

High Performance Hardware
From NVIDIA RTX to NVIDIA H100s, Exxact Inference Solutions meet your most demanding deep learning inference tasks.
Low-Latency Throughput
Exxact Deep Learning Inference Servers enable high-speed real-time use cases for multi-inference queries such as text-to-speech, NLP, and more.
Pre-Installed Frameworks
Our systems come pre-loaded with TensorFlow, PyTorch, Keras, Caffe, RAPIDS, Docker, Anaconda, MXnet, and more upon request.
Suggested Exxact Deep Learning Inference Data Center Systems



Suggested Exxact Deep Learning Inference Edge Systems

4x GPU 2x Intel Xeon Scalable 2U EdgeServer
Highlights
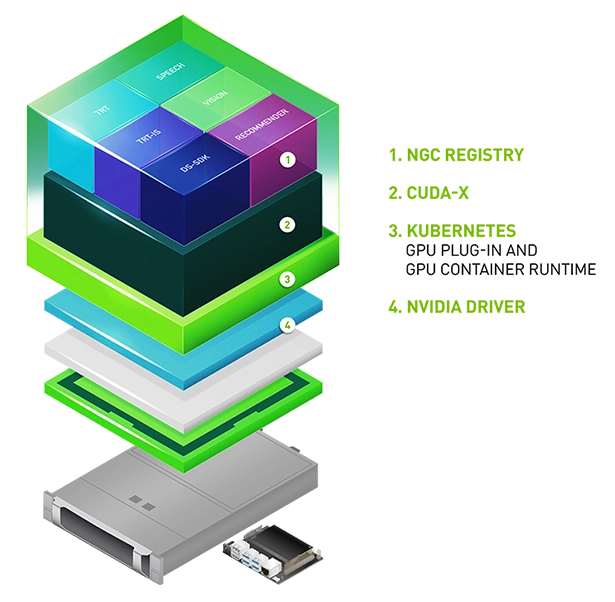
Enterprise-Grade Software Stack for the Edge
NVIDIA Edge Stack is an optimized software stack that includes NVIDIA drivers, a CUDA® Kubernetes plug-in, a CUDA Docker container runtime, CUDA-X libraries, and containerized AI frameworks and applications, including NVIDIA TensorRT™, TensorRT Inference Server, and DeepStream.
NVIDIA TensorRT Hyperscale Inference Platform
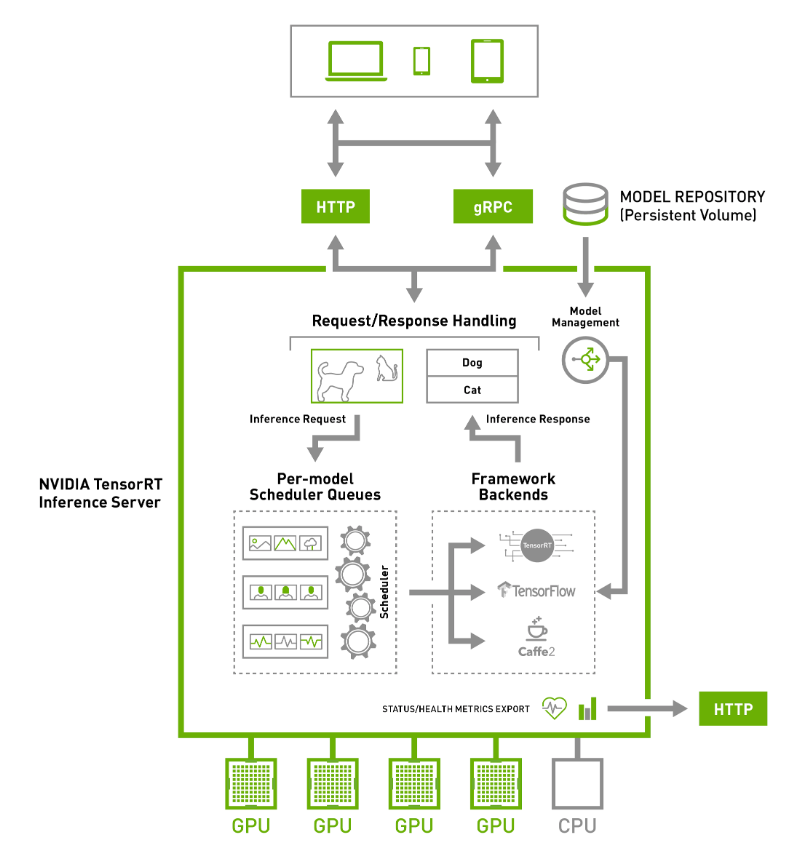
The NVIDIA TensorRT™ Inference Platform is designed to make deep learning accessible to every developer and data scientist anywhere in the world. NVIDIA Data Center GPUs accelerate deep neural networks for images, speech, translation, and recommendation systems with a wide variety of frameworks, including TensorFlow, PyTorch, ONNX, XGBoost, JAX, or even custom frameworks.
NVIDIA TensorRT optimizer and runtime unlock the power of NVIDIA GPUs across a wide range of precision, from FP32 down to INT4 and now FP8. NVIDIA TensorRT Inference Servers are production-ready deep learning inference servers. Reduce costs by maximizing the utilization of GPU servers and save time with seamless integration in your infrastructure.
For large-scale, multi-node deployments, Run.ai – a Kubernetes-based scheduler – enables enterprises to scale up training and inference deployments to multi-GPU clusters seamlessly, It allows software developers and DevOps engineers to automate deployment, maintenance, scheduling, and operation. Build and deploy GPU-accelerated deep learning training or inference applications to heterogeneous GPU clusters and scale with ease. Contact us for more info about Run.ai.
Build your ideal system
Need a bit of help? Contact our sales engineers directly.
Use Cases for Inference Solutions

Data Center

Self Driving Cars

Intelligent Video Analytics
