HPC
Discover the Difference Between Deep Learning Training and Inference
August 10, 2017
7 min read

.jpg?format=webp)
.jpg)
To first understand the difference between deep learning training and inference, let's take a look at the deep learning field itself. While deep learning can be defined in many ways, a very simple definition would be that it's a branch of machine learning in which the models (typically neural networks) are graphed like "deep" structures with multiple layers. Deep learning is used to learn features & patterns that best represent data. It works in a hierarchical way: the top layers learn high-level generic features such as edges, and the low-level layers learn more data specific features. The process of deep learning can be applied to various applications including image classification, text classification, speech recognition, and predicting time series data.
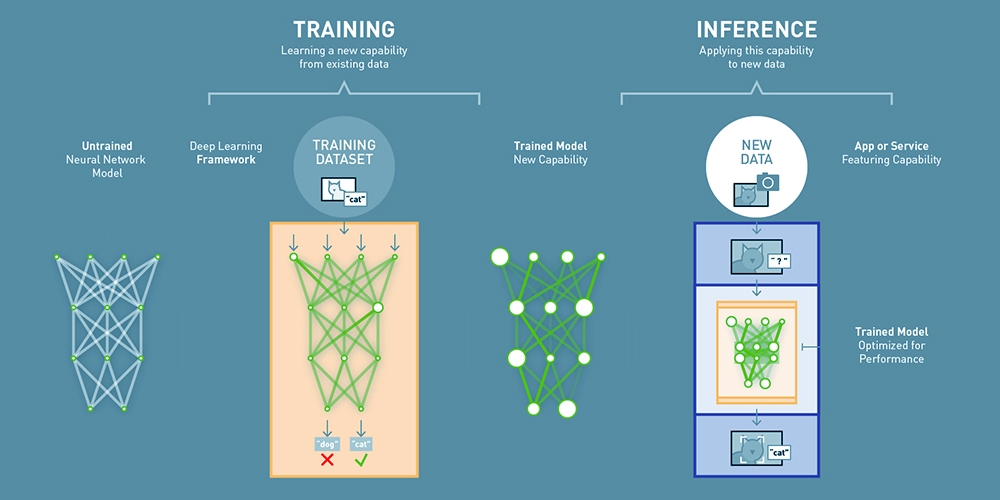
Training is the phase in which your network tries to learn from the data. In training, each layer of data is assigned some random weights and your classifier runs a forward pass through the data, predicting the class labels and scores using those weights. The class scores are then compared against the actual labels and an error is computed via a loss function. This error is then backpropagated through the network and weights are updated accordingly via some weight update algorithm such as Gradient Descent. One complete pass through all of the training samples is called an epoch. This is computationally very expensive as we only perform a single weight update after going through every sample. So, in practice, we divide the data into batches and update weights after each batch. This method takes less time to converge, and hence, we need fewer epochs to run.
Training can be sped up by using a GPU (or multiple GPUs in parallel) as they're much faster compared to CPUs for vector and matrix manipulations. For example, we had a customer using an NVIDIA GeForce GTX 1080 Ti and an Intel Core i7-5930K processor on our Spectrum TXN003-0128N Deep Learning Development Workstation, and they noticed a huge difference in performance. They noted the time taken per epoch can be reduced from 3-4 minutes (on CPU) to just 3-4 seconds when switching to the GPU for a relatively less complex (20 layers) network training on a small dataset (15 classes and roughly 100 samples per class).

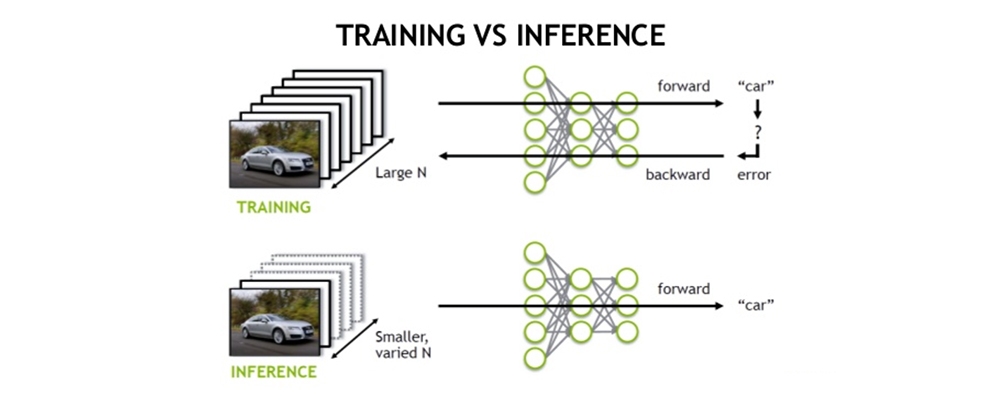
The inference is the stage in which a trained model is used to infer/predict the testing samples and comprises of a similar forward pass as training to predict the values. Unlike training, it doesn't include a backward pass to compute the error and update weights. It's usually a production phase where you deploy your model to predict real-world data. You can use a GPU to speed up your predictions, with the most common and ideal choice for deep learning being the NVIDIA Tesla series. Batch prediction is way more efficient than predicting a single image so you may like to stack up multiple samples before and then predicting in a single go. This is the ideal solution for enterprises if you have a lot of users and get hundreds of hits per second. Latency can be an issue if you don't have a lot of users and stacking up images(for a fixed batch size) might take a lot of time itself.
Deep learning requires a lot of data for training, and if you're working on a niche problem, collecting data can be a big challenge. One solution to this problem is transfer learning where you use pre-trained models on other datasets and instead of initializing layer weights randomly (as you do before training a model from scratch), you use the learned weights (from the pre-trained model) for each layer and then further train the model on your data. Your model has a better chance to converge even if you have a small data set. Transfer learning can take the following forms:
To first understand the difference between deep learning training and inference, let's take a look at the deep learning field itself. While deep learning can be defined in many ways, a very simple definition would be that it's a branch of machine learning in which the models (typically neural networks) are graphed like "deep" structures with multiple layers. Deep learning is used to learn features & patterns that best represent data. It works in a hierarchical way: the top layers learn high-level generic features such as edges, and the low-level layers learn more data specific features. The process of deep learning can be applied to various applications including image classification, text classification, speech recognition, and predicting time series data.
Training is the phase in which your network tries to learn from the data. In training, each layer of data is assigned some random weights and your classifier runs a forward pass through the data, predicting the class labels and scores using those weights. The class scores are then compared against the actual labels and an error is computed via a loss function. This error is then backpropagated through the network and weights are updated accordingly via some weight update algorithm such as Gradient Descent. One complete pass through all of the training samples is called an epoch. This is computationally very expensive as we only perform a single weight update after going through every sample. So, in practice, we divide the data into batches and update weights after each batch. This method takes less time to converge, and hence, we need fewer epochs to run.
Training can be sped up by using a GPU (or multiple GPUs in parallel) as they're much faster compared to CPUs for vector and matrix manipulations. For example, we had a customer using an NVIDIA GeForce GTX 1080 Ti and an Intel Core i7-5930K processor on our Spectrum TXN003-0128N Deep Learning Development Workstation, and they noticed a huge difference in performance. They noted the time taken per epoch can be reduced from 3-4 minutes (on CPU) to just 3-4 seconds when switching to the GPU for a relatively less complex (20 layers) network training on a small dataset (15 classes and roughly 100 samples per class).
The inference is the stage in which a trained model is used to infer/predict the testing samples and comprises of a similar forward pass as training to predict the values. Unlike training, it doesn't include a backward pass to compute the error and update weights. It's usually a production phase where you deploy your model to predict real-world data. You can use a GPU to speed up your predictions, with the most common and ideal choice for deep learning being the NVIDIA Tesla series. Batch prediction is way more efficient than predicting a single image so you may like to stack up multiple samples before and then predicting in a single go. This is the ideal solution for enterprises if you have a lot of users and get hundreds of hits per second. Latency can be an issue if you don't have a lot of users and stacking up images(for a fixed batch size) might take a lot of time itself.
Deep learning requires a lot of data for training, and if you're working on a niche problem, collecting data can be a big challenge. One solution to this problem is transfer learning where you use pre-trained models on other datasets and instead of initializing layer weights randomly (as you do before training a model from scratch), you use the learned weights (from the pre-trained model) for each layer and then further train the model on your data. Your model has a better chance to converge even if you have a small data set. Transfer learning can take the following forms:



