almost complete shift from recurrent and convolutional architectures for deep learning models to transformer-based ones: “Transfer learning and language models are predominant approaches nowadays, and for most of the NLP tasks, they show a drastic victory over non-deep learning models and classic RNN/CNN networks.”
Transformers, which entered the game in 2017, will be pushing model performance boundaries: “Transformer-based language models rely on a huge corpus of texts, and recent papers show that simply scaling up the size of a BERT-like architecture and feeding it more data allows us to increase the performance even more, so the capacity is yet to be reached,” adds Alexander.
On the other hand, there are also trends for the minimization of NLP models. Knowledge distillation is one of the approaches for computer vision that was recently adopted in NLP. In April 2020, researchers from Google Brain and Carnegie Mellon University introduced a thin version of BERT – MobileBERT – that can be deployed on (guess what?) mobile devices.
What future techniques and approaches will the NLP community invent in the next year? We’ll have to wait and see.
Contributor
Thanks to AltexSoft, our contributor for this post.
AltexSoft is a technology consulting firm that helps businesses build custom software and handle transformational products in the travel and other industries. Their data science unit covers both machine learning and data engineering. You can visit the AltexSoft blog for more useful content.




{kind=link}