Deep Learning
NVIDIA cuDNN 7.4: New Deep Learning Software Release
November 19, 2018
4 min read


The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks. cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN is part of the NVIDIA Deep Learning SDK.
Deep learning researchers and framework developers worldwide rely on cuDNN for high-performance GPU acceleration. It allows them to focus on training neural networks and developing software applications rather than spending time on low-level GPU performance tuning. cuDNN accelerates widely used deep learning frameworks, including Caffe,Caffe2, Chainer, Keras,MATLAB, MxNet, TensorFlow, and PyTorch. For access to NVIDIA optimized deep learning framework containers, that has cuDNN integrated into the frameworks, visit NVIDIA GPU CLOUD to learn more and get started.
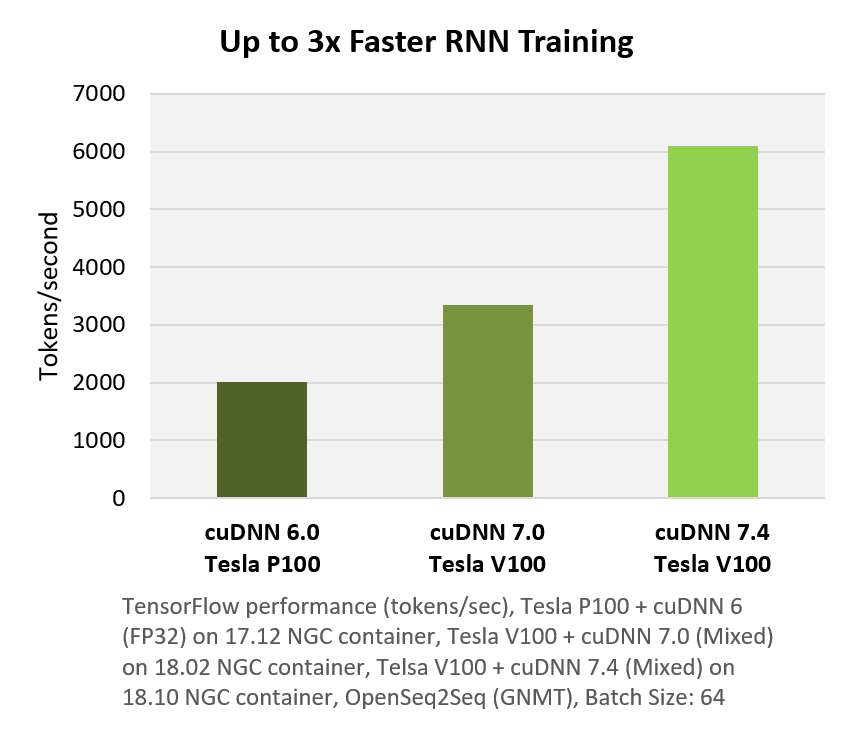
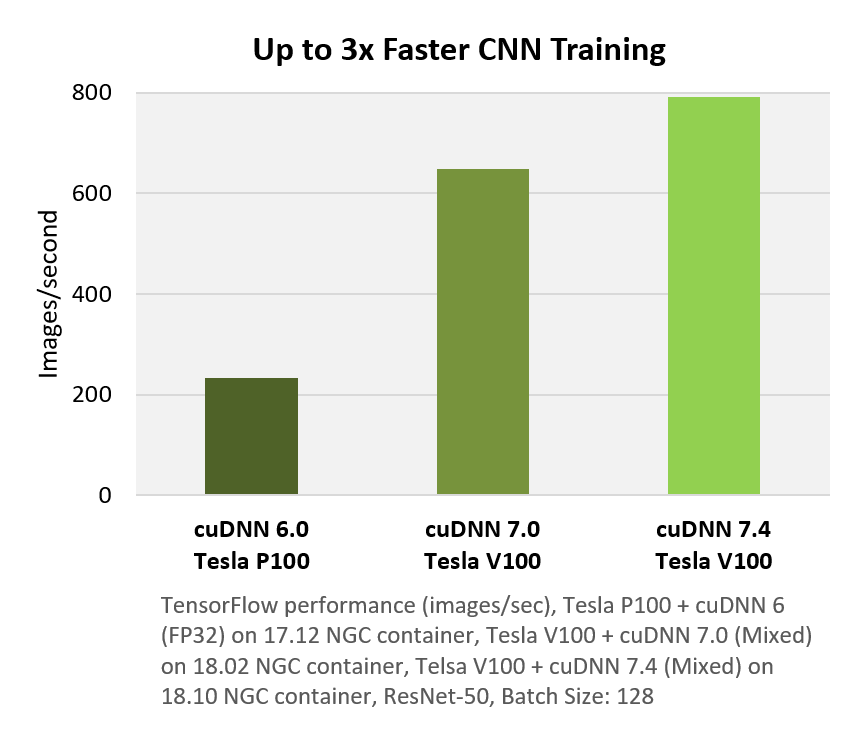
cuDNN is supported on Windows, Linux and MacOS systems with Volta, Pascal, Kepler, Maxwell Tegra K1, Tegra X1 and Tegra X2 and Jetson Xavier GPUs.

Have any questions? Contact us directly here.

The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks. cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN is part of the NVIDIA Deep Learning SDK.
Deep learning researchers and framework developers worldwide rely on cuDNN for high-performance GPU acceleration. It allows them to focus on training neural networks and developing software applications rather than spending time on low-level GPU performance tuning. cuDNN accelerates widely used deep learning frameworks, including Caffe,Caffe2, Chainer, Keras,MATLAB, MxNet, TensorFlow, and PyTorch. For access to NVIDIA optimized deep learning framework containers, that has cuDNN integrated into the frameworks, visit NVIDIA GPU CLOUD to learn more and get started.
cuDNN is supported on Windows, Linux and MacOS systems with Volta, Pascal, Kepler, Maxwell Tegra K1, Tegra X1 and Tegra X2 and Jetson Xavier GPUs.
Have any questions? Contact us directly here.



